课题设计决定文章的下限,数据挖掘决定文章的上限。
——沃林老师
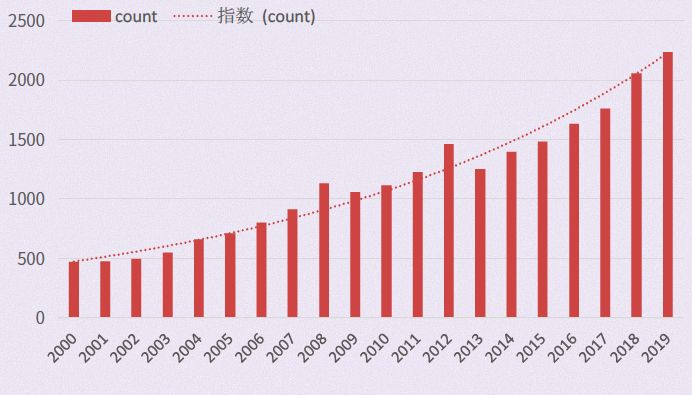
从 Pubmed 数据库搜索的结果来看,自 2000 年,数据库的数量呈指数上升,迄今已经有超过了 2000 个数据库了。
数据越来越多,方向就越来越广。上千个数据库,给我们带来了挖不完的宝藏。面对这块不用花钱的大蛋糕,大家都想分一杯羹!
(图片来源:自己做的)
数据挖掘在医学研究中如何发挥价值?
价值一:提供医学研究基础
对一些刚刚开始做科研、没有明确方向的科研新手来说,数据挖掘可以提供一个相对正确且容易产出阳性结果的研究方向,实现从 0 到 1 的起步。
例如,这篇 IF = 23 的 Nature Immunology 的文章,选题起源就是来自数据挖掘。

(图片来源:Nat Immunol. 2019 Jul;20(7):835-851.)
作者利用了 TCGA 数据库里一个泛癌种的关联研究,确定了研究目标 LINK-A 可能和免疫微环境有关,进而展开了一系列详细的后续研究,得出了很好的结论。
如果没有数据挖掘提供的研究背景和研究方向,可能就做不出一篇如此精彩的论文。
价值二:给文章提供优秀的素材
很多医学研究通过数据挖掘、分析验证自己的结论,比如以下几个方面:
1. 预后验证:实际临床工作中随访工作较为复杂,且耗时耗力,但通过数据挖掘的方法,可以轻松验证患者预后。
2. 人群/物种交叉验证:数据挖掘可以实现不同地区的人群之间的对比,甚至不同物种之间的对比。
3. 提高过可信度:用自己已有的数据与公共数据库中的数据进行对比,呈现结论的时候,增加结果的可信度。
举个简单的例子:
这篇 Nature 发表的文章,就是将自己的数据与公共数据对比,验证自己的数据,从而突出自己研究的意义。
(图片来源:Nature. 2019 May;569(7757):560-564.)
价值三:零成本产出 SCI 文章
对于没有时间做临床试验的医生、医学生来说,数据挖掘可以做到:
不花钱、不做实验、不做实验发 SCI 文章!甚至,发很多篇 SCI 文章!
当然,数据挖掘需要技巧,通过数据挖掘发 SCI 需要正确的步骤:
(图片来源:课程截图)
第一步:筛「方向」
「筛」的关键在于研究对象的选择和研究方向的确定,一定要尽可能的找到一个有发表潜力的方向。具体可以从以下几点入手:
优先选择与临床意义相关的方向,比如免疫治疗、疾病进化或预后等;
参考自身研究领域内最新会议报告内容及基金申请结果;
参考最新的综述文献,用心细读,勤做笔记;
跟踪各类学术公众号的热点文章。
第二步:「挖」数据
「挖」就是一门绝绝对对的技术活了,这里有四大原则:
(图片来源:课程截图)
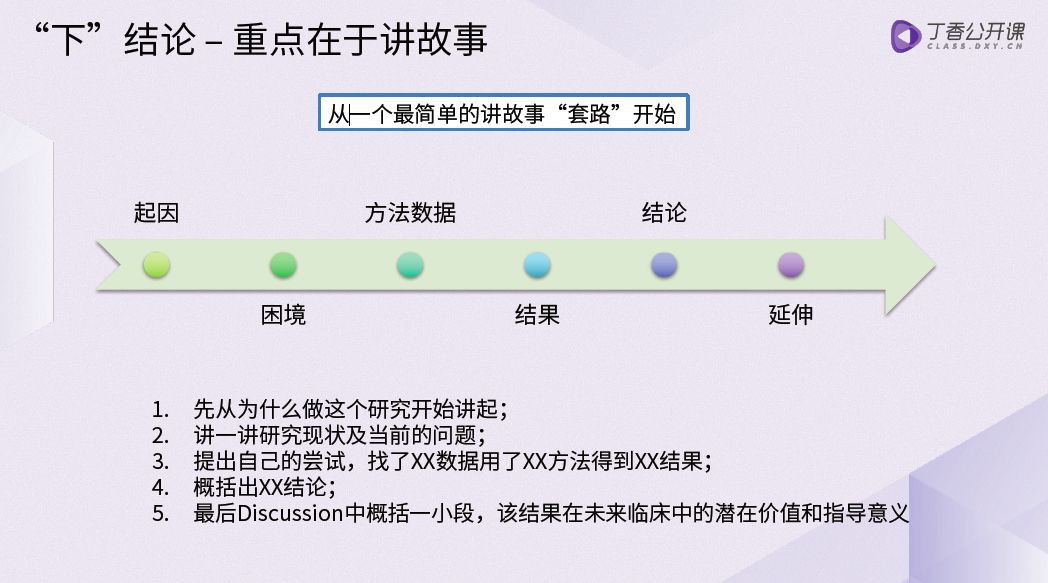
第三步:「下」结论
对于数据挖掘的文章,结论一定不要超过 3 句,避免结论过大过空。
(图片来源:课程截图)
除此之外,数据挖掘涉及到不同数据库的挖掘方法、不同数据的分析方法,真正学习和掌握数据挖掘,需要系统的学习。
丁香园特邀国内最先做单细胞测序的团队成员之一,沃林老师,开讲《零基础实用数据课程》。
沃林老师长期致力于研究高通量测序技术及数据分析,擅长生物信息学的数据挖掘及课题设计。累积发表数据挖掘类 SCI 文章 40+ 篇,其中 10 分以上达 5 篇。
课程现在还在内测预售中,我们精选出 3 节超高价值的精品课,特价送给数据挖掘零基础的同学们。
3 节精选课程 + 20 篇优秀数据挖掘论文 + 100 元代金券,仅需 1 元!
扫描海报二维码,加入内测预售,抢精品课程。
沃林老师的《零基础数据挖掘》课程涵盖了超过 15 个数据库挖掘的方法。
不仅有常见的基因分子数据库、预后数据库,还紧追热点囊括了单细胞、免疫细胞浸润、蛋白互作、蛋白表达等数据库。
结合已发表文章中的实际案列,手把手教会你如何分析数据才能发挥价值,学完真正能上手!
考虑到医生、医学生普遍没有编程背景,课程学习中的大部分结果都可以使用在线工具生成,学习操作毫无压力。
同时,我们还提供 R 包,手把手跟着操作,R 语言零基础也可以直接出图。
上下滑动查看课程大纲
点击查看大图
封面来源:站酷海洛 Plus
点击阅读原文,参与内测活动
先听课,再领券学习











