大数据文摘作品,转载要求见文末
编译 | Saint, Aileen
导读:OpenAI于2017年7月17日发表新博客,表示他们的新研究成果已经创造出一些图像,确实能够从不同尺度和不同视角骗过神经网络分类器。这挑战了上周出现的“很难恶意欺骗自动驾驶汽车,因为它们可以从不同尺度,角度、视角等方面来捕捉图像“的说法)。他们的方法可以骗过各种算法,说这张有着喵星人的图并不是小猫,而是一个显示屏,一只鸵鸟或者一口大铁锅。
大数据文摘后台回复”欺骗“获得本文相关的所有论文。
这张人畜无害的小猫咪照片,由标准彩色打印机打印出来,不管如何放大缩小或翻转,都骗得神经网络分类器认为它是个显示器或台式电脑。OpenAI期待进一步的参数调试能移除图片上任何肉眼可见的人工痕迹。

这项研究似乎意在反驳上周引起讨论的一篇论文“NO Need to Worry about AdversarialExamples in Object Detection in Autonomous Vehicles“。该文中说,大多数机器学习算法易于对抗扰动,自动驾驶汽车很难被恶意欺骗,因为它们可以从不同尺度,角度、视角等方面来捕捉图像。显然,这些图片对这一说法发起了挑战。

非常规的对抗样本确实在图像转换中失效了。如下,我们将出示同样一张猫咪的照片,由ImageNet训练的第3版分类模型(Inception V3) 将其对抗摄动、错误地把图片分类为台式电脑。轻微地放大1.002倍就可能让分类器修正错误,用“虎斑猫“的标签覆盖台式电脑的对抗标签。

然而,既然已经证明对抗样本能够被迁移到物质世界(详情见论文” ADVERSARIAL EXAMPLESIN THE PHYSICAL WORLD“),我们有理由怀疑,只要积极尝试就能生成稳定的对抗样本。
我们可以通过称作投影梯度下降的优化方法来创造对抗样本,可以发现小的图像扰动能随意骗过分类器。
无须为找到一个单点对抗的输入而不断优化,我们可以集合大量的随机分类器,在分类前就调节输入比例,以此进行优化。
通过这样的集合来进行优化,可以生成稳健的尺度不变的对抗样本。
下面是一个尺度不变的对行样本。

即便我们设定约束条件,仅仅调整与这只猫咪相关的像素,我们还是可以创造出单扰动图像。同时在各种目标尺度下对抗。
通过增加随机翻转、转译、尺度、噪声,和均值漂移等训练扰动,同样的技术手段能够让单个输入在以上任意转换下保持对抗。
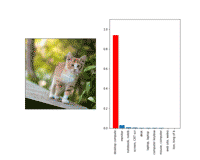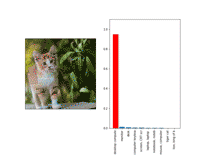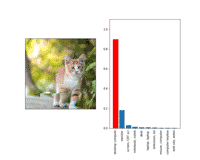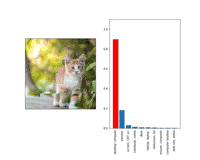
以上是一个“转换不变”的对抗样本。注意,这在视觉上比尺度不变的样本扰动更大。这可能很容易理解:直觉上来说,在一个对更多转换保持不变样本上,小的对抗扰动的变化是更难被察觉到的。
在测试的时候,OpenAI的转换是随机抽取的,这说明我们的样本对于整体的变化分布而言是不变的。
有人在Reddit提问这个方法是否适用于所有的对抗样本,比如为什么选择骗算法这张图是“显示屏”而不是什么别的物品?本文作者在Reddit说,其他的也适用,“显示屏”是我们随便选的,我们也可以轻松的骗过算法说这张图不是小猫,而是一只鸵鸟或者一口大锅…

原文地址https://blog.openai.com/robust-adversarial-inputs/
关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 | bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:[email protected]。


点击图片阅读
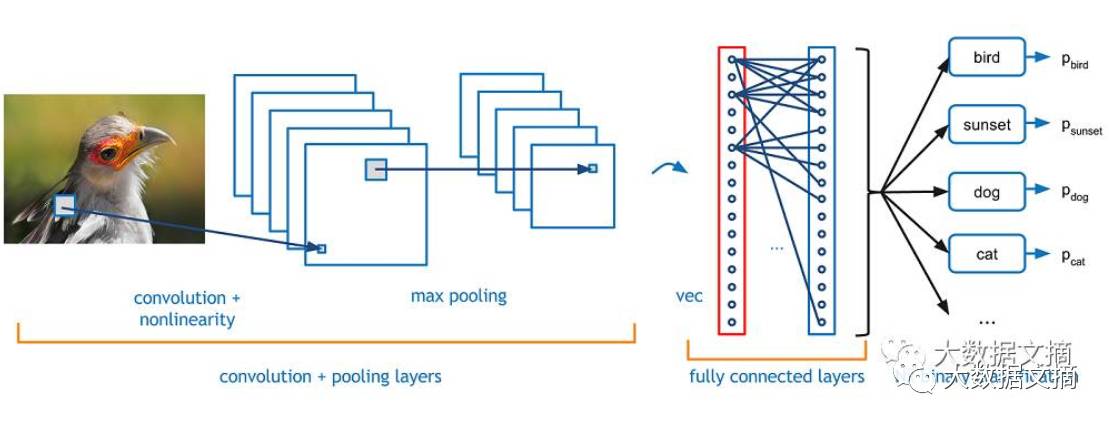
卷积?神经?网络?教你从读懂词语开始了解计算机视觉识别最火模型 | CNN入门手册(上)