【新智元导读】
PyTorch 发布了最新版,API 有一些变动,增加了一系列新的特征,多项运算或加载速度提升,而且修改了大量bug。官方文档也提供了一些示例。

新的层和函数
-
torch.topk
现在支持所有 CUDA 类型,不仅是
torch.cuda.FloatTensor
。
-
增加了一个 三路排序损失:nn.TripletMarginLoss
-
增加了每个实例的归一化层:nn.InstanceNorm1d, nn.InstanceNorm2d, nn.InstanceNorm3d
每个通道都被作为一个实例进行归一化处理,并进行均值消减和标准差。这在处理需要类似 BatchNorm 效果的较大的图像和较小的 mini-batches 时很有用。
-
增加了
nn.ZeroPad2d
和
nn.ConstantPad2d
-
增加了
nn.Bilinear
,计算
Y = X1 * W * X2 + b
支持所有函数的负维
使用维度参数的每个函数也允许采取负维(negative dimensions)。
负维将索引上个维度的张量。
例如:

这里,由于
x
具有3维,并且
dim = -1
,因此最后一个维度,即
dim = 3
被采用来得到平均值。
具有维度参数的函数有:

CUDA 支持稀疏张量,更快的 CPU sparse
新版本中
torch.sparse API
的一部分也支持
torch.cuda.sparse。* Tensor
。
CUDA 支持的函数有:

利用这些稀疏函数,
nn.Embedding
现在也在 CUDA 上支持 sparse(使用
sparse = True
标志)。
一种新的混合矩阵乘法
hspmm
,将稀疏矩阵与密集矩阵相乘,并以混合张量的形式(即1个稀疏维度,1个密集维度)返回1个矩阵。
几个CPU稀疏函数具有更高效的实现。
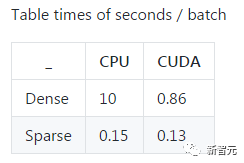
这里有一个嵌入式分类器训练脚本,作者是@martinraison,我们可以对比 CUDA sparse 和 CUDA dense 的表现。(
http
://t.cn/RaZcltA
)
named_parameters 过滤特定的参数类型
假设你想为模型除 biases 外的所有参数增加权重衰减(weight decay),怎样只获得模型的 biases?
这里我们引入了 nn.Module.named_parameters,它结合
named_children
和
named_modules
来帮助过滤模型的特定属性。
例子:过滤一个模型的 biases, weight_decay 为0

-
在适当的情况下,通过使用一些 thrust primitives,
cumsum
和
cumprod
在GPU上显着加快了。
-
通过一个 fused kernel,
LSTMCell
和
GRUCELL
在GPU上显着加快了。
-
CuDNN 的默认算法更改为
PRECOMP_GEMM
,这是一个更快的算法,需要的工作空间很小。这个之前是
IMPLICIT_GEMM
,占用的工作空间为0,但是慢很多。
-
通过将 batches 直接整到共享内存中,数据加载速度提升了 5%~10%。
-
通过分治法(sgesdd)在 GPU 上计算 SVD,加速了2~5倍。
-
常用的函数
expand
移到 C,在较小的模型中具有更好的性能。
-
Added contiguous checks on weight and bias for a large range of THNN functions
-
make the range of
random_
correct when both lower and upper bound are specified
-
parallel_apply
now can take arguments that are unhashable
-
Reshape
grad
correctly in the Dot function (inputs don't have to be 1D vectors...)
-
Added
Variable.type_as
-
Unify argument names of
norm
and
renorm
to have
p=norm_type
, dim=dim
-
btrisolve
works on CPU doubles
-
ipython autocomplete for torch.nn.Module fixed via implementing
__dir__
-
device_ids
can now be
None
again in
F.data_parallel
and will use all available GPUs
-
workaround cudnn bugs in BatchNorm (
-
Padding bugfix in Conv1d CPU
-
remainder
and
cremainder
are fixed for integer types
-
fix memory leak in
btrisolve
and
getri
-
If nn.Module's source cant be retrieved because of any exception,
-
handle serialization to be non-fatal
-
collate_fn
now retains the type of the numpy array
-
is_tensor
and
is_storage
are now fixed for old-style Python classes
-
torch.cat
now supports keyword arguments
-
CUDA collectives supported coalescing, but the inputs were all assumed
-
to be of the same Tensor type. This is fixed.
-
Fix a deadlock bug in autograd because of an underlying glibc bug in specific
-
linux distros (ArchLinux in particular)
-
abs
is now fixed for
char
and
short
cuda types
-
fix
torch.diag
autograd when giving a dimension argument
-
fix grouped convolution on CPU when
bias=False
-
expose
dilated
convolutions for
ConvTranspose*d
-
Fix a bug in
HingeEmbeddingLoss
where
margin
can now be specified via kwargs
下载源码:
https://github.com/pytorch/pytorch/releases






