本文内容来自CDA网易云课堂:
R语言数据挖掘与商业分析建模(常国珍)
课程,数据及源代码下载请加QQ群:426889479
作者:常国珍、吕鸿福
概述
:本文基于
R语言,通过一个
逻辑回归构建汽车贷款申请信用评级
的案例,来为大家简单介绍信用风险模型及建模流程、
R语言实现、及中间需要注意的一些问题。包含的主要内容有以下几部分:
l
信用风险模型简述
l
信用评分模型建模流程
/框架
l
基于
R语言的汽车贷款申请信用评级案例实现(代码)
Part
1
:信用风险模型简述
说到信用风险模型,
常见的
有下面三种:
n
A
pplication(申请评分)模型
Ø
通过客户申请时的信息,预测客户将来发生违约
/逾期等的统计概率
Ø
多用于信用产品的申请审批、及初始额度的判定
n
Behavior(行为评分)模型
Ø
通过现有客户过往行为表现,预测客户在接下来一段时间发生违约
/逾期等的统计概率
Ø
多用于信用产品的额度调整等
n
Collection(催收评分)模型
Ø
通过已经逾期客户过往行为表现,预测已逾期客户清偿欠款
/逾期恶化的统计概率
Ø
多用于进行选择客户催收
下面为大家介绍一个场景,想必大家非常熟悉:
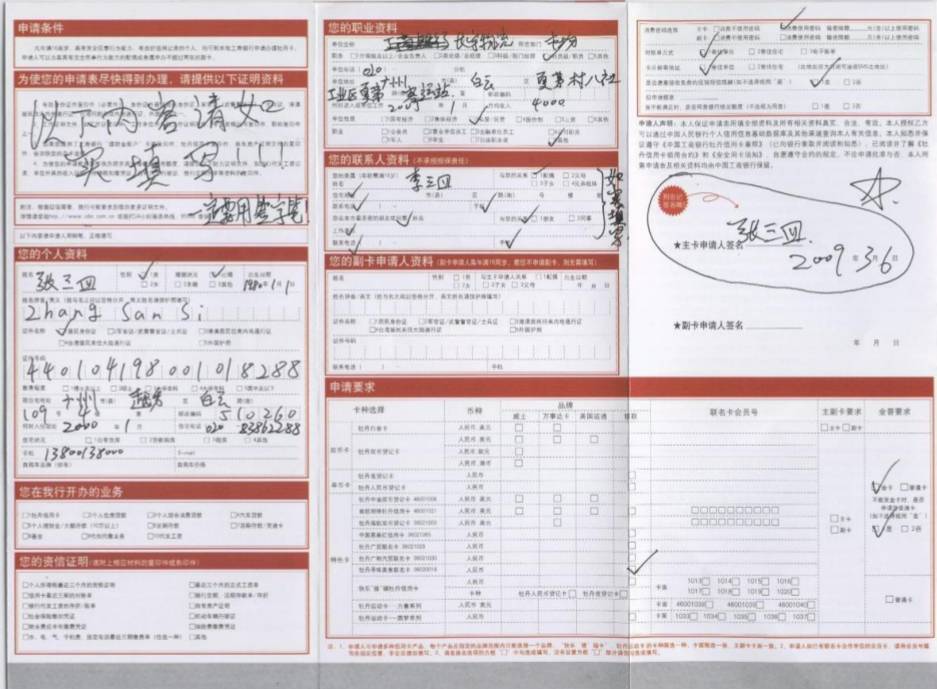
图
1. 银行信用卡申请表单
没错,这就是大家在申请银行信用卡时,需要填写的表单。这里面,我们填写的多数信息,会作为银行申请评分模型的变量,从而决定银行是否给我们发放信用卡以及信用卡的额度。大家可以体会信用风险模型在实际生活、工作中的应用场景。
本次
汽车贷款申请信用评级案例
,主要涉及
Application(申请评分)模型,通过汽车贷款客户申请时的信息预测其将来发生违约/逾期等的概率,从而决定是否发放其贷款。本案例中,我们构建申请信用评级模型的数据变量如下:
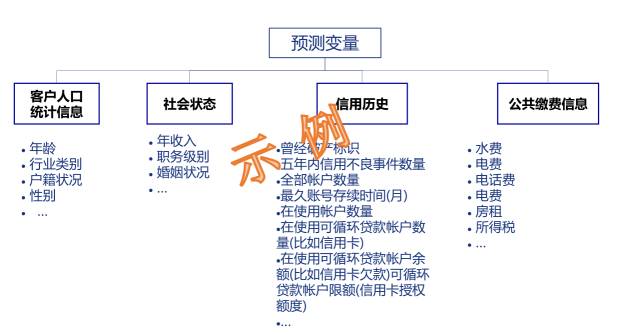
图
2. 汽车贷款申请信用评级案例变量
Part
2
:信用评分模型建模流程
/框架
数据分析建模流程,是在实际工作中保证模型质量的重要手段,属于工艺的范畴,没有标准答案,只有业界领先经验。还有很多需要结合业务建模的特点进行调整。
下面给出一个比较通用的建模流程:


该流程总体可以分为五部分:建模准备
→变量初筛→变量清洗→变量细筛与变量水平压缩→建模与实施,包含了从收集数据到模型建立及实施的全流程。下一部分我们通过
汽车贷款申请信用评级案例
,为大家介绍如何走通本流程,及如何利用
R语言进行信用风险建模实战。
Part
3
:基于
R语言的汽车贷款申请信用评级案例实现(含代码)
这一部分,我们把程序通过截图的方式分享给大家,这里面我们会给出代码的
详细含义解释(注释内容)
,篇幅限制不再贴出程序具体的运行结果,感兴趣的童鞋可以加群索要源代码运行。

图
3.1 数据变量说明
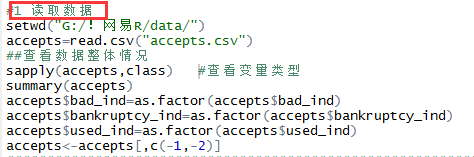
图
3.2 读入数据
![]()
图
3.3 利用随机森林进行变量粗筛
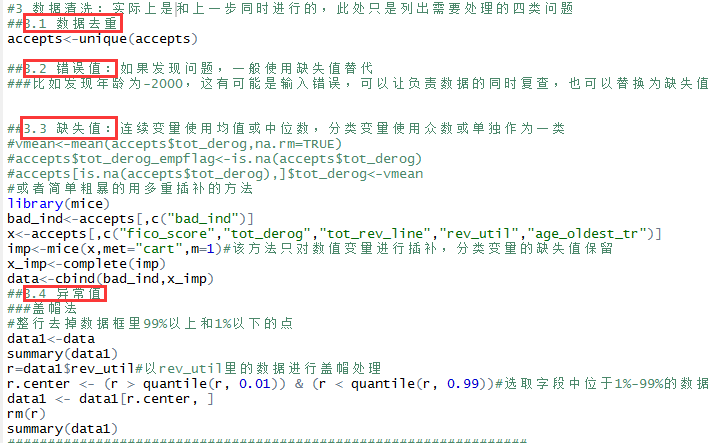 图
3.4 数据清洗(去重、错误值、缺失值、异常值)
图
3.4 数据清洗(去重、错误值、缺失值、异常值)
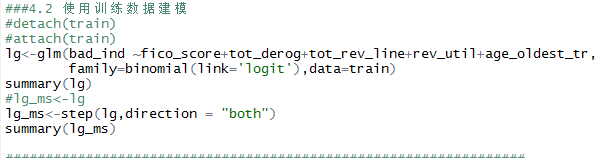 图
3.5 建立模型
图
3.5 建立模型

图
3.6 模型检验及评估
这里需要注意,我们省去了变量细筛的环节,是因为我们在模型粗筛环节只挑选出
5个最重要的变量进行建模;如若,在粗筛环节选择较多的变量,我们在下面流程可以进行变量细筛,如根据KS及IV值进行变量选择。
本次我们先分享到这里,希望对大家有帮助,也欢迎大家批评指正。
[参考资料:
Credit risk scorecards-developing and implementing
intelligent credit scoring, Naeem Siddiqi
]





