本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
1 月 21 日,寒武纪思元 290 智能芯片及加速卡、玄思 1000 智能加速器在官网低调亮相,寒武纪表示该系列产品已实现规模化出货。去年,寒武纪招股书曾简单披露了一款训练芯片的 “彩蛋”,此后,寒武纪思元 290 芯片就一直被业界广泛关注并引发行业诸多猜想。如今,随着新一代训练产品线集中亮相,寒武纪略显“神秘” 的训练芯片及相应的业务布局逐渐清晰。
思元 290 智能芯片是寒武纪的首颗训练芯片,采用台积电 7nm 先进制程工艺,集成 460 亿个晶体管,支持 MLUv02 扩展架构,全面支持 AI 训练、推理或混合型人工智能计算加速任务。

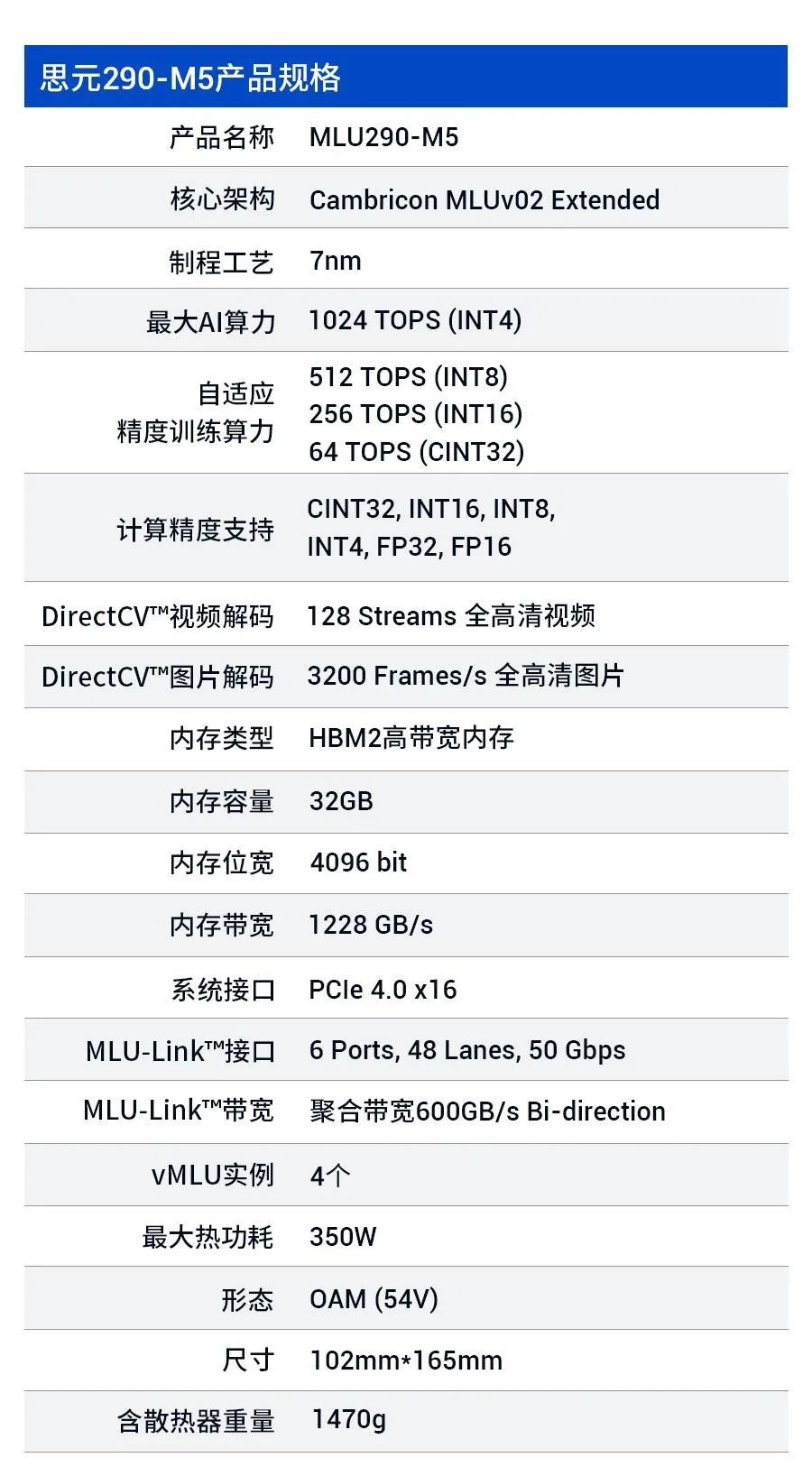
寒武纪 MLU290-M5 智能加速卡搭载思元 290 智能芯片,采用开放加速模块 OAM 设计,具备 64 个 MLU Core,1.23TB/s 内存带宽以及全新 MLU-Link™多芯互联技术,在 350W 的最大散热功耗下提供 AI 算力高达 1024 TOPS(INT4)。寒武纪玄思 1000 智能加速器,在 2U 机箱内集成 4 颗思元 290 智能芯片,高速本地闪存、Mellanox InfiniBand 网络,对外提供高速 MLU-Link™接口,打破智能芯片、服务器、POD 与集群的传统数据中心横向扩展架构,实现 AI 算力在计算中心级纵向扩展,是 AI 算力的高集成度平台。寒武纪训练产品线采用自适应精度训练方案,面向互联网、金融、交通、能源、电力和制造等领域的复杂 AI 应用场景提供充裕算力,推动人工智能赋能产业升级。