
作者:刘顺祥
个人微信公众号:每天进步一点点2015
前文传送门:
从零开始学Python数据分析【1】--数据类型及结构
从零开始学Python数据分析【2】-- 数值计算及正则表达式
从零开始学Python数据分析【3】-- 控制流与自定义函数
从零开始学Python数据分析【4】-- numpy
从零开始学Python数据分析【5】-- pandas(序列部分)
作为从事数据相关工作的我们,平时接触的更多的是一张有板有眼的数据表格,在这里我们就叫作数据框。在Python中可以通过pandas模块的DataFrame函数构造数据框,而R语言则是data.frame创建数据框。接下来我们将对比Python和R语言如下几个方面的应用:
1、数据框的构造
在Python中,可以借助于列表、元组、字典进行手工构建数据框,我们用例子说明:
通过列表创建数据框

发现,这样创建数据框的话,没有变量名称。该如何创建的时候加上列名称呢?

是的,可以运用DataFrame函数中的columns参数给数据框的每列添加名称,如果你需要给行加上索引名称,你可以使用index参数。
通过字典创建数据框
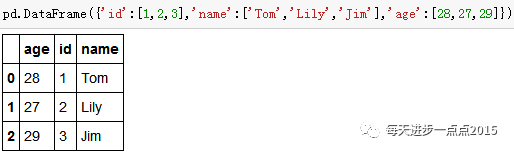
发现输出结果中列名称顺序与构造时的数据不一致,这是因为字典并非是一种序列,而是一种特殊的键值对关系的对象。如果你需要按照指定的列顺序排列,仍然可以通过columns参数实现。
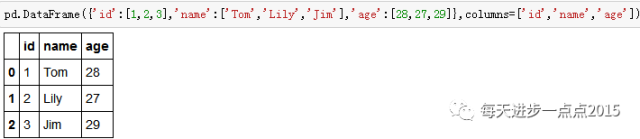
在R语言中,构造数据框的方法就相对单一一些了,只需要往data.frame函数传入向量对象即可。

2、数据的读入
在更多的场景下我们是读取外部数据,然后基于外部数据进行数据分析、可视化、数据挖掘等研究。这里跟大家介绍一下文本文件、电子表格和MySQL数据库的读取。
文本文件的读取
在pandas模块中有read_table和read_csv两个函数读取常见的文本文件,这里就以txt和csv文件为例,对比Python和R语言的读取。

read_table和read_csv两个函数都可以读文本文件数据,区别在于默认的sep参数不一致,read_table默认以制表符Tab键为字段间的间隔符,而read_csv默认以逗号为字段间的间隔符。
由于原始数据文件books.txt没有字段名称,故设置header=None,并用names参数给表字段加上名称,usecols则是设置读取原始数据的哪些列。下面再来看看使用read_table函数读取csv文件。

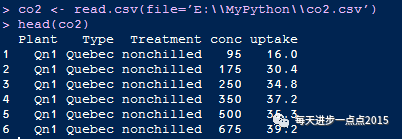
在R语言中,也有两个常用的函数read.table和read.csv函数读取txt和csv文件,不妨就用read.csv函数读取上面的co2.csv数据集:
电子表格的读取
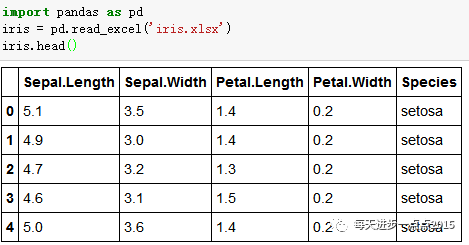
pandas模块中read_excel函数可以非常方便的读取外部的xls和xlsx电子表格:
在R语言中,基础包就无法读取电子表格数据了,这里强烈推荐R的用户使用readxl包读取Excel文件。但需要注意的一点是,数据的路径一定不能包含中文,连文件名称也不可以。

MySQL数据库数据的读取
使用Python读取MySQL数据库,还需要结合pymysql模块一起使用。这里我们就在本地的MySQL创建一个数据集,并用Python和R实现数据库数据的读取。
在MySQL中创建数据
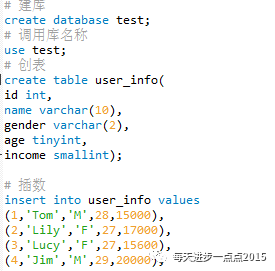
运用Python与MySQL创建连接,并读取数据;
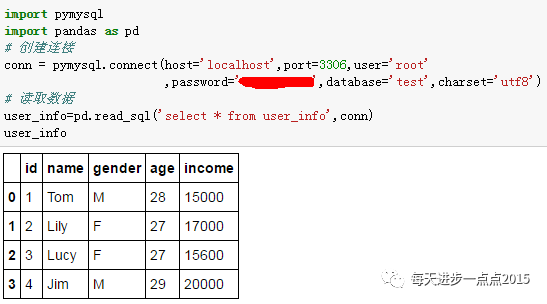
运用R与MySQL创建连接,并读取数据(需要下载RMySQL包);

3、数据的概览信息
外部数据读取到Python或R语言中,往往对数据需要做一些大概的了解,如最小值、最大值、平均值、各变量都是哪些数据类型、数据量如何等。我们来看看这些问题是如何解决的:

shape属性和columns属性返回数据集的行列数及变量名;
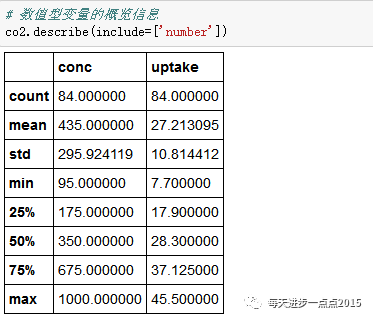
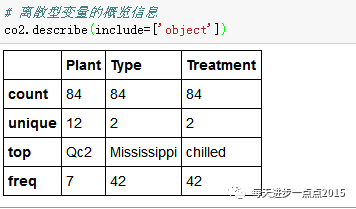
describe属性可以对数值型变量(include=['number'])和离散型变量(include=['object'])进行描述性统计;
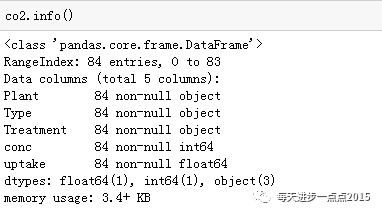
info属性则对数据集的变量类型进行简单的描述。
在R语言中,上面关于数据的概览信息,可以对应到如下的代码:

dim函数和names函数;
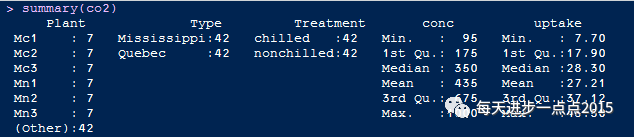
summary函数进行统计描述;

str函数对数据集的变量类型进行描述。
今天我们的内容就介绍到这边,欢迎大家拍砖。下期我们来聊聊pandas模块的数据框DataFrame第二部分。主要涉及变量、观测的筛选;变量的重命名;数据类型的变换;排序和数据集的去重。

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
1.崔老师爬虫实战案例免费学习视频。
2.丘老师数据科学入门指导免费学习视频。
3.陈老师数据分析报告制作免费学习视频。
4.玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
5.丘老师Python网络爬虫实战免费学习视频。











