本文主要介绍了制表符在文本和Stata中的表现,包括其在不同情境下的使用和转换。文章通过实例解释了制表符的特性及其在Stata中的导入和处理方式。
制表符分为水平制表符和垂直制表符,主要用于在文本中定位光标,方便编辑。水平制表符在终端和文件中的输出相当于按下键盘TAB键效果。
使用file命令导入制表符时,其可能变为n个连续的空格。使用fileread()函数或infix导入时,制表符的处理方式有所不同。infix读入后会自动将每一行开头和结尾的空格删除,而制表符位于字符串之间时,导入后可能变为不同数量的空格。
可以使用元字符“ ”将水平制表符替换为其他字符,如“X”。同时,介绍了使用infix导入后制表符的处理方式以及如何用替换操作处理导入后的空格。
有问题,不要怕!点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱
[email protected]
,
我们会及时为您解答哟~
ps:(1)爬虫俱乐部将于2018年1月20日至28日在武汉举行两期Stata编程技术定制培训。详情请戳《
爬虫俱乐部Stata编程技术定制培训班——2018年1月武汉专场
》
(2)喜大普奔,爬虫俱乐部的
github
主站正式上线了!我们的网站地址是:
https://stata-club.github.io
,粉丝们可以通过该网站访问过去的推文哟~
元字符大致可以分为两种:一种是用来匹配文本的(比如
“
.
”
),另一种是正则表达式的语法所要求的(比如
“[ ]"
)。在进行正则表达式搜索的时候,我们经常会遇到需要对原始文本里的空白字符进行匹配的情况。比如说,我们可能需要把所有的
制表符
找出来,或者我们需要把
换行符
找出来,这类字符很难被直接输入到一个正则表达式里,但我们可以使用下表列出的
特殊元字符
来输入它们。

之前的推文中,我们多次提到
“\s”
是一个特殊元字符,可以匹配
空白字符
,即上表中所示的所有字符,那既然有了
“\s”
这个“
多功能
”的“空白元字符”,为什么还需要\n、\r、\t之类的呢?设想一下,你在统计词频时,文本中的某个词可能由于分行,从而导致无法匹配到,此时你需要删除文本中的换行符和回车符,使不同行之间的内容连接在一起,当然
\s
也包括了换行符和回车符,但是为什么不能用其将换行、回车删掉呢?原因是
\s
也能匹配制表符或空格,而有些制表符或空格是不能删除的,例如表格中两个单元格之间的空格如果我们删除了,那么单元格之间的内容就连在了一起,这在推文《
用正则表达式揭开回车键的面纱
》中进行了详细说明。
本篇推文重点介绍一下
制表符。
制表符分为两种:水平制表符(
\t
)和垂直制表符(
\v
)。
垂直制表符(
\v
)不常用,它的作用是让
\v
后面的字符从下一行开始输出,且开始的列数为
\v
前一个字符所在列的后面一列,我们这里主要介绍一下水平制表符,一般来说,其在终端和文件中的输出显示相当于按下键盘TAB键效果。Windows系统中,显示水平制表符占8列(即8个字节)。同时水平制表符开始占据的初始位置是第8*n列(第一列的下标为0)。那么制表符导入到Stata中,究竟是什么呢?
我们首先用file命令,生成一个名为“temp”的txt文件:
tempname temp
file open `temp' using temp.txt, text write replace
file write `temp' `"`=char(9)'爬虫俱乐部"' _n
file write `temp' `"将爬虫进行到底`=char(9)'"' _n
file close `temp'
shellout temp.txt
//打开temp.txt文件