MLUv02 架构为寒武纪 MLU200 全产品线共享,满足云、边、端三个场景的算力需求。云端训练对 AI 算力的要求更为苛刻,因此寒武纪对思元 290 的 MLUv02 架构进行了多项扩展,包括业内领先的 MLU-Link™多芯互联技术、高带宽 HBM2 内存、高速片上总线 NOC 以及新一代 PCIe 4.0 接口。相比寒武纪思元 270 芯片,思元 290 芯片实现峰值算力提升 4 倍、内存带宽提高 12 倍、芯片间通讯带宽提高 19 倍。新架构结合 7nm 制程,思元 290 可提供更优性能功耗比,以及多 MLU 系统的扩展能力。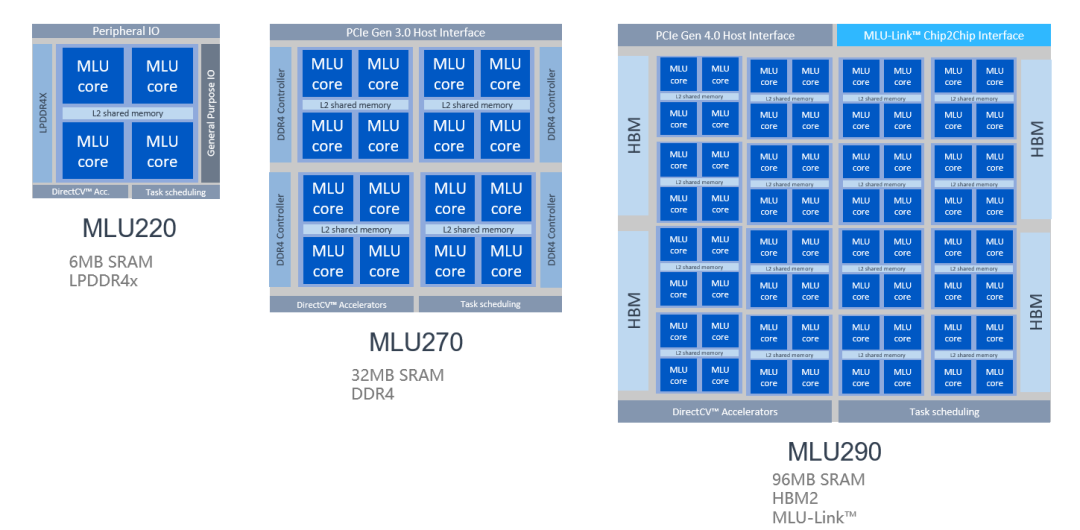
MLU290 的 MLUv02 架构进行了多项扩展。近年来,AI 算法模型的复杂程度高速增长,对算力和训练速度提出了更高的要求。为了构建更强大的计算平台,多芯片间的互联技术已成为市场刚需。寒武纪推出 MLU-Link™多芯互联技术,并首次搭载于寒武纪思元 290 芯片,每颗思元 290 的多芯互联总带宽高达 600GB/s。MLU-Link™具备丰富的互联特性,突破 PCIe 带宽和互联的瓶颈,相比思元 270 芯片通过 PCIe 并行的通讯方式,带宽提高 19 倍。MLU-Link™多芯互联技术支持多颗思元芯片无缝互联,支持跨系统互联,将纵向扩展能力整合到整个人工智能计算中心(AIDC),可以端到端加速大型 AI 模型训练。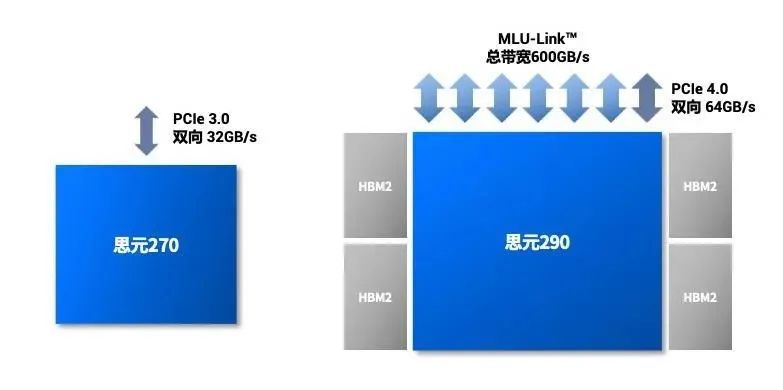 思元 290 采用 MLU-Link™多芯互联技术进行互联,带宽、灵活性全面优于 PCIe 3.0。
思元 290 采用 MLU-Link™多芯互联技术进行互联,带宽、灵活性全面优于 PCIe 3.0。

