作者:弗格森
【新智元导读】
康奈尔大学研究员结合贝叶斯和对抗生成网络,在6大公开基准数据集上实现了半监督学习的最佳性能,同时,这也是迈向终极无监督式学习的一大步。研究提出了一个实用的贝叶斯公式,用GAN来进行无监督学习和半监督式学习。这种新提出的方法,简洁性是其最大的优势——推理是直接进行的、可解释的、稳定的。所有的实验结果的获得,都不需要参数匹配,正则化或者任何的特别(ad-hoc)技巧。

康奈尔大学的 Andrew Gordon Wilson 和 Permutation Venture 的 Yunus Saatchi 最近发布了一项对无监督和半监督式学习的研究,名为贝叶斯生成对抗网络(Bayesian GAN)。
深度学习对大量标签数据的依赖是显而易见的,这也成为抑制深度学习发展的一个潜在要素之一。长久以来,科学家们都在探索使用尽量少的标签数据,希望实现从监督式学习到半监督式学习再到最后的无监督式学习的转化。
本文的作者在文章中也提到,“自然高维数据的有效半监督学习对于减少深度学习对大量标签数据集的依赖性至关重要。”
一般情况下,我们是没有带标签的数据的,除非以高成本或者通过人力劳动或通过昂贵的仪器(如用于自主驾驶的激光雷达)来实现的。
目前,无监督学习离我们还有一段距离,但是半监督式学习已经成为最新的研究热点。特别是进入2017年以来,对抗生成网络(GAN)和自动编码等技术不断获得进步,都佐证同时推动了半监督学习领域的发展。
对于人工智能终极目标之一——无监督学习来说,半监督学习也提供了一个实用和可量化的机制,以评估无人监督学习中的最新进展。
贝叶斯对抗生成网络:常见基准上能够提供最好的半监督学习量化结果
我们先来看一看文章的摘要:

