暑期Stata培训班招生啦!!!
接力线上的网课培训,我们在今夏又开始新一轮的线下培训啦!
8月4日至12日
,爬虫俱乐部期待与您的相遇!培训具体内容详见推文《
暑期Stata编程技术定制培训班
》。
有问题,不要怕!点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱[email protected],我们会及时为您解答哟~
喜大普奔~爬虫俱乐部的github主站正式上线了!我们的网站地址是:
https://stata-club.github.io
,粉丝们可以通过该网站访问过去的推文哟~
好消息
:爬虫俱乐部隆重推出数据定制及处理业务啦,您有任何网页数据获取及处理方面的难题,请发邮件至我们邮箱
[email protected]
,届时会有俱乐部资深高级会员为您排忧解难!

缘妙不可言,在于你永远无法预料,下一秒将会和谁分离,一个转身,永不相见;在于你永远无法预料,下一秒将会和谁相遇,一个眼神,为他沦陷。小编认为缘及同,这里同指的是相似一样的意思,当你和她因为缘相遇,那是因为你和她恰巧出现在同一个地方,她对你有眼缘,那也是你和她有共同的爱好,相同的遭遇,物以类聚,人以群分,接下来,小编就给大家找命中注定的有缘人——
字符串间的最长公共字符
。
何为字符串间的
最长公共字符
?千言万语不如例子,小编这就给大家举个例子,比如,我有两个字符串,一个字符串是“
abcd
”,第二个是“
bcad
”,那么它们两个公共的字符串有五个,分别是“
a
”,“
b
”,“
c
”,“
d
”,“
bc
”。它们之间最长公共字符串是“
bc
”。那么问题来了,如何用
python
代码实现这个操作呢?
假设两个字符串的长度分别为
m
和
n
。那么我们生成一个
(m+1)*(n+1)
的矩阵,如果两个字符串中
第一次出现
了相同字符,则对应矩阵位置等于
1
,如果接下来的一个字符
还相等
,则我们在原来基础上再
加一
,不相等,则不加。这里小编之所以生成
m+1
行
n+1
列的矩阵,是为了实现连续多个字符相同,使之个数相加,从而得出首个最长公共字符。
首先我们输入两个字符串
str1
和
str2
,提取它们的长度,分别为
lstr1
和
lstr2
,然后生成一个大列表,这个列表相当于上面讲的矩阵,它是由
(lstr1+1)
个
子列表
,这个子列表包含
(lst2+1)
个
零
。代码如下:
str1 = 'abcd'
str2 = 'bcad'
lstr1 = len(str1)
lstr2 = len(str2)
record = [[0 for i in range(lstr2 + 1)] for j in range(lstr1 + 1)]
print(record)
运行结果如下:
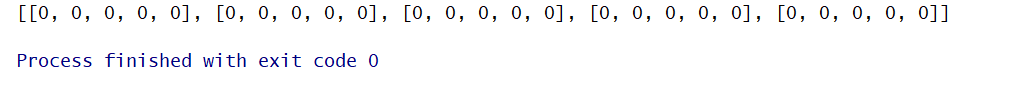
这里值得注意的是小编生成大列表,用的是两层列表生成式,先用
[0 for i in range(lstr2 + 1)]
生成
[0, 0, 0, 0, 0]
,再用一层列表生成式生成大列表。这里
record[i+1][j+1]
就代表
str1
的第
i
个字符和
str2
第
j
个字符。如果这边这里不等于零,则代表
str1
的第
i
个字符和
str2
第
j
个字符相同,反之,则不相同。可能有小伙伴不懂,没关系,后面有实例和更加详细的介绍哦!
接下来,我们把
最长匹配长度
和
匹配位置
初始化为
零
,然后从
str1
的第一个字符开始,和
str2
的每个字符进行匹配,匹配上就把对应位置等于
上个位置加一
。从而得到第一次的匹配长度
maxNUM
,从而进行循环,得到最大的匹配长度,打印出最长公共字符串和长度,代码如下:
maxNum =
0
p = 0
for i in range(lstr1):
for j in range(lstr2):
if str1[i] == str2[j]:
record[i + 1][j + 1] = record[i][j] + 1
if record[i + 1][j + 1] >maxNum:
maxNum = record[i + 1][j + 1]
p = i + 1
print(record)
print("最长公共字符串:%s" % str1[p - maxNum:p])
print("最大匹配长度: %s" % maxNum)
运行结果如下:
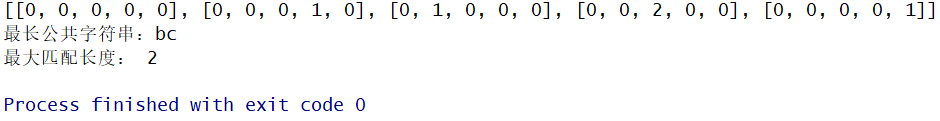
可以看出大列表已经变成了如上图所示,我们可以看到
record[i+1][j+1]
代表
str1
的第
i
个字符和
str2
第
j
个字符,如果不为零,则相同,反之则不相同,比如说
record[2][4]
的值为一,代表
str1
的第一个字符“
a
”和
str2
的第三个字符“
a
”相同,
record[3][2]
的值为一,代表
str1
的第二个字符“
b
”和
str2
的第一个字符“
b
”相同,
record[4][3]
的值为二,代表
str1
第二三位上的字符“
bc
”和
str2
第一二位上的字符“
bc
”相同。最后程序很贴心地帮我们返回了最长公共字符串和最大匹配长度。
最后我们把这个程序封装成一个方法,定义为
getNumofCommonSubstr()
.
附上所有程序:
def getNumofCommonSubstr(str1, str2):
lstr1 = len(str1)
lstr2 = len(str2)
record = [[0 for iin range(lstr2 + 1)] for j in range(lstr1 + 1)]
print(record)
maxNum = 0
p = 0
for i in range(lstr1):
for j in range(lstr2):
if str1[i] == str2[j]:
record[i + 1][j + 1] = record[i][j] + 1
if record[i + 1][j + 1] >maxNum:
maxNum = record[i + 1][j + 1]
p = i + 1
return str1[p - maxNum:p], maxNum
if __name__ == '__main__':
str1 ='abcd'
str2 = 'bcad'
res = getNumofCommonSubstr(str1, str2)
print(res)
有没有感觉很神奇呢!赶快和小编一起找出字符串中的最长公共部分吧。
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同,纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!
应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~

往期推文推荐:
1.爬虫俱乐部新版块--和我们一起学习Python
2.hello,MySQL--Stata连接MySQL数据库
3.hello,MySQL--odbcload读取MySQL数据
4.再爬俱乐部网站,推文目录大放送!
5.用Stata生成二维码—我的心思你来扫
6.
Mata中的数据导出至Excel
7.
谈谈图形中坐标设置的技巧
8.
如何输出某个关键词在字符串中的所有位置?










