
目前使用了深度学习技术的移动应用 通常都是直接依赖云服务器来完成DNN所有的计算操作,但这样做的缺点在于移动设备与云服务器之间的数据传输带来的代价并不小(表现在系统延迟时间和移动设备的电量消耗) ;目前移动设备对DNN通常都具备一定的计算能力,尽管计算性能不如云服务器但避免了数据传输的开销。
论文作者提出了一种基于模型网络层为粒度的切割方法,将DNN需要的计算量切分开并充分利用云服务器和移动设备的硬件资源进行延迟时间和电量消耗这两方面的优化。 Neurosurgeon很形象地描述了这种切割方法:向外科医生一样对DNN模型进行切分处理。
对于所有使用深度学习技术来处理图像、视频、语音和文本数据的个人智能助手而言,目前工业界通常的做法是,利用云服务器上强大的GPU集群资源来完成应用程序的计算操作(以下简称为现有方法)。
目前运行在移动设备上的个人智能助手(例如Siri、Google Now和Cortana等)也都是采用这种做法。尽管如此,我们还是会思考,能不能也对移动设备本身的计算能力加以利用(而不是完全依靠云服务),同时确保应用程序的延迟时间以及移动设备的电量消耗处于合理范围内。
目前的现状是,智能应用程序的计算能力完全依赖于Web服务商所提供的高端云服务器。
而Neurosurgeon打破了这种常规做法(即智能应用的计算能力完全依托于云服务)!在这篇出色的论文中, 作者向我们展示了一种新思路:将应用程序所需的计算量“分割”开,并同时利用云服务和移动设备的硬件资源进行计算 。下面是使用Neurosurgeon方法后所取得的结果,这将会使我们所有人受益:
系统延迟时间平均降低了3.1倍(最高降低了40.7倍),从而应用程序的响应将更加迅速和灵敏。
移动设备的耗电量平均降低了59.5%(最高降低了94.7%);(也许你会质疑,真的能够在移动设备上实施更多计算量的同时降低电量消耗吗?答案是十分肯定的!)
云服务器上数据中心的吞吐量平均提高了1.5倍(最高能提高6.7倍),相较于现有方法这是一个巨大的超越。
下面我们会先举个例子,来看看“对计算量进行分割”这件事情是多么的有趣,之后会了解到Neurosurgeon是如何在不同的DNN模型中自动检测出“最佳分割点”的,最后会展示相应的实验结果以证实Neurosurgeon所宣称的能力。
(值得一提的是,目前主流的平台已经支持并实现了在移动设备上进行深度学习方面的计算。Apple在iOS10系统中新增了深度学习相关的开发工具,Facebook去年发布了Caffe2Go使得深度学习模型能够运行在移动设备上,而Google也在前不久发布了深度学习开发工具TensorFlow Lite以用于安卓系统。)
▌ 数据传输并不是没有代价
最新的SoC芯片让人印象深刻。这篇论文使用了NVIDIA的Jetson TK1平台(拥有4核心的ARM处理器和一个Kepler GPU)(如下表1),数十万个设备的组合的计算量是惊人的。

如果你对比一下服务器上的配置(如下表2),你会发现移动设备的配置还是远比不上服务器的。

接下来我们来分析一个常用于图片分类任务的AlexNet模型(一个深层次的CNN网络模型),该模型的输入是一张大小为152KB的图片。首先对比一下模型在两种环境下的运行情况:在云服务器上实施全部的计算操作和在移动设备上实施全部的计算操作。
如果我们仅仅看应用的延迟时间这一指标,(如下图3)可以发现只要移动设备拥有可用的GPU,在本地GPU上实施所有的计算操作能够带来最佳的体验(延迟时间最短)。而使用云服务器进行全部的计算时,统计表明计算所消耗的时间仅占全部时间的6%,而剩余的94%都消耗在数据传输上。
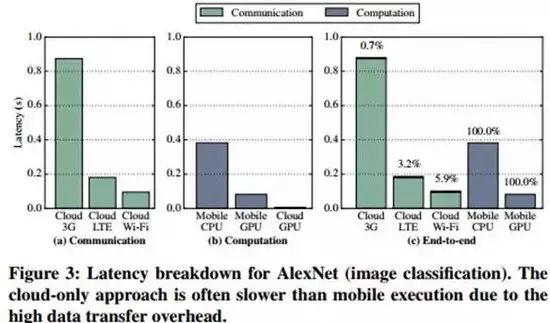
相较于现有方法,在LTE和3G网络条件下,使用移动设备自身的GPU进行全部的计算能够取得更低的系统延迟时间;同时,在LTE和Wi-Fi网络条件下,现有方法要比单纯仅用移动设备CPU进行全部的计算操作要更好(系统延迟时间更少)。
下图4是不同网络条件下,使用云服务器和手机CPU/GPU下的电量消耗情况:

