本来想搞个简单的网站没去搞携程啥的抓个马蜂窝玩玩,没想到马蜂窝也不是那么容易搞
对于新手来讲写爬虫最重要的一点就是要确定目标,知道自己要抓什么!
身为小白学完爬虫基础就想找东西练手,结果满脑子想到的都是一些大网站 京东,淘宝,携程等等········
难的自己还搞不定,小网站还没意思,我也很无奈 (有木有大佬推荐下好玩的网站我好练练手)
今天的目标是马蜂窝北京自由行攻略,有了目标咱们就开始干吧!
1.分析马蜂窝的url,列表页翻页url没变化,查看html 翻页链接里还没路径,当时看了想吐血噗····
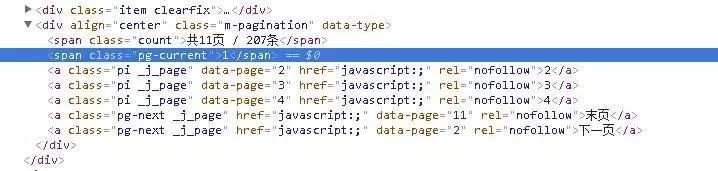
2.无奈抓包慢慢找其他接口,找到了json接口里面存着html,就一个参数也很好分析
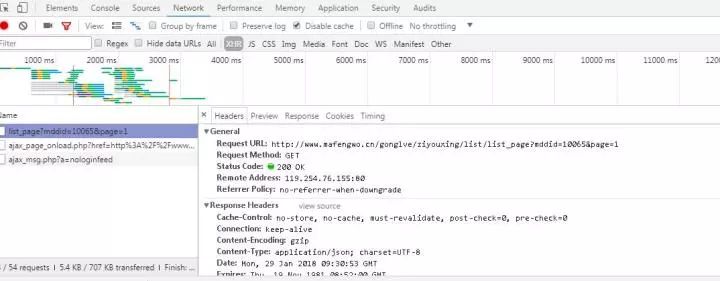
3.然后就简单了循环发请求拿标题链接去解析详情页
4.详情页的内容是放在不同div下 还要循环把所有内容抓到再拼接成一个字符串,稍微麻烦点
5.测试的时候发现有的文章是没作者没简介的,要判断一下如果抓到空 作者就赋值个'匿名'
6.存储的时候我用标题做的文件名TXT格式,又出现文件名有非法字符串的错误,百度了一段代码,贼鸡儿好用!
res = r"[\/\\\:\*\?\"\\|]"
title = re.sub(res, "_", title)
最后上代码:
import requests
from bs4 import BeautifulSoup
import json
import re
import os
headers = {
"Host" : "www.mafengwo.cn",
"Connection" : "keep-alive",
"Pragma" : "no-cache",
"Cache-Control" : "no-cache",
"Accept" : "*/*",
"X-Requested-With" : "XMLHttpRequest",
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36",
"Referer" : "http://www.mafengwo.cn/gonglve/ziyouxing/mdd_10065/",
"Accept-Language" : "en,zh-CN;q=0.8,zh;q=0.6",
}
#发送请求
def getpage():
os.mkdir('./mafengwo')
base_url = 'http://www.mafengwo.cn/gonglve/ziyouxing/list/list_page?mddid=10065&page=1'
response = requests.get(base_url,headers=headers)
json_html = json.loads(response.text)
#提取html内容
html = json_html["html"]
# print(html)
html = BeautifulSoup(html,'lxml')
#获取较大页数
max_page = html.select('span.count')[0].text
#用正则把页数从字符串中抽取出来
pattern = re.compile(r'\d+')
res = pattern.search(max_page)
max_number = res.group()
#循环发送请求获取所有列表页
for i in range(1,int(max_number)+1):
base_url = 'http://www.mafengwo.cn/gonglve/ziyouxing/list/list_page?mddid=10065&page=%d'
response = requests.get(base_url % i,headers=headers)
print('正在抓取第%s页' % i)
json_html = json.loads(response.text)
html = json_html["html"]
html = BeautifulSoup(html, 'lxml')
#获取详情页链接
list_link = html.select('a._j_item')
for link in list_link:
info = link.get('href')
#网页用的相对路径所以要拼接一下
info_link = 'http://www.mafengwo.cn' + info
# print(info_link)
details_page(info_link)
# 解析详情页
def details_page(info_link):
response = requests.get(info_link,headers=headers)
html = BeautifulSoup(response.text,'lxml')
title = html.select('div.l-topic h1')[0].text #标题
name = html.select('span.name') #作者
#作者有的是空的 要判断一下
if name == []:
name = '匿名'
else:
name = name[0].text.strip()
brief = html.select('div.l-topic > p') #简介
if brief == []:
brief = '无简介'
else:
brief = brief[0].text.strip()
content_list = html.select('div.f-block') #内容列表
#加换行为了好看而已
text = ['\n']
#循环内容列表把左右空格去掉 再用换行拼接成字符串
for i in content_list:
centent = i.text.strip() #获取内容文字
text.append(centent)
content_text = '\n'.join(text)
img_list = html.select('img._j_lazyload') #图片列表
img = ['\n']
for n in img_list:
src = n.get('data-rt-src') #获取图片路径
img.append(src)
img_src = '\n'.join(img)
#去除名字中的非法字符
res = r"[\/\\\:\*\?\"\\|]" # '/ \ : * ? " < > |'
title = re.sub(res, "_", title) # 替换为下划线
# print(title,name,brief,content_text,img_src)
item = {
'title': title,
'name': name,
'brief': '\n'+ brief,
'content_text': content_text,
'img_src': img_src,
}
storage(item)
#存储函数
def storage(item):
# 以文章标题命名存成TXT
with open('./mafengwo/' + item['title'] + '.txt','w',encoding = 'utf-8') as f:
txt_list = []
txt_list.append(''.join([item['title'], item['name'],item['brief'],item['content_text'],item['img_src']]))
f.writelines(txt_list)
if __name__ == '__main__':
getpage()
文章来源:知乎

《Python网络爬虫》给大家介绍各种复杂爬虫的设计,怎样部署分布式爬虫,怎样对付反爬技术,怎样识别图形,自然语言处理技巧等,化身机器蜘蛛,瞬间抓取海量数据进行探究。点击下方二维码报名课程







