1. 前言
爬虫,这个词很多朋友第一次听到,第一感觉应该是各种小虫子,应该不会和某种计算机技术联系在一起。我第一次听到这个词,就是这样一个感觉。但是当这个这个词前面加了网络二字时,瞬间勾起了我的兴趣,当然也带来了疑问。比如,网络爬虫是什么?有什么用?后来带着强烈的兴趣和疑问,查询了很多资料,以求搞清除我的疑问。当我的疑问被解决的解决之后,怀着对爬虫技术崇敬的心情做了一个决定,我要实现一个属于自己的爬虫程序。
在我做这个决定的时候,时间节点是大三上学期期末。后来,过完寒假,到了大三下学期。我在大三下全学期用了3个月的时间,设计并实现了自己的爬虫,并且花了5天的间用自己写的爬虫采集了100万个网页。这是我第一次与爬虫技术亲密接触,总体感觉良好,学到了很多东西。
到了大四上学期的期末,到了论文选题的时候了,我选了一个关于全文搜索引擎的论文题目,论文对应的程序由爬虫和搜索两个模块组成。其中爬虫直接用的开源实现 WebMagic,不过由于 WebMagic 不符合我的需求,所以我对 WebMagic 源码进行了一定的改动,以保证爬虫按照我的要求来执行任务。这是我第二次接触爬虫技术,当时感觉也不错,改了别人的源码,并且新加了一些新东西。改造完别人的爬虫不久之后,就毕业了,大学生活也结束了。
以上,是我大学时候所接触过的爬虫技术。当我参加工作后,我所在的公司也有爬虫,我也需要经常使用。所以从大三下开始接触爬虫到现在,算起来也有两年半的时间了。
这两年多来,从大三开始自己写爬虫,大四改造别人的爬虫,到现在用公司的爬虫。我在爬虫方面多多少少还是积累了一些经验,也有一点感触吧。看着自己以前写的爬虫的截图,还是蛮感叹的,时间过得真快啊。所以本篇文章我将把我这两年多使用爬虫的经历写出来,不过仅仅是记事,不会介绍爬虫相关的原理。接下来我会按照时间顺序依次叙述我的爬虫经历,好了,开始吧。
2. 偶遇爬虫
我在大三上学期期末的时候,开始在自学 Python。当时感觉 Python 还是比较容易的学的,但是通过看书学习的话,基本上看完就忘。对此,我也是颇为苦恼。于是后来总结原因,觉得是自己代码写的太少,以至于记不住语法。所以就寻思着写一个稍微复杂的 Python 程序,这样才能熟悉 Python。于是乎上网找练手项目,找了一圈,多数人都是推荐用 Python 写爬虫。但当时觉得爬虫技术很复杂,所以内心还是比较拒绝的,不过既然大家都建议用 Python 写爬虫,那就硬着头皮上吧。于是,在一个风高月黑的夜晚,入坑了。
在我开始准备写爬虫的时候,脑子真是一片空白。在此之前,我从来没接触过爬虫相关的技术,也没用过爬虫框架。在准备阶段,我查了不少资料,也写了很多小例子。准备工作结束后,我对爬虫相关的原理有了较为清晰的认识了,对 Python 的网络相关的库也相对熟练了很多。于是很有自信的开始规划爬虫的编码计划,按照原计划,预计耗时一个半月可以完成爬虫的编码工作。
不过在真正动手写代码之后,深深的体会到了“理想很丰满,现实很骨干”这句话的含义。由于当时没有经验,编码过程中犯了很多错。从一开始的技术选型到实际编码过程中,自己给自己挖了一个又一个的坑。比如在技术选型阶段,选择了一个难度比较大的并发模型,直接提升了开发难度。
另外,在编码的过程中,也犯了一个比较大的错误。即在第一版实现还没发布前,不断的加入新功能,导致第一版的爬虫迟迟出不来,项目最终延期。最后我耗费了3个月的时间,才把第一版的爬虫发布出来,比预计时间多出一倍。当然,尽管犯了很多错,但最终还是完成了编写爬虫的计划。总的来说,收获还是很大的。