如果移动设备连接的是Wi-Fi网络,最低的电量损耗方案是发送相应的数据到云服务器并让其进行全部的计算操作。但如果连接的是3G或LTE网络,如果该移动设备有可用的GPU,那么在本地GPU上实施全部的计算操作这一方案所导致的电量消耗,会比需要进行数据传输且在云服务器上实施全部的计算操作这一方案更低。
尽管云服务器的计算能力要强于移动设备,但由于其需要进行数据的传输(在有的网络环境下的所带来的系统延迟时间和电量消耗量并不小),所以从系统的角度,完全使用云服务器进行计算的方法并不一定是最优的。
▌ 各种网络层的数据传输和计算需求并不相同
那么,在所有计算都实施在云服务器或移动设备上这两种“相对极端”的方法之间,是否存在某个最优切分点呢?换言之,在数据传输和实施计算两者之间或许存在一种折中。下图是一张简单的草图,以方便理解接下来要做的事情。
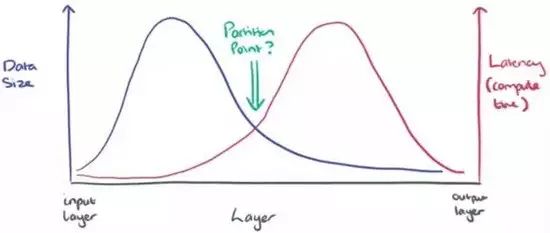
一种直观的切分方法是基于DNN中网络层作为边界。以AlexNet为例,如果我们能够计算出每一层的输出数据量和计算量,将得到如下的统计图(下图5):
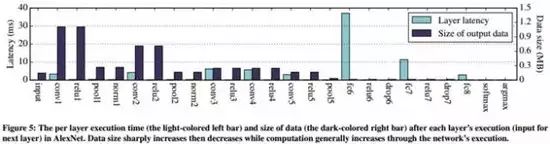
从图5中可以看出,对于AlexNet模型较前的卷积层而言,数据输出量随着层数增加而迅速递减。然而,计算量在模型的中后部分开始逐步递增,在全连接层的计算量达到了最高的幅度。
接下来值得思考的是,如果我们将AlexNet模型中的各个网络层分割开会发生什么呢?(也就是说,在移动设备上处理模型的前n层得到第n层的输出结果,再将该输出结果传输至云服务器上进行之后的计算,最后再将输出结果传输至移动设备上。)
下图6中你能看到AlexNet模型各层的延迟时间和电量消耗情况,最佳的分割点以星星符号表示。
以网络层为粒度的分割算法能够大大改善模型的延迟时间和电量消耗量。对于AlexNet模型,在移动设备GPU可用和Wi-Fi网络条件下,最佳的分割点处于模型的中部。
以上只是针对AlexNet模型的分割方法。然而,这种分割方法是否同样适用于其他的用于处理图像、视频、语音和文本的DNN模型们?文章作者在多种DNN模型上做了相应的分析如下表3:
对于应用于计算机视觉 (Computer Vision, CV) 领域的具有卷积层的模型,通常最佳的分割点在模型的中部。而对于通常只有全连接层和激活层的ASR, POS, NER和CHK网络模型(主要应用在语音识别(Automatic Speech Recognition, ASR)和自然语言处理领域(Natural Language Process, NLP))而言,只能说有找到最佳的分割点的可能。
在DNN模型上进行分割的最佳方法取决于模型中的拓扑层和结构层。CV领域的DNN模型有时在模型的中部进行分割是最好的,而对于ASR和NLP领域的DNN模型,在模型的开始部分或者结尾部分进行分割往往更好一点。可以看出,最佳分割点随着模型的不同而变化着,因此我们需要一种系统能够对模型进行自动的分割并利用云服务器和设备GPU进行相应的计算操作。
▌Neurosurgeon的工作原理
对于一个DNN模型,影响最佳的分割点位置的因素主要有两种:一种是静态的因素,例如模型的结构;一种是动态的因素,例如网络层的可连接数量、云服务器上数据中心的负载以及设备剩余可用的电量等。
由于以上动态因素的存在,我们需要一种智能系统来自动地选择出DNN中的最佳分割点,以保证最终系统延迟时间和移动设备的电池消耗量达到最优的状态。因此,我们设计了出这样一种智能切分DNN模型的系统,也就是Neurosurgeon。
Neurosurgeon由以下两个部分组成:一部分是在移动设备上一次性地创建和部署用于预测性能(包括延迟时间和电量消耗量)的模型,另一部分是在服务器上对各种网络层类型和参数(包括卷积层、池化层、全连接层、激活函数和正则化项)进行配置。前一部分与所用的具体DNN模型结构无关,预测模型主要是根据DNN模型中网络层的数量和类型来预测延迟时间和电量消耗,而不需要去执行具体的DNN模型。
预测模型会存储在移动设备中,之后会被用于预测DNN模型中各层的延迟时间和电量消耗。
在DNN模型的运行时,Neurosurgeon就能够动态地找到最佳的分割点。首先,它会分析DNN模型中各网络层的类型和参数情况并执行之,然后利用预测模型来预测各网络层在移动设备和云服务器上的延迟时间和电量消耗情况。根据所预测的结果,结合当前网络层自身及数据中心的负载情况,Neurosurgeon选择出最佳的分割点,调整该分割点能够实现端到端延迟时间或者电量消耗的最优化。