作者提到,生成对抗网络能在不知不觉中学习图像、声音和数据中的丰富分布。这些分布通常因为具有明确的相似性,所以很难去建模。
他们在研究中提出了一个实用的贝叶斯公式,在实践中GAN来进行无监督学习和半监督式学习。在这一框架之下,使用了动态的梯度汉密尔顿蒙特卡洛(Hamiltonian Monte Carlo)来将生成网络和判别网络中的权重最大化。其获得结果的方法非常的直接,并且在不需要任何标准的干预,比如特征匹配或者mini-batch discrimination的情况下,都获得了良好的表现。
通过对生成器中的参数部署一个具有表达性的后验机制(posteriors)。贝叶斯GAN能够避免模式碰撞(mode-collapse),产生可判断的、多样化的候选样本,并且提供在既有的一些基准测试上,能够提供最好的半监督学习量化结果。比如,SVHN, CelebA 和 CIFAR-10。效果远远超过 DCGAN, Wasserstein GANs 和 DCGAN 等等。
通过学习高维自然信号,如图像,视频和音频,进而建立一个很好的生成模型,长久以来一直是机器学习的关键里程碑之一。在深层神经网络学习能力的赋能之下,生成对抗网络(GAN)(Goodfellow等,2014)和变分自动编码器(Kingma和Welling,2013)使AI 领域离实现这一目标更近了。
GAN通过深层神经网络转换白噪声(white noise),以从数据分布中产生候选样本。一个判别器会以一种监督式的方法,来学习如何调整其参数,以正确地区分一个特定的样本是来自生成器或者真实的数据分布。同时,生成器会更新其参数,以更好地“骗过”判别器。一旦生成器有了足够的容量,它就能从感兴趣的数据分布中近似地抽取CDF、反CDF组合。
由于设计的卷积神经网络为图像提供了合理的指标(不同于例如高斯似然,Gaussian likelihoods),使用卷积神经网络的GAN以反过来提供令人信服的,在图像上的隐含分布。
虽然GAN有着极大的影响力,但是他们的学习目标会导致模式碰撞(mode
collapse),也就是,生成器只存储了少量的几个训练样本,来骗过判别器。
这种方法论是对过去的高斯混合中最大似然密度估计的一种“怀旧”:通过每一个组件的变化的碰撞,我们可以获得一些永久性的相似性,然后把这些相似性储存在数据集中,但是,这些相似性对于可生成的密度估计来说是无用的。
此外,在GAN的训练过程中,需要有大量的干预,其中包括,特征匹配、标签梳理和mini-batch discrimination。
为了缓解这些在实践中的困难,最近许多研究都着眼于在标准的GAN训练中,用可转化的衡量标注,比如f-fivergences和Wasserstein分歧来替换Jensen-Shannon 分歧。
这些研究中,很多都选择了引入多变的正则化矩阵,以将相似性密度估计最大化。但是,正如选择争取的正则化矩阵非常困难一样,决定自己想要在GAN的训练中使用的“分歧”,也同样很难。
作者的想法是,GAN能够通过完整的概率推理来进行提升。确实,在生成器上的参数中的一个后验分布,可以是宽泛的和高度多模式的。总的来说,GAN的训练是基于最小-最大化优化的,通常会对后验机制在整个网络的权重进行衡量,把其作为一个单一节点上的一个聚焦点。
这样一来,即便生成器不对训练样本进行存储,我们依然能期待,生成器中的样本与数据分布中得到的样本是完全相关的。
此外,在网络权重中的后验器(posterior)中的每一个模型都与更广泛的不同的生成器形成呼应,彼此都有自己极具意义的阐释。通过完全呈现生成器和判别器上的参数中的后验分布,我们能够更加准确地为真实的数据建模。随后,推测的数据分布能够被用于准确和高数据效率和半监督式的学习。
这种新提出的方法,简洁性是其最大的优势——推理是直接进行的、可解释的、稳定的。确实,所有的实验结果的获得,都不需要参数匹配,正则化或者任何的特别(ad-hoc)技巧。
相关代码将很快公开。
在本研究中,作者提出了一个简单的贝叶斯公式,用于GAN中的端到端的无监督和半监督学习。在这个框架内,使用动态的梯度Hamiltonian Monte Carlo将生成器和判别器的权重posteriors进行边际化。作者对从生成器中获得的数据样本进行了分析,在生成器的权重中,展示了跨越几个独特模型的探索。还展示了在学习真正的分布的过程中,数据和循环的有效性。
作者称,在几个著名的基准测试,比如SVHN, MNIST, CIFAR-10 和 CelebA中展示了最好的半监督学习表现。
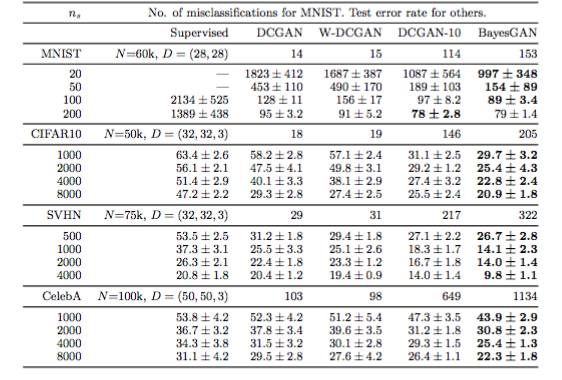
上图是贝叶斯GAN在几个数据集上与DCGAN、W-DCGAN等模型的性能比较。
MINST 是一个用于评估新的机器学习模型的著名基准,包含了60k(50k训练和10k测试)手写数字的标签图像。

http://yann.lecun.com/exdb/mnist/
MINST 最早的作者是 Chris Burges , Corinna Cortes ,后由Yann LeCun、Corinna Cortes 和 Christopher J.C. Burges共同完成。

作者共使用了6个著名的公开数据集来测试贝叶斯对抗生成网络模型:synthetic, MNIST, CIFAR-10, SVHN 和 CelebA。每一个数据集有四个不同的标签样本集。以上分别是
CIFAR-10, SVHN 和 CelebA的样本图像。
通过在生成器的加权参数进行丰富的多模态分布探索,贝叶斯GAN可以捕获各种各样的互补和可解释的数据表达。作者的研究已经表明,这样的表达可以使用简单的推理程序来实现半监督问题的优越性能。






