北京时间 2017 年 9 月 3 日,华为在 IFA 2017(柏林国际电子消费品展览会)上,发布了第一款国产 AI 芯片:麒麟 970,华为公司消费者业务部门 CEO 余承东指出,“着眼于智能手机的未来发展,我们即将迎来令人兴奋的全新时代。移动 AI= 设备上 AI+ 云 AI。”今天,我们将为各位读者盘点包括麒麟 970 之内的,目前世界范围内几款热门或新型的 AI 芯片产品。 就目前的发展情况来说,芯片的应用大概有两个方面:一个是用于 HPC,也就是高性能超级计算机,俗称“超算”;另一个是用于终端,比如手机,更注重低功耗,对计算能力的要求不是特别高。
而就在前不久,微软和英特尔也相继推出了用于深度学习的硬件产品:脑波计划和 VPU。不难看出,在 AI 快速发展的时代,不仅软件技术要强大,硬件实力也要跟上才能角逐发展之巅,AI 硬件产品正在逐渐发展成为下一个 AI 的主战场。
从华为的麒麟 970 芯片开始吧。
IFA 2017 大会上,华为公司消费者业务部门正式为智能手机创新领域的全新时代拉开帷幕。身为部门 CEO 的余承东在主题演讲当中公布了麒麟 970 芯片以及与之紧密相关的华为人工智能未来发展愿景。
麒麟 970 芯片——内置有 AI 计算功能的全新 OEM 旗舰级系统芯片方案。尽管在 CPU 与 GPU 配置等方面皆迎来重要升级,但麒麟 970 芯片最为亮眼的特性无疑在于 AI 计算平台层面。

这款 AI 平台采用专用型神经处理单元(简称 NPU),其在本质上属于负责运行神经网络的底层硬件。与麒麟 970 搭载的 CPU 相比,其 NPU 可提供高达 25 倍的性能表现与 50 倍的执行效率。换言之,麒麟 970 NPU 能够以更快速度与更低功耗完成同一 AI 计算任务。举例来说,在进行基准图像识别测试时,麒麟 970 每分钟能够处理 2000 张图片,其速度相较于利用 CPU 处理同一工作负载可提升约 20 倍。
在处理 AI 计算任务(其在本质上属于一类超级计算用例)时,最为关键的基准在于处理器的每秒浮点运算执行能力。华为公司宣称,在采取 16 位浮点数值(即 FP16)时,麒麟 970 的 NPU 可实现每秒 1.92 万亿次(即 TFLOPS)运算。FP16 与 FP8 在 AI 领域当中的神经网络场景下的使用范围正愈发广泛,而且一大特性在于浮点运算值不需要非常精确(即不需要取小数点后太多位)。这意味着 FP16 与 FP8 运算能力甚至比完整的 32 位或 64 位浮点数值运算更加重要。
关于这款全新旗舰芯片的其它特性,其首次利用 10 纳米制程工艺由台积电公司负责制造。这是一款 8 核心处理器,配备有 12 核心 GPU、双 ISP 以及高速 Cat 18. LTE 解调器。CPU 选项与麒麟 960 相同,采用 4 个 ARM Cortex-A73 核心外加 4 个 ARM Cortex-A53 核心,但这一次二者的时钟速率被分别提升至 2.4 GHz 与 1.8 GHz。麒麟 970 也将成为第一款采用 ARM 最新 GPU Mali-G72 的商用系统芯片。根据华为公司的说明,G72 的加入使得麒麟 970 在速度上较麒麟 960 提升 20%,但功耗则降低至后者的仅一半。
其它值得强调的重要特性还包括支持 4K 视频解码 / 编码(H.265、H.264 等等)、10 位彩色处理能力(HDR10)、下一代华为传感器处理器(i7)以及 32 位 /384K DAC。与上一代麒麟 960 一样,本次发布的 970 同样支持双摄像头、UFS 2.1 以及 LPDDR4(但现在的频率提升为 1833 MHz)。
