问耕 编译整理
量子位 出品 | 公众号 QbitAI

本文作者是MIT的大二学生Michael Gump(阿甘),内容为他在无人车公司Voyage的工作总结。本文还得到Voyage首席执行官Oliver Cameron的推荐。
作为一名计算机专业的学生,我一直对机器学习特别是强化学习很感兴趣,特别喜欢琢磨OpenAI的相关研究。去年冬天,我还参加了一门无人车的课程,从这个时候开始,自动驾驶汽车这个领域一直让我感到特别兴奋。
三个月前,我加入了Voyage的深度学习实习项目。Voyage是一家从Udacity剥离出来的初创公司,致力于研发自动驾驶出租车。
在学校里能学到很多知识,但并不能让你了解真实的世界。在Voyage实习的这段期间,不但帮我弥补了教育中的缺失,而且我真的有机会接触到最酷的产品。在这里,我准备把我这段时间的收获分享给大家。
我的工作
这个夏天的实习中,我一直在研究计算机视觉相关的几个问题,阅读了很多论文并且训练了不少模型。大部分时候,我一直都是用公开数据集,对激光雷达(LiDAR)数据进行分类识别。数据集地址如下:
http://www.cvlibs.net/datasets/kitti/index.php
http://cs.stanford.edu/people/teichman/stc/
当人类观察世界的时候,可以自动的感知深度,并且能够识别出道路上是一辆车还是一个行人。怎么能让无人车也做到这一点?过去几个月我的大部分工作,就是想办法让Voyage的自动驾驶出租车对车辆和行人进行分类。
我使用的工具是三维视图(LiDAR点云)+深度学习。
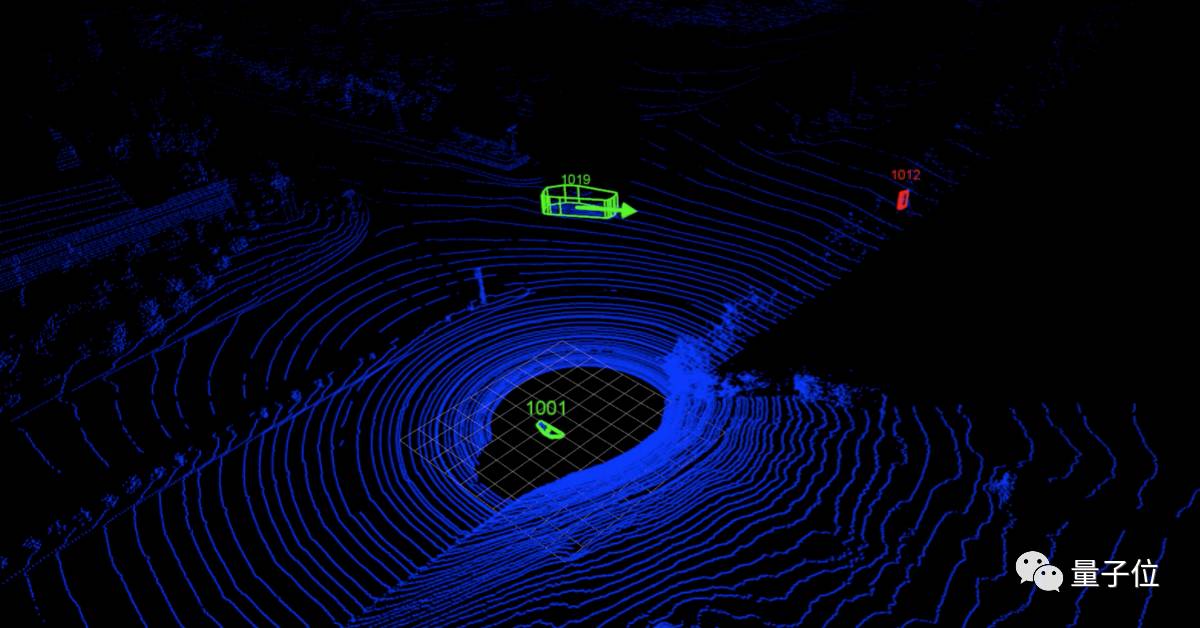
△ 这个分类器模型正确的把汽车标为绿色,行人标为红色
物体分类识别
对于一辆无人车来说,它需要采集原始的传感器信息(例如点云),然后还得搞清楚到底看到了什么。这其中最重要的是如下两个问题。
距离:离我撞上这个物体还有多远
类别:我看到的究竟是个什么
解决这个问题,既可以设计传感器直接获取相关信息,也可以从现有的传感器中提取所需信息。对于距离这个问题,激光雷达是现在最好的传感器。除非特别“勇敢”,一般搞无人车不会绕过这个关键的设备。
然而对于分类(识别车辆、行人)这个问题,并不能通过传感器直接获知结果,需要我们研发算法来实现,这也就是我这个夏天的主要工作。

△ 黑白图像是LiDAR数据,然后增加分类信息(绿色代表行人,蓝色代表车辆)
从人类的视角来看,这些都是很简单的问题。但请注意,人类已经有数百万年的发展进化历史。怎么才能在短时间内让无人车也具备同样的能力?如果你不是外行就该知道,这个问题的答案是:CNN,卷积神经网络。
在很多难题上CNN都给出了惊人的结果,只需要一些微调,这个神经网络就能很好的用来处理LiDAR数据。
然而,一个深层卷积网络可能不是我们最好的选择。我们系统的一个关键要求,是必须要以很高的帧率运行。也就说我们需要构建一个实时运行的系统,因此必须得选择一个可以快速得到良好效果的解决方案。
虽然CNN可以识别图像中的复杂模式,但通常速度很慢。所以这个夏天我花了大部分时间来寻找一个替代方案。其中一个替代方案是手动挑选与物体类别高度相关的物理特征信息,也就是对我们的模型进行一些特征工程。
在这个过程中,我的导师教会了我一件事:实验、实验、实验。
我的成果
这个夏天我的收获之一,就是学会使用一个很棒的快速可视化工具。在Vispy的帮助下,我对大量的点云进行了有序的可视化,然后在类似真实世界的环境中对模型进行调试。我这次实习的另一个收获是,直接从模型的损失曲线中很难看出问题。
(Vispy地址:http://vispy.org/)
我用了PyTorch来训练和验证我的模型。我之前对PyTorch不熟,但现在它成为我最喜欢的深度学习框架。虽然PyTorch没有TensorFlow那么多的特性,但是更容易上手。
(插播一个量子位之前的报道:《PyTorch还是TensorFlow?》)
我搭建的模型之一,是一个编码解码器(Encoder-Decoder)网络,能够对多个通道的输入数据进行分类预测。从这些嘈杂的预测中,我们可以推断出面前物体的真实类别。这种模型非常强大,可以对某些传感器和处理错误免疫。
例如,依靠对象大小和形状进行分类的模型很容易出现检测错误。而编码解码器模型可以通过识别场景中的模式并直接转变为预测来回避这样的问题。


△ 工作中的编码器-解码器模型。模型还很粗糙。
我上述工作参考了以下的论文:
《Multi-View 3D Object Detection Network for Autonomous Driving》
https://arxiv.org/abs/1611.07759
《LIDAR-based 3D Object Perception》
https://pdfs.semanticscholar.org/2c45/03c72ba7f53f3385859bd5e6311c58e73905.pdf
量子位AI社群7群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot2入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot2,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。








