
在大多数标准中,Flask都算是小型框架,小到可以称为“微框架”,所以你一旦熟悉使用它,很可能就能读懂他所有的源码,本项目是自己线下玩的项目,因此采用了Flask这种小而功能比较全的框架。
TensorFlow是Google于2015年11月9日正式开源的深度学习框架,提供了海量的深度学习模型的API,可以快速的实现深度学习模型的搭建。目前在GitHub上的star也是惊人:
基于Python的TnesoFlow接口,训练seq2seq模型用于娱乐性的聊天机器人场景。 Seq2Seq被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。Seq2Seq解决问题的主要思路是通过深度神经网络模型(常用的是LSTM,GRU)将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码(Encoder)输入与解码(Decoder)输出两个环节组成, 前者负责把序列编码成一个固定长度的向量,这个向量作为输入传给后者,输出可变长度的向量。
首先我们基于问答语料库去训练我们的seq2seq聊天机器人系统,其核心算法主要如下:
```python def getmodel(feedprevious=False): """
构造模型:seq2seq feed_previous
表示decoderinputs是我们直接提供训练数据的输入, 还是用前一个RNNCell的输出映射出来的,如果feedprevious为True, 那么就是用前一个RNNCell的输出,并经过Wx+b线性变换 """
learning_rate = tf.Variable(float(init_learning_rate), trainable=False, dtype=tf.float32)
learning_rate_decay_op = learning_rate.assign(learning_rate * 0.9)
encoder_inputs = []
decoder_inputs = []
target_weights = []
for i in range(input_seq_len):
encoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="encoder{0}".format(i)))
for i in range(output_seq_len + 1):
decoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="decoder{0}".format(i)))
for i in range(output_seq_len):
target_weights.append(tf.placeholder(tf.float32, shape=[None], name="weight{0}".format(i)))
targets = [decoder_inputs[i + 1] for i in range(output_seq_len)]
cell = tf.contrib.rnn.BasicLSTMCell(size)
outputs, _ = seq2seq.embedding_attention_seq2seq(
encoder_inputs,
decoder_inputs[:output_seq_len],
cell,
num_encoder_symbols=num_encoder_symbols,
num_decoder_symbols=num_decoder_symbols,
embedding_size=size,
output_projection=None,
feed_previous=feed_previous,
dtype=tf.float32)
loss = seq2seq.sequence_loss(outputs, targets, target_weights)
opt = tf.train.GradientDescentOptimizer(learning_rate)
update = opt.apply_gradients(opt.compute_gradients(loss))
saver = tf.train.Saver(tf.global_variables())
return encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate
训练好的模型会保存在model文件夹,供flask调用。我的语料是在网上找的一些还有就是自己编造了一些,语料很不规整也不全面,量也比较少,因此模型的表现并不是很理想,加上本身seq2seq模型的不可控性,会出现聊天机器人比较傻叉的回答和答非所问的情况(这个如果要商用还得考虑更多其他的trick这里只是娱乐性的尝试)。
我用CPU训练了10000个epoch,经过308分钟,模型训练好了。。。(此处应该有掌声)
下面就是基于flask搭建一套在线聊天系统了,这里基于redis缓存数据库的订阅与发送机制实现一个简单的SSE事件流(这个方法是我参考了GitHub一位大神的思路),当然我们也可以基于Flask-SSE模块,下面是项目的结构,和部分核心代码:
项目结构:
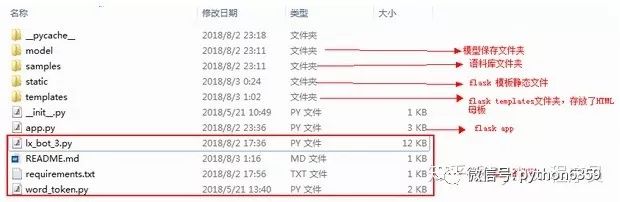
flask核心算法:
python app.secret_key='xujing in inter-credit'
redis数据库
r=redis.StrictRedis(host='xxx.xxx.xxx.xxx',port=6379,db=123,decode_responses=True)
定义事件流
def eventstream():
pubsub=r.pubsub()
pubsub.subscribe('lxchat')
for message in pubsub.listen():
print(message)
yield 'data:{}\n\n'.format(message['data'])
发送消息
@app.route('/send',methods=['POST'])
def post():
message=flask.request.form['message']
user=flask.session.get('user','anonymous')
now=datetime.datetime.now().replace(microsecond=0).time()










