在技术圈,存在互相鄙视的现象,比如搞C语言的鄙视C++,搞JAVA的鄙视C#。
为什么会互相鄙视呢?
其实就是羡慕嫉妒别人呗,比如某程序员工资比自己更高,就会无形之中产生鄙视的心态。
要说工资高,「刚毕业年薪40w」「5年就年薪百万」,这样的故事想必你肯定听说过。
薪资高
、
机会多
、
缺口大
,让大数据在开发圈里成了香饽饽,BAT、TMD 各大厂都开出高薪疯狂抢人。
但,与此同时,在我做公众号的这两年,目睹了太多人「从入门到放弃」,甚至有些人连大数据的门都没进来。如果你也在考虑跳槽换一份高薪的工作,不妨看看你是哪一种?
想转行大数据,苦于入行无门......
自学了一阵大数据,只学到了皮毛不说,根本没有数据库去模拟存储计算,简历上也只敢写「了解」某某技术,最后连份工作都找不到。
在中小企业做了一段时间大数据,但是只做大数据全流程中的一小块工作,对整个流程啊、怎么选型都没啥概念,而且公司的数据量级也不够,跳槽到大厂很难。
上面这几种情况,一看就是
没经历过真实项目
,也
没有受过系统训练
导致的,我们做大数据的薪酬是高,但门槛也是高,因为不管你是什么级别,所需要的技术栈你都应该用过,否则,别说大厂了,进中小企业都难。
那么,大数据究竟怎么学?今天,跟大家聊一聊我的学习路径和方法。
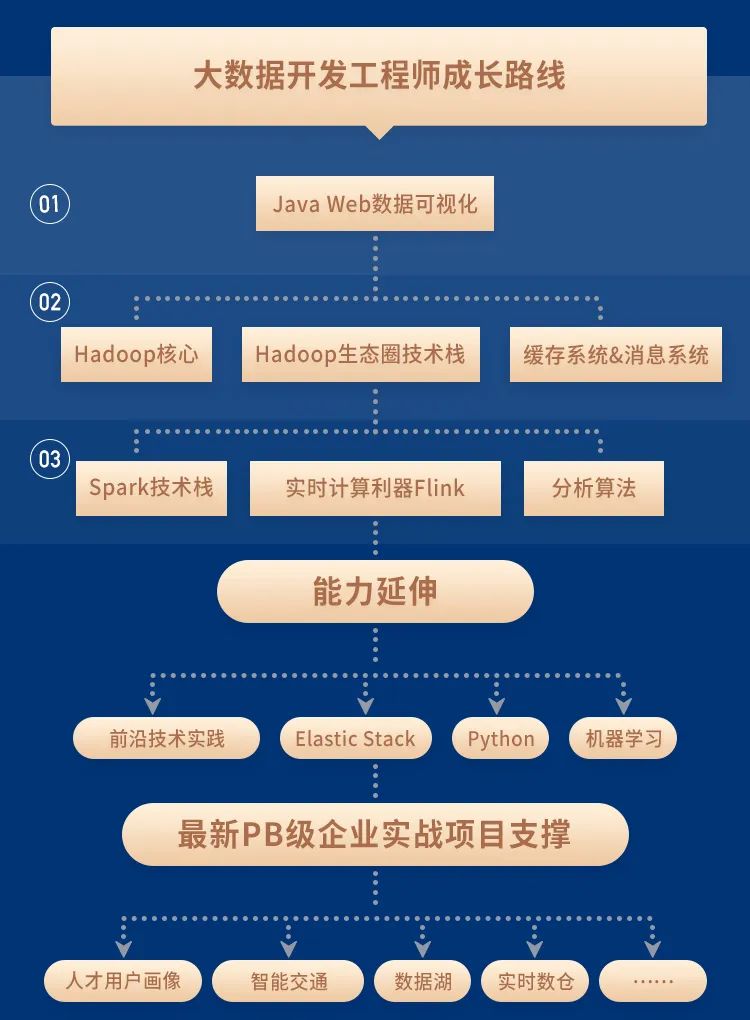
第 1 阶段,掌握Java Web数据可视化
。你需要掌握Java服务器端技术,前端可视化技术,数据库技术,这个阶段主要是储备大数据的前置技能,当然你已经可以从事数据可视化工程师的工作了,但还不能算真正入门大数据。
第 2 阶段,学会 Hadoop 核心及生态圈技术栈
。这部分涵盖的技术比较多,像 HDFS 分布式存储、MapReduce、Zookeeper、Kafka等你都得掌握,掌握后可以去从事 ETL 工程师等一些大数据的岗位,但是知识储备还不够完整。
第 3 阶段,搞定计算引擎及分析算法
。计算引擎我建议是 Spark 和 Flink 都能熟练使用,虽然现在一些企业还在用 Spark,但未来 Flink 一定会成为主流。学到这,你已经具备相对完整的大数据技能,能从事一些高薪的岗位了,像大数据研发工程师、推荐系统工程师、用户画像工程师等。

想靠自学掌握这些,纯属是白费工夫。那报个班学吧,市面上的课程水平参差不齐,内容就是蜻蜓点水,项目也基本上是 demo 型的案例,掏了钱学习还没啥效果。
我也接触过一些大数据的课程,要说良心还属
拉勾教育
。
拉勾
大家都知道,深耕招聘领域多年,在“人岗匹配”的过程中,发现很多人才的知识能力体系与企业的用人需求存在偏差。在充分调研大数据开发岗位招聘需求(拉勾独家数据统计)的前提下,拉勾教育团队精心打磨 12 个月后正式推出《
大数据开发高薪训练营
》。
它很好的解决了上面的两大难题:
更重要的是
签订内推就业协议
,优秀学员还可以
每个月内推一次。

下面说说拉勾这门课程的
4
个优势:
1、结合 90 万+企业用人需求,深度打磨课程体系
拉勾网 CTO
亲自参与课程设计,内容覆盖大数据处理的全流程技术栈,包括前面提过的Java Web数据可视化、Hadoop 核心及生态圈技术栈、计算引擎及分析算法、最新大数据技术、机器学习等
14
大阶段,让你吃透大数据开发。
在课程深度上,从教会你入门使用,再到源码剖析,再到真实的项目中应用,5 个月学习时间,带你
积累 3 年大数据开发经验
。

2、当下最火热 PB 级真实企业项目,带你搞定实战难题
市面上很多机构的所谓的项目,是七拼八凑出来的,数据量级小不说,走马光花的跟着做一遍,也没有效果。而拉勾不同,项目都是拉勾自己的真实项目和合作大厂的项目,保证了「
PB级数据
」和「
项目真实性
」。
项目会带你完整的经历一遍大数据处理的全流程,包括需求、分析、架构设计、模型设计、技术选型、开发流程、开发规范、测试过程、部署监控、项目调优等。还原实际企业的工作场景,
带你从 0 到 1 积累实战经验
。

线上学习、真实项目练习、定期测试、班主任监督、作业批改,这一切都是为了保障你跟的下来、学得会。

4、每月内推 + 面试辅导,帮你斩获高薪offer
最后不得不提到的是拉勾独家内推通道:
优秀学员每月内推,直接跳过投简历、笔试
,直通BAT等一线互联网公司面试官。
拉勾将求职过程拆解成 4 个部分:专项能力突击、简历优化、面试技巧、大厂内推。在求职过程中,拉勾就像是你的“
幕后推手
”,在每个环节为你提供专业助攻。

正是因为有强大的拉勾招聘后台,报名之后拉勾教育可以直接敢和学员
签订就业协议
,学有保障。