首先,我们用file命令在第一行“爬虫俱乐部”前读入一个`=char(9)',即水平制表符,同样在第二行“将爬虫进行到底”后读入一个水平制表符。但是注意到,第一行的制表符占了8列(即8个字节,对应下行“将爬虫进”四个汉字,1个汉字在ASCII编码中占2个字节),而输入到第二行的制表符,却只占了2个字节(图中蓝色部分,对应上行一个汉字“乐”),这是为什么呢?
Tab键有这样的特征:每按一次,光标就自动定位到下一个制表符的位置,而且在一个制表符宽度范围内,增加或者删除文字不会影响下一制表符中的文字位置。
因此,不管光标处于什么位置,按一下tab键,光标就会自动定位到下一个制表符的位置,而这个位置的列数,一定是8的整数倍。所以,虽然在文本中的两行均读入一个水平制表符,第一个占了8列,而第二个制表符因为前边的字符占了14列,下一个制表符的位置为第16列,因此其只占2列。这就是为什么有时候我们在文档中的不同位置敲击Tab键,长度不一样的原因。
制表符导入到Stata中,一定还是制表符本身吗?答案是否定的,其还可能变为n个连续的空格。例如:用fileread()函数或import delimited导入Stata后,其还是制表符本身,但是用infix读入Stata后,制表符就变成n个连续的空格(为什么是n个,而不是确定的个数呢?),下边我们以两个简单的例子加以说明:
fileread()函数将temp.txt导入Stata
clear
set more off
set obs 1
gen v = fileread("temp.txt")
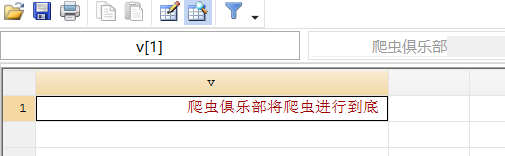
接着,我们用元字符
“\t”
将水平制表符替换为
“X”
:
replace v = ustrregexra(v,"\t","X")

infix str50 v 1-200 using temp.txt,clear
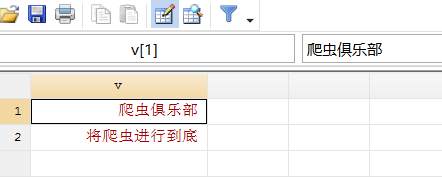
同样,我们用元字符
“\t”
将水平制表符替换为“X”:
replace v = ustrregexra(v,"\t","X")
list
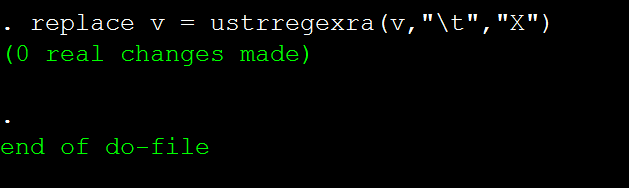
可以看到,用infix将temp.txt导入Stata后,制表符是不存在的,那么是不是变成了我们前边所说的n个空格呢?我们接着进行替换:
replace v = ustrregexra(v," ","X")
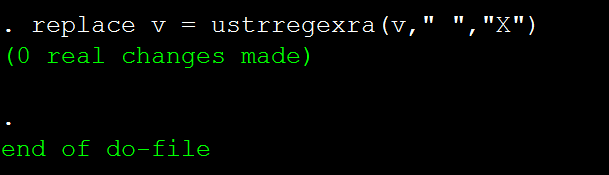
同样,没有进行替换。原因是,用infix读入文本文档,其中的制表符会变为4个连续的空格,并且infix读入后会自动将每一行开头和结尾的空格删除掉,因为本例中的制表符均在两行的首尾处,因此被删除掉了。如果,Tab键位于字符串之间,导入Stata后就会变味n个连续的空格,例如:
tempname temp
file open `temp' using temp.txt, text write replace
file write `temp' `"`=char(9)'爬虫俱乐部`=char(9)'将爬虫`=char(9)'进行到底"' _n
file close `temp'
shellout temp.txt

可以看到,temp.txt文档中有3个制表符,其中一个位于字符串的开头,另外两个位于字符串之间,接着将该文本文档导入stata,并用空格(" ")将水平制表符替换为“X”
infix str25 v 1-200 using temp.txt,clear
replace v = ustrregexra(v," ","X")
compress
list
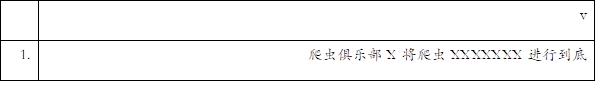
显然,处于字符串开头位置的制表符没有发生替换
,而处于字符串之间的制表符用
infix
导入到stata之后,不同位置对应的空格数量也是不相同的,这是为什么呢?我们知道,制表符占的列数(即字节数)一定是8的整数倍,位于字符串“爬虫俱乐部”之后的制表符,其前边的字符串,即“爬虫俱乐部”已经占了15个字节的长度(笔者使用的是Stata15版本,每一个汉字占3个字节)。
因此其后的制表符应该占一个字节的位置,所以对应了一个空格,相应的替换为一个X;而位于字符串“将爬虫”之后的制表符,其前边的字符串“爬虫俱乐部X将爬虫”一共占了25个字节(8个汉字加上一个大写英文字母),因此这个制表符应该占7个字节的长度(32-25),对应7个空格,相应的被替换为7个“X”。
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~