▌Neurosurgeon的实际应用
之前的表3展示了用于评测Neurosurgeon的8种DNN模型,另外,实验用到的网络环境有3种(Wi-Fi,LTE和3G网络)和2种移动设备硬件(CPU和GPU)。在这些模型和配置下,Neurosurgeon能够找到一种分割方法以加速应用的响应时间至最优的98.5%。
实验结果表明,相比于目前使用仅使用云服务器的方法,Neurosurgeon能够将应用的延迟时间平均降低了3.1倍(最高能达到40.7倍)。
在电量消耗方面,相比于现有方法,Neurosurgeon能够使得移动设备的电量消耗量平均降低至59.5%,最高能降低至94.7%。
下图14展示了Neurosurgeon随着网络环境的变化(即LTE带宽变化)自适应进行分割和优化的结果(下图中的蓝色实线部分),可以看出比起现有方法(下图中的红色虚线部分)能够大幅度地降低延迟时间。
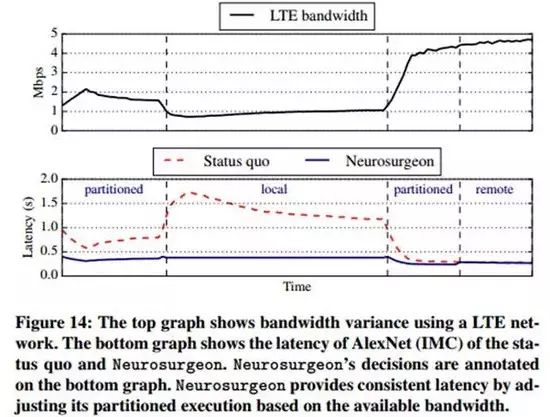
Neurosurgeon也会与云服务器保持周期性的通讯,以获得其数据中心的负载情况。当服务器的数据中心负载较大时,它会减少往服务器上传输的数据量而增加移动设备本地的计算量。总之,Neurosurgeon能够根据服务器的负载情况作出适当的调整已达到最低的系统延迟时间。
我们利用 BigHouse (一种服务器数据中心的仿真系统)来对比现有方法和Neurosurgeon。实验中将query数据均匀地分配到之前表3中8种DNN模型之上,使用所测量的所有模型的平均响应时间,并结合Google网页搜索中query的分布来得到query的完成率(query inter-arrival rate)。
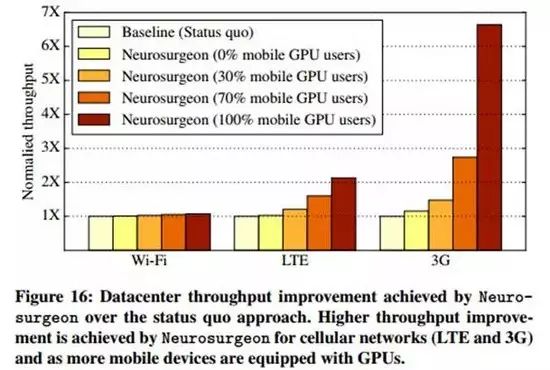
上图16表明,在移动设备使用Wi-Fi网络的条件下,Neurosurgeon所带来的的数据吞吐量是现有方法的1.04倍。而随着连接网络质量的变差,Neurosurgeon会让移动设备承担更多的计算量,此时云服务器上数据中心的吞吐量将增加:较现有方法,连接LTE网络的情况下数据中心的吞吐量增加至1.43倍,而3G网络条件下则增加至2.36倍。
论文出处
Neurosurgeon:collaborative intelligence between the cloud and mobile edge Kang et al.,ASPLOS’17
http://web.eecs.umich.edu/~jahausw/publications/kang2017neurosurgeon.pdf
文章来源:掘金志

媒体合作请联系:
邮箱:[email protected]