为了帮助各第三方运用新款旗舰芯片中的 AI 功能,华为公司希望将麒麟 970 打造为一套“面向移动 AI 的开放平台”,这意味着其将把该芯片组开放给开发人员与合作伙伴,供其利用强大的处理能力寻求新的创新型使用方向。为了实现这一目标,麒麟 970 能够支持 TensorFlow/Tensorflow Lite 以及 Caffe/Caffe 2。
再来说说微软。
作为世界知名科技大厂,微软在 AI 上可以说是下足了功夫,除了总部的 AI 研究院以外,还在中国专门成立了微软亚洲研究院。不仅在软件上发力,推出了小冰、小娜这样的智能对话机器人,还有 CNTK 这样的深度学习框架供广大 AI 开发者们使用。
就在 8 月 23 号, 在 Hot Chips 2017 上,微软 AI 研究团队推出了一款深度学习加速平台,名曰脑波(Brainwave)。
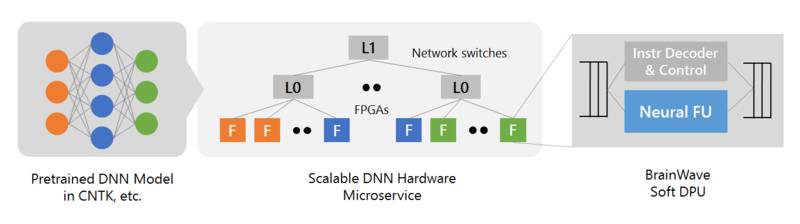
脑波计划系统的主要内容包括以下三个层面:
因为今天的文章主要是谈智能芯片,所以咱们就来详细说说这款:DPU。
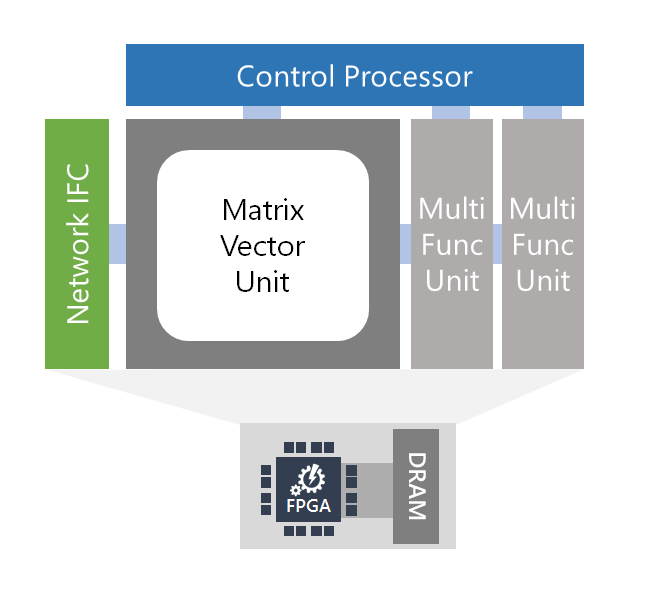
官方网站上这样说:脑波计划使用了一个强大的可以商业化应用的 FPGA 上合成的「软」DNN 处理单元(DPU)。大量的公司,包括大型公司和大批初创公司,都在构造硬化 DPU。尽管其中一些芯片具有高峰值性能,但必须在设计时选择运算符和数据类型,灵活性受到了限制。脑波计划采取了另一种方法,提供了一个可在一系列数据类型上缩放的设计。该设计结合了 FPGA 上的 ASIC 数字信号处理模块和可合成的逻辑,以提供一个更大更优化数量的功能单元。
这一方法使用两种方式利用 FPGA 的灵活性:
首先,定义了高度自定义、窄精度(narrow-precision)的数据类型,无需损失模型精度即可提升性能。
第二,可以把研究创新快速整合进硬件平台(通常是数周时间),这在快速移动的空间中至关重要。研发团队称,已经能够取得了可媲美于甚至超过很多硬编码(hard-coded)DPU 芯片的性能,并在当天兑现了性能方面的承诺。
VPU,视觉处理器(Vision Processing Unit),由 Movidius(已被英特尔收购)开发,该公司所推出的 Myriad 系列 VPU 专门为计算机视觉进行优化,可以用于 3D 扫描建模、室内导航、360°全景视频等更前沿的计算机视觉用途。
英特尔最为大家所熟知的产品应该是 CPU,但是随着人工智能技术的不断进步,想要发展就得突破创新。况且,就计算速度上来说,英伟达的 GPU 目前仍然是领跑世界的水准,或许是为了赶超英伟达,或许是为了证明自己转型 AI 的决心,美国时间 8 月 28 日,英特尔推出了新一代 Movidius ™ Myriad ™ X 视觉处理单元(VPU)。
Myriad X 是全球第一个配备专用神经网络计算引擎的片上系统芯片(SoC),用于加速端的深度学习推理。
据了解,这款处理器将主要用于基于视觉的设备的深度学习和 AI 算法加速,比如无人机、智能相机、VR/AR 头盔。所配备的专用神经网络计算引擎是芯片上集成的硬件模块,专为高速、低功耗且不牺牲精确度地运行基于深度学习的神经网络而设计,让设备能够实时地看到、理解和响应周围环境。

目前官方资料对这款 VPU 的技术给出这样的解析:
Myriad X 可以提供超过 4 TOPS 2 的总体性能表现,其微型的尺寸和板载处理能力非常适合自主设备解决方案。除了神经计算引擎,Myriad X 通过如下方式独特地实时整合了成像、视觉处理和深度学习推理:
可编程 128 位 VLIW 向量处理器:通过为计算机视觉工作负载而优化的 16 个向量处理器可以灵活地同时运行多个成像和视觉应用流水线。
增加可配置的 MIPI 通道:通过其一套丰富的接口和 16 个 MIPI 通道,可以把多达 8 个高清 RGB 摄像头直接连接到 Myriad X,从而支持最高每秒 7 亿像素的图像信号处理吞吐量。
强化的视觉加速器:利用超过 20 个硬件加速器来执行光流和立体深度等任务,而不需要额外的计算开销。
2.5 MB 的多核异构同质片上内存:集中化的芯片内存架构最高支持每秒 450 GBytes 的内部带宽,通过尽量减少芯片外部数据传输进而最小化数据访问的延迟并降低功耗。
Myriad X 是最新一代 Movidius VPU,专为嵌入式视觉智能和推理开发设计。Movidius VPUs 通过整合三种架构能够在低功耗的情况下实现高性能,从而为深度学习和计算机视觉工作负载提供持续的高性能:
(1)一组可编程 VLIW 向量处理器,其中的指令集为计算机视觉和深度学习工作负荷进行了优化;
(2)一套硬件加速器可以支持图像信号处理、计算机视觉和深度学习推理;
(3)通用的智能内存结构,用于把芯片上的数据搬移量降至最低。
来自谷歌的张量处理器(Tensor Processing Unit),官方发布的内部结构图如下图所示:
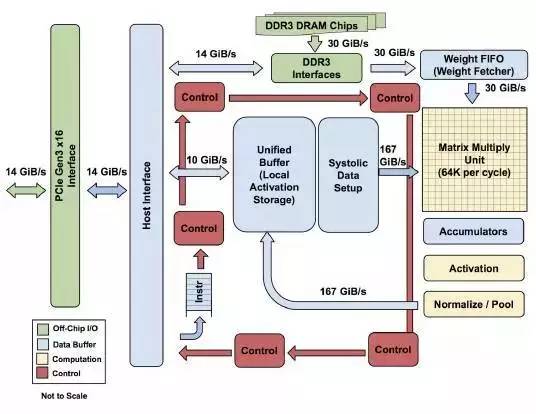
2016 年 AlphaGo 击败人类棋手李世石,又在一年之后的乌镇击败柯洁,TPU 的出现给整个芯片行业带来了不小的冲击,尤其是今年 I/O 大会上推出的 TPU-2,第二代 TPU 基础设施提供多达 256 个芯片,它们连接在一起可以提供 11.5 千兆次的机器学习运算能力。

更多关于 TPU 的内容,我们在谷歌 I/O 2017 大会期间做过相关报道,有兴趣的读者可以点击回顾:
一篇文章深入解读 Google I/O 上重点提到的 TPU
下面说说 GPU,图形处理器(Graphics Processing Unit)。
GPU 的概念由英伟达公司在 1999 年提出,之前最大的需求是来自 PC 市场上各类游戏对图形处理的需求,随着 AI 技术的发展,GPU 目前也在超级计算机平台上有十分重要的应用:比如针对自动驾驶的 DRIVE 系列,以及专为 AI 打造的 VOLTA 架构。
这里有一段官方视频,可以看到 GPU 这么多年来的变化:
之前,我们也做过关于英伟达 GPU 的在线课堂内容,感兴趣的同学可以回顾。
相比于传统的计算密集型 GPU 产品来说,英伟达努力的方向是使得 GPU 芯片不仅仅只针对训练算法这一项起到作用,更是能处理人工智能服务的推理工作负载,从而加速整个人工智能的开发流程。
目前市面上的智能硬件当然远不止这么几种,我们选取了热门和新型的硬件进行了盘点。科技企业在智能硬件上的投入愈发迅猛,智能芯片的迭代速度也是越来越快,新型产品不论是计算速度还是处理性能都相较上一代产品有了很大提升。智能硬件也许就是下一块兵家必争之地,技术人们的不断努力带来了一个又一个惊喜,未来还会有什么样的智能硬件产品出现,我们十分期待。
关注 AI 前线公众账号(直接识别下图二维码),点击自动回复中的链接,按照提示进行就可以啦!还可以在公众号主页点击下方菜单“加入社群”获得入群方法~AI 前线,期待你的加入!










