未来AI发展的必然趋势是什么?必然是
多模态深度学习
。它不仅是当前人工智能领域的热门研究方向之一,也是学术界和工业界共同关注的重点,值得长期投入。
当然,这方向仍存在大量开放性问题,但对论文er来说也意味着更多的创新空间,推荐还没有idea的同学尝试。目前多模态深度学可考虑的热点研究方向有4个:
多模态大模型
(比如最近爆火的DeepSeek-R1的多模态版Align-Anything)、
跨模态生成、低资源多模态学习、多模态因果推理
。
为方便大家研究的进行,我这边整理好了
98篇
多模态深度学习最新论文
,每个方向都有参考(附代码),不想多花时间找论文的同学可以直接拿~
扫码
添加小享,
回复“
多模态深度
”
免费获取
全部论文+代码合集

多模态大模型:
如GPT-4V、LLaVA等结合语言模型与视觉理解的系统。
Reconstructive Visual Instruction Tuning
ICLR 2025
方法:
论文介绍了一种多模态大模型的训练方法,名为ROSS,通过视觉中心重构目标对视觉输出进行监督,解决了视觉信号空间冗余问题,并采用去噪目标增强了模型的细粒度理解能力和减少幻觉现象,显著提升了视觉编码器和语言模型的性能。
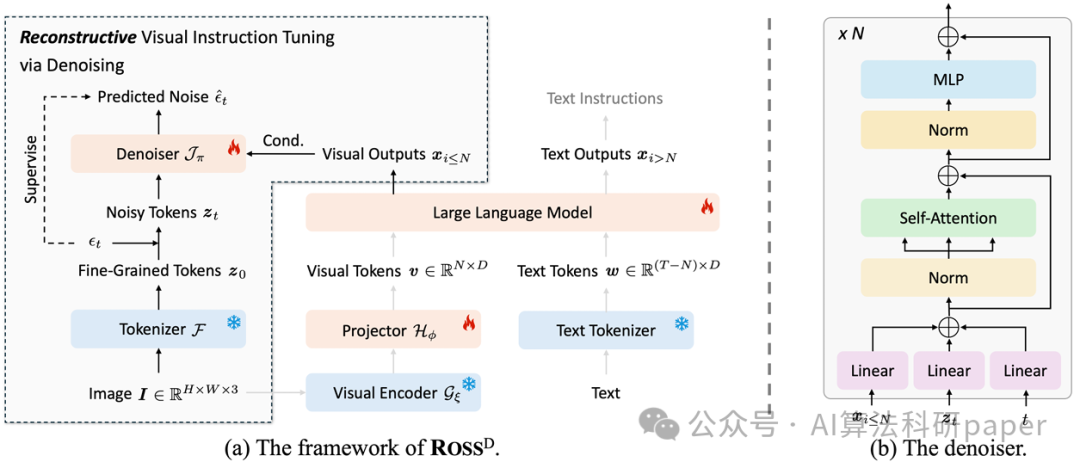
创新点:
-
ROSS通过视觉中心的重构目标来监督视觉输出,区别于传统的仅监督文本输出的方法。
-
为解决自然图像视觉信号的空间冗余问题,ROSS引入了一种去噪目标,重构输入图像的潜在表示,避免直接回归原始RGB值。
-
通过设计内在的视觉重构监督,ROSS在使用单一视觉编码器(例如SigLIP)时,仍能保留输入图像的每个细节。

跨模态生成:
文本生成图像(Stable Diffusion)、视频生成文本描述等。
Cross-Modal Contextualized Diffusion Models for Text-Guided Visual Generation and Editing
ICLR 2024
方法:
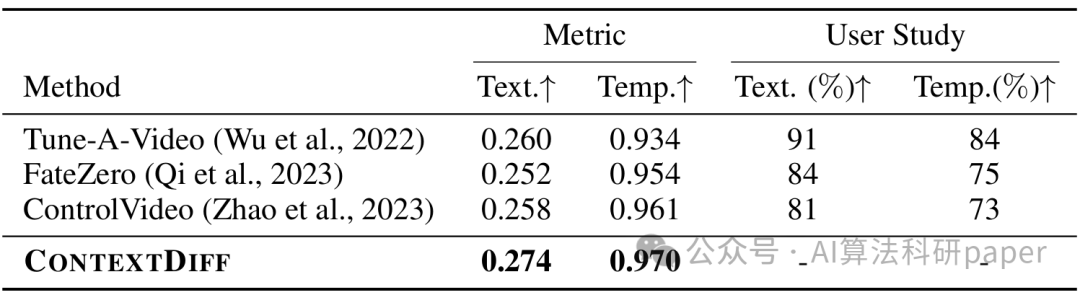
本文提出了一种新颖且通用的条件扩散模型(CONTEXTDIFF),通过在扩散和逆过程的所有时间步中传播跨模态上下文来适应其轨迹,以增强模型的跨模态合成能力。这种方法在文本到图像和文本到视频的任务中都取得了更好的效果。
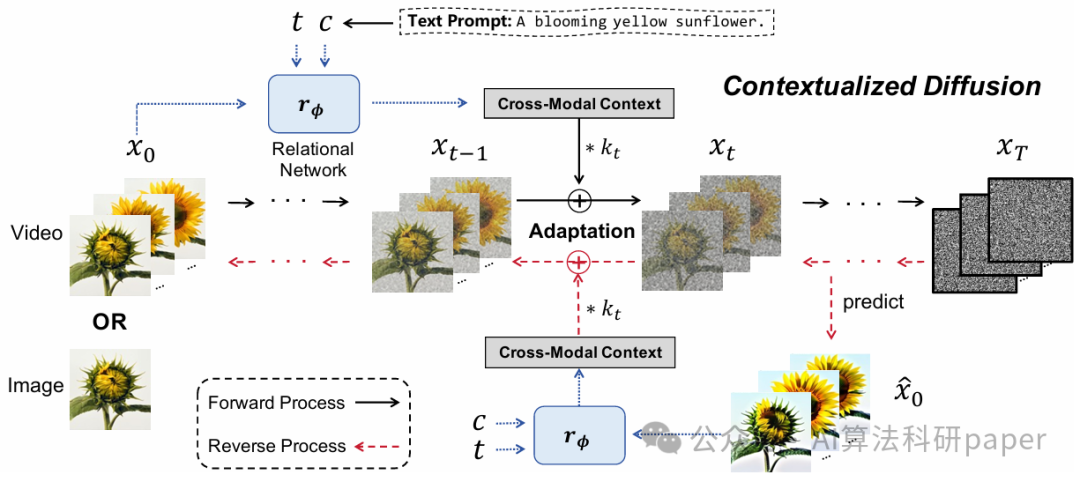
创新点:
-
提出了一种新颖的上下文化扩散模型 (CONTEXTDIFF),首次将跨模态上下文(文本条件与视觉样本之间的交互和对齐)引入到正向和反向扩散过程中。
-
设计了一个上下文感知轨迹适配器,将其应用于扩散过程的所有时间步,并将其推广到DDPMs和DDIMs。
扫码
添加小享,
回复“
多模态深度