
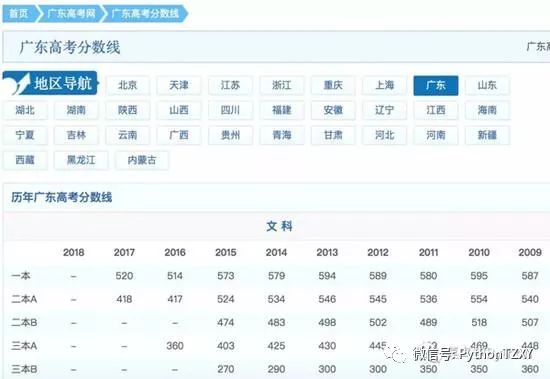
2.爬取数据
1.获取各省的分数线信息
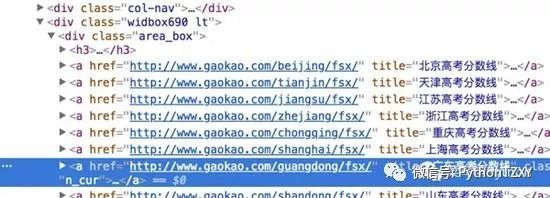
获取各省份的链接:
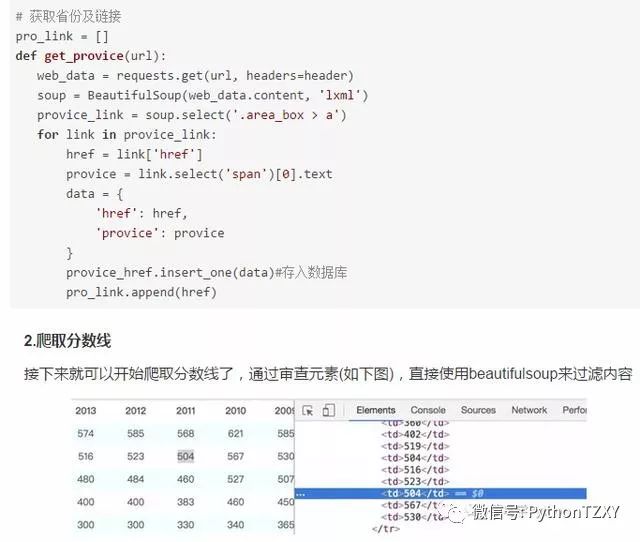
# 获取分数线 def get_score(url):
web_data = requests.get(url, headers=header)
soup = BeautifulSoup(web_data.content, 'lxml')
# 获取省份信息
provice = soup.select('.col-nav span')[0].text[0:-5]
# 获取文理科
categories = soup.select('h3.ft14')
category_list = []
for item in categories:
category_list.append(item.text.strip().replace(' ', ''))#替换空格
# 获取分数
tables = soup.select('h3 ~ table')
for index, table in enumerate(tables):
tr = table.find_all('tr', attrs={'class': re.compile('^c_\S*')})#使用正则匹配
for j in tr:
td = j.select('td')
score_list = []
for k in td:
# 获取每年的分数
if 'class' not in k.attrs:
score = k.text.strip()
score_list.append(score)
# 获取分数线类别
elif 'class' in k.attrs:
score_line = k.text.strip()
score_data = {
'provice': provice.strip(),#省份
'category': category_list[index],#文理科分类
'score_line': score_line,#分数线类别
'score_list': score_list#分数列表
}
score_detail.insert_one(score_data)#插入数据库
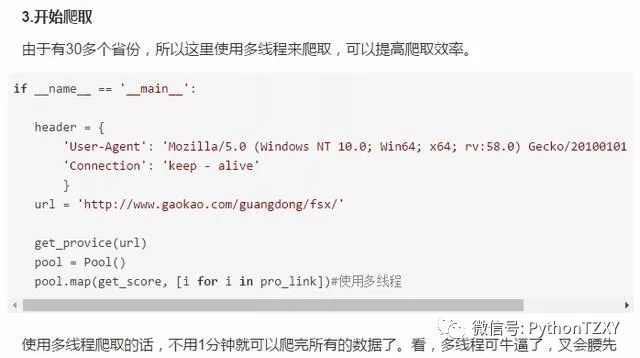
3.数据可视化
爬取数据只是第一步,接下来就要对数据进行处理展示了。从mongodb 中查找出数据,对数据进行清洗整理,由于我这里的pyecharts有点问题,所以使用echarts进行展示
1).筛选省份等信息
直接通过mongodb的find函数,限制查找的内容
import pymongo
import charts
client = pymongo.MongoClient('localhost', 27017)
gaokao = client['gaokao']
score_detail = gaokao['score_detail']
# 筛选分数线、省份、文理科
def get_score(line,pro,cate):
score_list=[]
for i in score_detail.find({"$and":[{"score_line":line},{"provice":pro},{'category': cate}]}):
score_list = i['score_list']
score_list.remove('-')#去掉没有数据的栏目
score_list = list(map(int, score_list))
score_list.reverse()
return score_list
2).定义相关数据
# 获取文理科分数 line = '一本'
pro = '北京'
cate_wen = '文科'
cate_li = '理科'
wen=[]
li = []
wen=get_score(line,pro,cate_wen)#文科 li=get_score(line,pro,cate_li)#理科