后面我会把第一版爬虫所实现的功能点列出来,不过在列之前,先来看看当时爬虫的一些设计图。
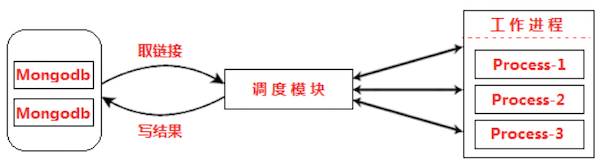 图1 爬虫并发模型:多进程+协程
图1 爬虫并发模型:多进程+协程
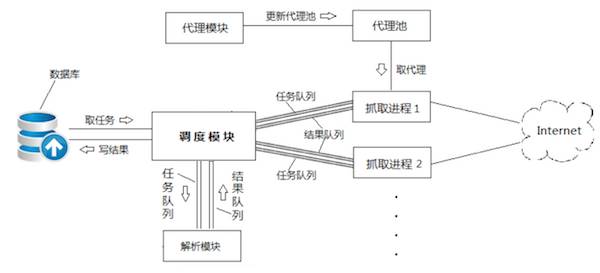
图2 爬虫结构图
下面来罗列一下第一版爬虫实现的功能:
-
实现了两种抓取模式,一种是全网抓取,一种是整站抓取
-
为了避免 Python GIL 锁成为效率的羁绊,选择了效率恐怖的多进程加协程作为并发模型
-
为了避免 IP 被 ban,实现了一个代理模块,每个30分钟从代理网站上抓取新的代理 IP
-
为了避免爬虫奔溃导致状态丢失,实现了一个爬虫状态的备份机制,每10分钟备份一次
-
为了避免爬虫陷入某个网站无法自拔,遂实现了爬虫爬行深度的功能
-
自己造轮子实现一个了 URL 正规化的模块
-
实现了一个 URL 相似性判定模块,减少对相似的 URL 进行抓取,提高效率
-
Python 调试器 PDB 无法调试进程,所以还要让爬虫支持远程调试
-
引入 PhantomJS 解析动态页面
以上功能点是我在编码过程中陆续加入的,这些功能的加入,直接导致了爬虫第一版实现工期严重延误。同时在编码的过程中我也踩了很多的坑,当然多数时候都是自己给自己挖的坑,这其中令我印象最深的坑非我选的爬虫并发模型莫属了。
上面说到了我选择多进程加协程作为并发模型,是因为担心 Python GIL 锁会限制多线程模型的效率。这个模型不用还好,用了之后感觉多太复杂了。首先使用多进程增加了调试的难度,必须要使用远程调试。其次如果使用协程,基本可以告别调试了,协程调试起来很容易乱掉,所以只能靠打日志。这都不算什么,最坑的是当时我代码中的协程逻辑不按照预期运行,协程切换很诡异,调试了三天也没找到原因。最后实在没办法,上网求助。
最后在知乎上找到了一个 Python 大神,请他在他的电脑上运行我的代码,看看是否正常。结果他那边回邮件说正常,并将打印的日志截图给我。这个就让我很郁闷了,最后这个问题怎么解决的我也忘了,应该是改代码规避了。还有其他一些坑,这里就不多说了。
上面唠唠叨叨的说了很多,不过这仍然不是全部,还有很多细节我已经想不起来了。接下来,给大家看看我当时写的爬虫的样子吧,很简陋,见笑了。
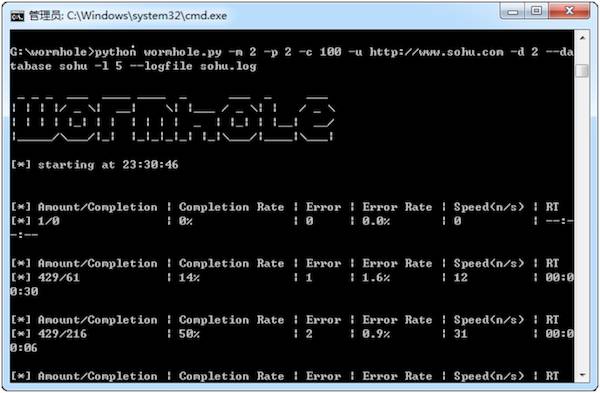
图3 爬虫启动界面
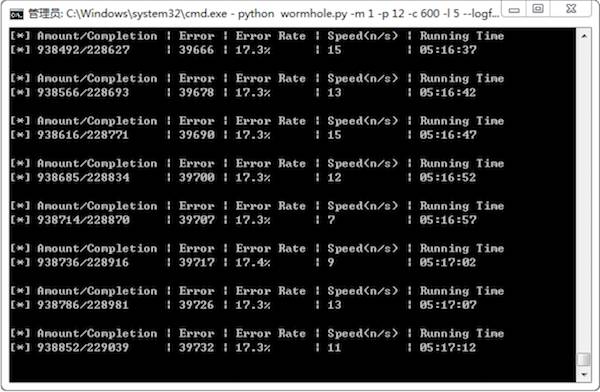
图4 爬虫运行界面
大家可以看到“图3 爬虫启动界面”中的 wormhole 字样,wormhole 也就是我的爬虫名称,这个是我一个字母一个字母敲出来的。图4是在爬虫运行了5个小时之后截取的,里面包含了任务总数、完成的任务数、采集失败的页面数量和比例、以及当前的采集速度等的。现在看看这两张图,内容虽间简陋,但感觉还是很亲切的。
另外,在爬虫完成抓取任务后,我还煞有介事的对采集到的数据进行了一些简单的分析。比如不同网站服务器所使用的操作系统,脚本语言以及服务器软件分布比例等。如下:
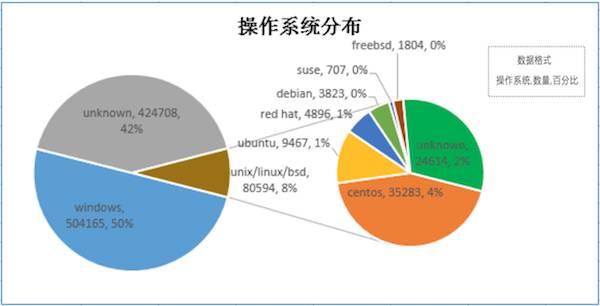
