
爱撒谎的男孩,Python中文社区专栏作者
博客:https://chenjiabing666.github.io
主要工具
scrapy
BeautifulSoup
requests
分析步骤
打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点
我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信息都在
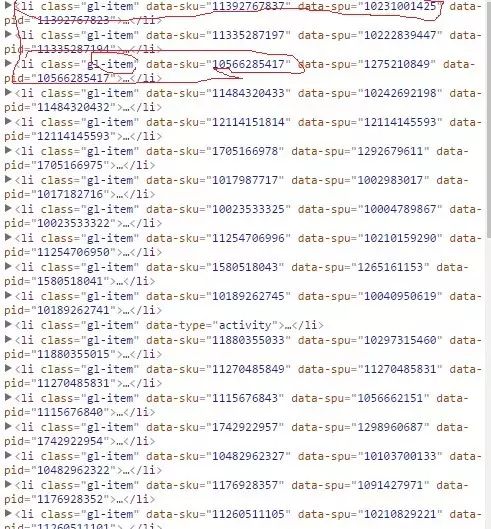
接着我们打开网页源码就会发现其实网页源码只有前30条的数据,后面30条的数据找不到,因此这里就会想到ajax,一种异步加载的方式,于是我们就要开始抓包了,我们打开chrome按F12,点击上面的NetWork,然后点击XHR,这个比较容易好找,下面开始抓包,如下图:
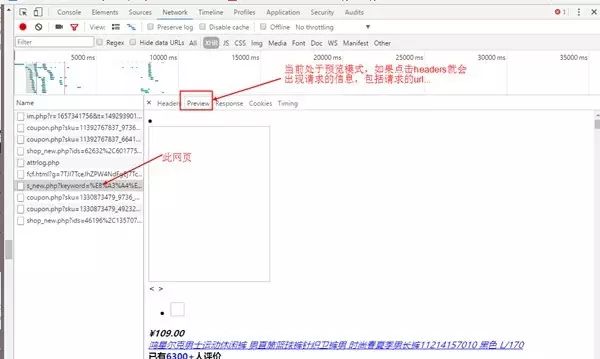
从上面可以找到请求的url,发现有很长的一大段,我们试着去掉一些看看可不可以打开,简化之后的url=https://search.jd.com/s_new.php?keyword=%E8%A3%A4%E5%AD%90&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&offset=3&wq=%E8%A3%A4%E5%AD%90&page={0}&s=26&scrolling=y&pos=30&show_items={1}
这里的showitems是裤子的id,page是翻页的,可以看出来我们只需要改动两处就可以打开不同的网页了,这里的page很好找,你会发现一个很好玩的事情,就是主网页的page是奇数,但是异步加载的网页中的page是偶数,因此这里只要填上偶数就可以了,但是填奇数也是可以访问的。这里的show_items就是id了,我们可以在页面的源码中找到,通过查找可以看到id在li标签的data-pid中,详情请看下图
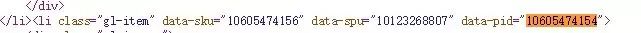
上面我们知道怎样找参数了,现在就可以撸代码了
代码讲解
首先我们要获取网页的源码,这里我用的requests库,安装方法为pip install requests,代码如下:

根据上面的分析可以知道,第二步就是得到异步加载的url中的参数show_items,就是li标签中的data-pid,代码如下:

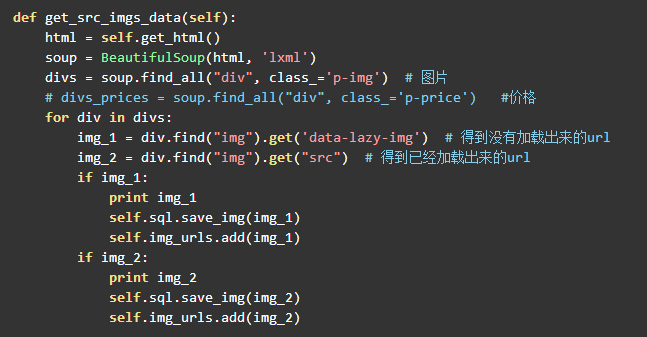
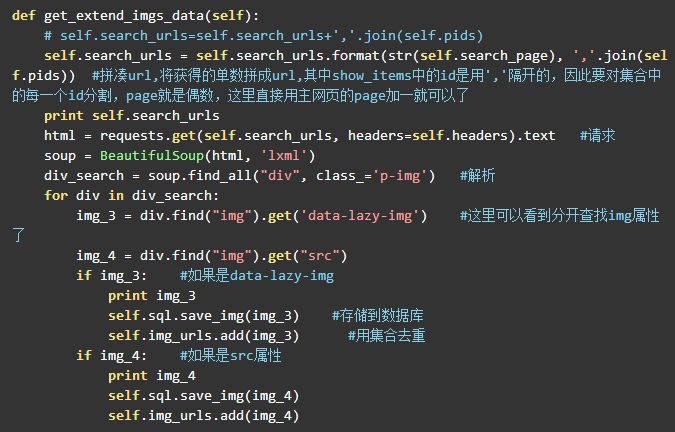
下面就是获取前30张图片的url了,也就是主网页上的图片,其中一个问题是img标签的属性并不是一样的,也就是源码中的img中不都是src属性,一开始已经加载出来的图片就是src属性,但是没有加载出来的图片是data-lazy-img,因此在解析页面的时候要加上讨论。代码如下:
前三十张图片找到了,现在开始找后三十张图片了,当然是要请求那个异步加载的url,前面已经把需要的参数给找到了,下面就好办了,直接贴代码:
通过上面就可以爬取了,但是还是要考虑速度的问题,这里我用了多线程,直接每一页面开启一个线程,速度还是可以的,感觉这个速度还是可以的,几分钟解决问题,总共爬取了100个网页,这里的存储方式是mysql数据库存储的,要用发哦MySQLdb这个库,详情自己百度,当然也可以用mogodb但是还没有学呢,想要的源码的朋友请看GitHub源码。
拓展
写到这里可以看到搜索首页的网址中keyword和wq都是你输入的词,如果你想要爬取更多的信息,可以将这两个词改成你想要搜索的词即可,直接将汉字写上,在请求的时候会自动帮你编码的,我也试过了,可以抓取源码的,如果你想要不断的抓取,可以将要搜索的词写上文件里,然后从文件中读取就可以了。以上只是一个普通的爬虫,并没有用到什么框架,接下来将会写scrapy框架爬取的,请继续关注哦!
长按扫描关注Python中文社区,
获取更多技术干货!
Python 中 文 社 区
Python中文开发者的精神家园
合作、投稿请联系微信:
pythonpost
— 人生苦短,我用Python —
1MEwnaxmMz7BPTYzBdj751DPyHWikNoeFS
本文为作者原创作品,未经作者授权同意禁止转载
点击阅读原文可进入Python圈子获取下方资料:
Python网络爬虫学习资料大全、《Python爬虫入门》、《Python简易爬虫实战案例》案例源代码及各类Python资料、技术源码、行业信息精选定期分享。