思元 290 相较思元 270 并行通讯总带宽提升 19 倍。不同场景下的 AI 训练对计算和存储的要求千差万别,如何提供更灵活也更稳定的服务,但同时让算力得到充分地利用,是 AIDC 面临的持续挑战。寒武纪虚拟化技术 vMLU,支持在思元 290 上实现 4 个相互隔离的 AI 计算实例,每个实例独占计算、内存和编解码资源。实例之间的硬件资源互不干扰,即使在虚拟化环境下仍可保持 90% 以上的极高效率,帮助客户充分利用硬件资源。
思元 290 上实现 4 个相互隔离的 AI 计算实例。vMLU 还可以帮助思元 290 芯片提供最佳的灵活性。通过热迁移技术,云管理员可将正在运行的 AI 负载及其应用程序移动到另外一台主机上,从而平衡整个 AIDC 的负载,并实现更好的容灾功能。
寒武纪 MLU290-M5 智能加速卡搭载了思元 290 智能芯片,采用开放加速模块 OAM 设计,具备 64 个 MLU Core,1.23TB/s 内存带宽以及全新 MLU-Link™多芯互联技术,在 350w 的最大散热功耗下提供 AI 算力高达 1024 TOPS(INT4)。
寒武纪首款智能加速器玄思 1000 包含 4 片思元 290 智能加速卡,最大 AI 算力超过 4100 万亿次每秒(4.1 PetaOPS INT4),一台玄思 1000 计算单元就足以替代一个小型传统超级计算中心。玄思 1000 内置高带宽低延时的 MLU-Link™多芯互联技术,实现内部 4 颗思元 290 进行高速互联,同时打破服务器、紧耦合微集群(POD)与集群的传统数据中心横向扩展架构,将 AIDC 构建为节点、POD 乃至超大规模混合扩展架构(Hybrid Scale-out),实现 AI 算力计算中心级纵向扩展,满足高性能、高扩展性、灵活性、高鲁棒性的要求。