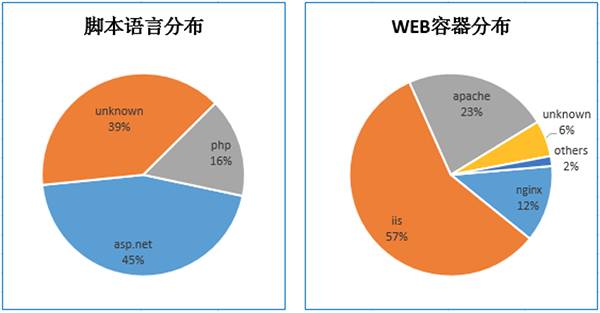
图5 数据分析
上面的数据分析是依赖于消息头进行的,结果并不精确,所以参考价值不大。当然,如果只是简单玩玩,也还是有点意思的。
以上就是我与爬虫技术第一次亲密接触的过程,这次的接触,令我印象深刻。在编写爬虫的过程中,不但达到了最初的目的--熟悉 Python 编程,也顺带学习了很多技术。比如 MongoDB、Bloom Filter、协程等等。尽管写这个爬虫耗费了我三个月时间,但从最后的收益来看,这笔投资还是很值得的。如果用大学里经常听到的一句话总结,那就是:“这波不亏”。
好了,偶遇爬虫篇,就先说到这了。接下来再来说说大四的利用爬虫做毕业设计的事情。
3. 改造开源爬虫突击毕业论文
时间过得很快,在我写完自己的爬虫不就,大三就结束了。紧接着到了大四,大四上学期快结束时,我们要进行毕业论文选题了。对于毕业论文选题这个事情,我当时的想法很简单。一定要选一个看起来稍微复杂一点的论文,然后认真完成,并以此论文来为我的大学生活画上句号。所以思考良久,最终选了基于 Lucene 的全文搜索引擎作为毕设。当然选完之后,我就开开心心的跑出去实习去了,没再管它了。以至于在毕业答辩的前一个半月,答辩老师让我们提交答辩申请表的时候,我才想起来还有毕业论文和设计没准备这回事。于是这就悲剧了,总共一个半月的时间,要留一周的时间进行论文查重和修改,同时答辩前一周还要提交论文最终版,所以真正留给我做毕业设计的时间只有一个月。当时真是急死了,于是最后和公司申请在上班时间写毕业设计,好在公司答应了我的申请,就这样我用了一个月的完成了毕业论文和设计。
前面说了,我的毕业论文是关于全文搜索引擎的。看起来并不复杂,调调 Lucene API 就好了。但是,搜索引擎需要数据,而数据又需要拿爬虫去采集。所以我的毕业设计里不止要实现搜索逻辑,还要附带实现数据采集逻辑。当然由于时间紧急,加上大三写的爬虫跑不起来了,所以就直接找开源的爬虫框架采数据了。
找了一圈,最终选定了黄义华大神写的 WebMagic 作为我的数据采集工具。尽管当时 Nutch 爬虫是更好的选择,但是 Nutch 还是比较复杂的。为了防止出岔子,就选了文档比较全的 WebMagic。不过考虑到 WebMagic 工作模式不适合为搜索引擎采集数据,为了能让 WebMagic 符合我的需求,所以后来我对 WebMagic 源码进行了一定的改动。
这样它就能同时采集很多个网站的数据,并且在发现新的网站后也会放在任务队列中,而不是像以前那样直接过滤掉。在 WebMagic 改造工作接近尾声时,我用 ExtJS 为 WebMagic 做了简陋的后台管理界面,方便我对采集过程进行监视。至于当时我是怎么改动 WebMagic 源码的,这里就不细说了,我也忘记了。关于改造 WebMagic 的事情就说到这里,下面来看看爬虫的结构图以及管理界面:
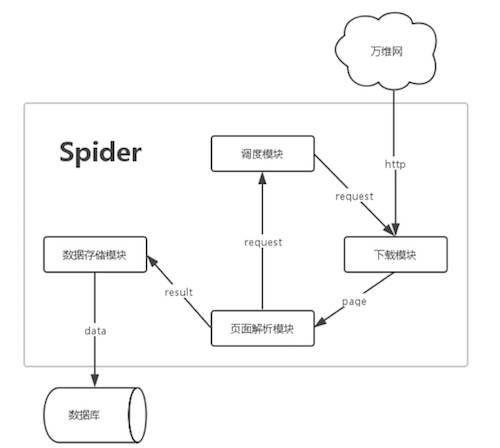
图6 爬虫结构图

图7 毕业设计爬虫模块运行界面图
最后在上两张毕业设计搜索模块的界面,如下:

图8 搜索引擎首页
图9 搜索引擎结果页
以上是我在做毕业设计时,所接触过的爬虫。虽然并没什么亮点,但是在一个月内的时间里,改造别人的开源爬虫,并采集20W条数据,紧接着编写搜索逻辑,最后写毕业论文。整个过程到现在想想,仍然还是很刺激的。好在最后完成了,最终也达到了选题的初衷--通过认真完成毕业论文和设计,为大学生活画上句号。
4. 维护公司爬虫
大学毕业之后,我又是回到了先前实习的公司,并在拿到毕业证后转正了。由此,我的工作生涯开始了。
我们公司是以给客户提供搜索服务起家的,既然是搜索服务,自然也离不开爬虫。公司的爬虫和业务贴合的比较近,相对于通用爬虫来说,公司定制的爬虫还是要复杂的多。拥有很多通用爬虫没有的功能,比如对列表页和详情页的识别、对网页正文的抽取(类似印象笔记的剪藏插件)等。同时,不同于通用爬虫,我们很多时候在采集客户的数据(客户不对我们开放数据)时,经常需要处理各种由 JS 渲染的分页以及 Ajax 请求等情况。这类数据爬虫采集不了,这时候就需要人工参与了。怎样让人和爬虫协作,这也不是个简单问题。我们公司的爬虫参考了 Nutch 的设计思想,所以也为爬虫实现了一个插件机制,这样就解决了人和爬虫协作的问题。当然具体怎样实现的,这里就不说了,详细可以参考 Nutch 的插件机制。
在我来到公司之前,公司的爬虫就已经存在了。在我一开始工作的时候,感觉公司的爬虫还是很高大上的,看起来挺复杂的。不过现在看来,也就一般了。设计思想还可以,但易用性不佳。很多可以自动化解决的问题,居然一直都是以人工的方式处理的。举个例子,有一次,我们公司的运维要检查爬虫抓取的数据是否完整。于是他按照惯例到客户的网站上,从不同的栏目里复制几条数据的 URL。然后再将这几条 URL 一条一条的复制到爬虫控制台的搜索框中,看看能不能查找这条 URL 的采集记录。这个过程相对来说还是比较繁琐的,特别检查多个网站数据的数据采集情况时,尤为的繁琐,效率十分低下。所以后来我实在看不下去了,就写了一个 chrome 插件,并在爬虫后台开放一组接口。这样利用插件将页面中的 URL 批量发送给后台,后台检测完后,再将结果返回给 chrome 插件。插件根据检测结果,把未爬虫采集的数据标题标红,并加上删除线。这样哪些数据未被采集,一目了然,再也不用手动检查了,效率也大大的提高了。
公司现有的爬虫平台已经比较老了,有两三年了,目前看来已经无法满足业务的需求了。虽然当时在设计上参考了 Nutch 的实现,但也只借鉴了思想,并未借鉴 Nutch 的实现。加之设计之初的技术选型有问题,选用了一些比较底层的技术,导致维护起来很困难。这里并不是说底层技术不好,而是我们公司没把它用好。所以公司的爬虫自从写出来后,几乎没更新过,只是偶尔打个 patch,仅此而已。所以大家在做技术选型的时候,好事要慎重考虑,不然以后维护工作是个大麻烦。关于公司的爬虫就说到这里,保密原因,这里就不贴图了。
5. 写在最后
以上就是我这两年多学习并使用爬虫的历程,虽无什么亮点,但是对我来说却会比较难忘。从以前不知爬虫为何物,到今天可以用爬虫做很多事情。总的来说,还是有比较大的进步吧。当然,我并不非专业的爬虫工程师,使用爬虫也只是平时工作的一部分而已。不过即使如此,我仍然觉得数据采集工作并不是个轻松的差事,很繁琐。当然了,现在除了工作需要,其他时间我几乎不会再关注爬虫技术了。我并不打算成为爬虫工程师,所以这方面的技术够用就行了。也因为此,写下这篇文章记录自己的过往经历,也算是给自己的爬虫之路画上一个句号吧。over!
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。
欢迎关注 SegmentFault 微信公众号 :)