玄思 1000 是 AI 算力的高集成度平台,支持计算中心级纵向扩展。算力、算法、数据是人工智能发展的三大要素,随着这几年 AI 的逐步发展,算力的核心地位更为凸显。人工智能技术落地于实际应用中需要芯片和硬件层面强大的算力支撑。算力已成为驱动 AI 产业化和产业 AI 化发展的关键要素。下一代 AIDC 要求更多智能芯片无缝协同、并行运行的同时,还能保持高计算效率,从而提供超级巨大的算力,以应对超大规模训练的需要。寒武纪玄思 1000 智能加速器重新思考了未来 AIDC 的基础架构,在内部和外部采用统一的 MLU-Link™多芯互联技术进行通讯,使得思元 290 智能芯片的互联范围可以从单机扩展到 POD 乃至整个计算中心,重塑了基础架构。 玄思 1000 支持 8 个 400G MLU-Link™和 2 个 200G 网络接口,总带宽高达 3600Gbps,是传统异构服务器的 2 倍。
玄思 1000 支持 8 个 400G MLU-Link™和 2 个 200G 网络接口,总带宽高达 3600Gbps,是传统异构服务器的 2 倍。
玄思 1000 配置 8 个对外互联的 MLU-Link™接口,支持跨系统互联构建 MLU POD。标准配置支持 MLU POD 16、24、32。在 POD 内部,所有 290 芯片均可通过 MLU-Link™多芯互联技术进行通讯,在带宽和延时方面实现了突破;POD 外部通过玄思 1000 内置的网卡与其他系统进行通讯,实现了 AI 训练集群性能、扩展性和鲁棒性的协同提升。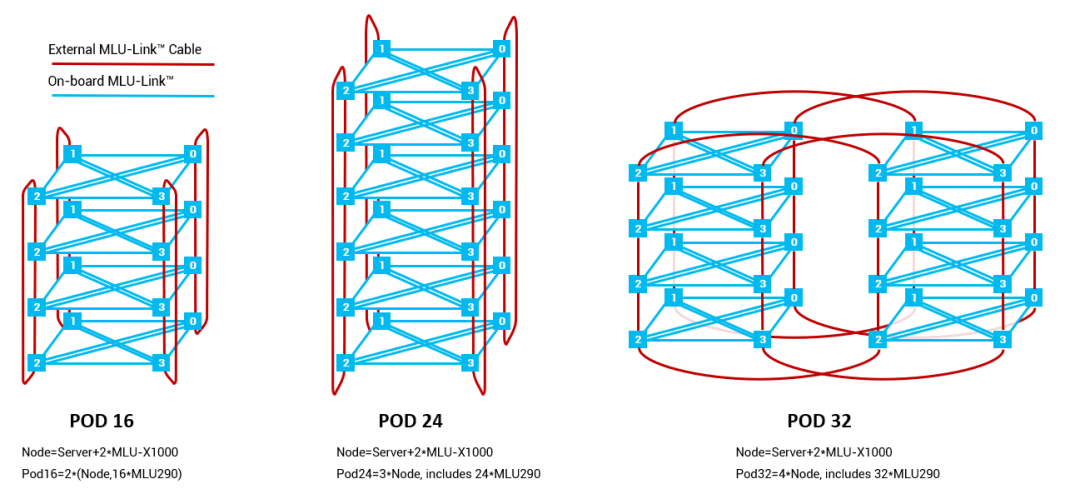
POD 内所有思元芯片通过 MLU-Link™全互联。









