一、
NODE
简介
大规模高通量测序技术发展催生了生物医学,特别是组学研究的高速发展。使得对如此规模的数据进行存储、管理、统计和数据复用、数据共享就成为一个非常大的需求。同时如何将原始测序数据和对应的元数据有机结合起来进行存储、搜索、安全共享也是原始测序数据库设计中需要解决的问题。
NODE
作为一个组学数据管理和发布平台,围绕组学数据的生命周期,为数据产生(
Private
)、分析(
Share
)、发布(
review and public
)、(
request-response
)等各环节设计了相应的功能,为有数据存储、共享和分析需求的科研用户提供服务。
二、
NODE
设计
NODE
组学数据百科全书从设计之初就是能够对由高通量测序仪器直接下机得到的组学原始数据进行存储、兼容、整合、搜索、浏览、共享、分析等功能的平台。因此,
NODE
首先是一个生物医学大数据的汇交平台,平台设计的功能从前期实验的样本信息记录,到测序结果文件的上传,再到结果的分析,及原始数据和分析数据得共享和下载。
NODE
出于兼容
SRA
和
ENA
的考虑,将疾病相关的信息与样本信息相结合,同时保留项目、实验信息等。在数据和元数据层面,除了
SRA
和
ENA
原始支持的数据外,还增加了分析数据(
Analysis
)及其元数据的上传。整合设计后的
NODE
平台主要包含
6
个主要元数据模块:
Project
、
Sample
、
Experiment
、
Run
、
Data
、
Analysis
。
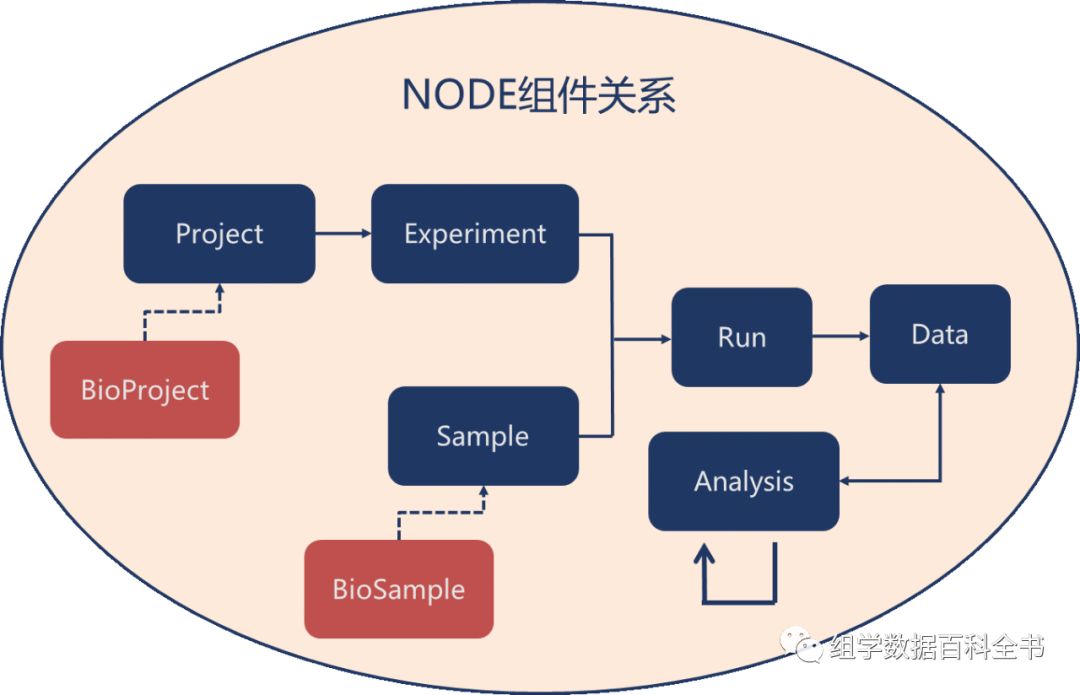
Project
:包含对一个研究的总体描述,包括项目名称、项目文本描述、项目地址、相关项目等信息。一个
Project
下关联有多个实验。
Experiment
:描述样本测序实验的相关信息,包括实验命名、实验描述文本信息、样本测序文库的构建及测序方法的相关信息等。一个
Experiment
只对应一个
Project
。
Sample
:描述生物实验材料的原始资料信息,包括样本的物种、组织、细胞系、保存方式、供应者信息、以及其他一些自定义信息。
Sample
与
Project
、
Experiment
没有直接关联关系。
Run
:描述了
Experiment
中的测序方法对
Sample
测序生成测序文件的一整套流程的描述信息,是大规模高通量测序的上机流程信息。一个
Run
唯一对应了一个
Experiment
和一个
Sample
,单端测试的一个文件为一个
Run
,双端测序的两个文件为一个
Run
。
Analysis
:基于原始数据进行研究分析流程及结果的描述信息,一个
Analysis
产出的结果可以用于其他
Analysis
的起始文件。在
NODE
数据归档时必须先选择归档到组学原始数据(
Raw Data
)或归档到一个分析(
Analysis
)。
三、
数据分层管理机制
为了让用户根据项目进展灵活的开放自己的数据权限,保障数据共享的安全性,
NODE
为用户提供了数据的分层管理机制。用户可以根据实际的数据发布进度调整数据的访问状态。
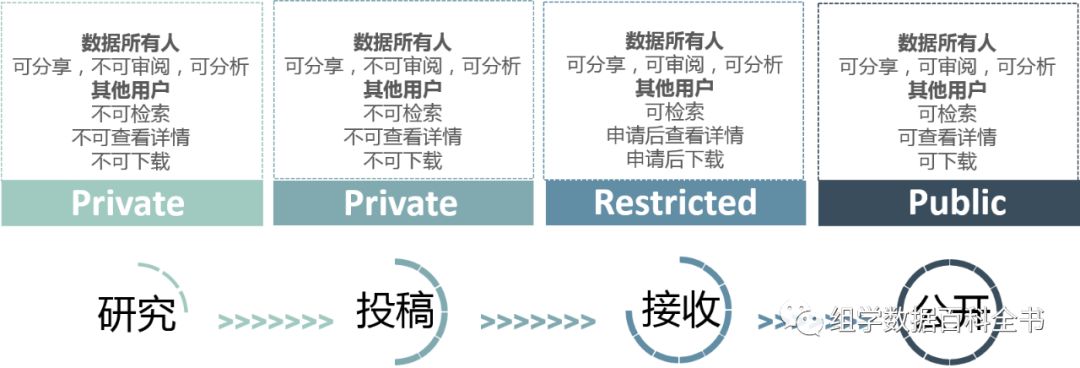
-
公开数据(
Public
):数据为
Public
状态时,其他用户可以检索并访问此类数据。
-
受限数据(
Restricted
):数据状态为
Restricted
时,其他用户可以在数据检索到此类数据,如果想看详情则需向数据所有人发出申请。数据所有人通过申请后方可访问
私有数据(
Private
):数据状态为
Private
时,其他用户无法检索及访问到此类数据。
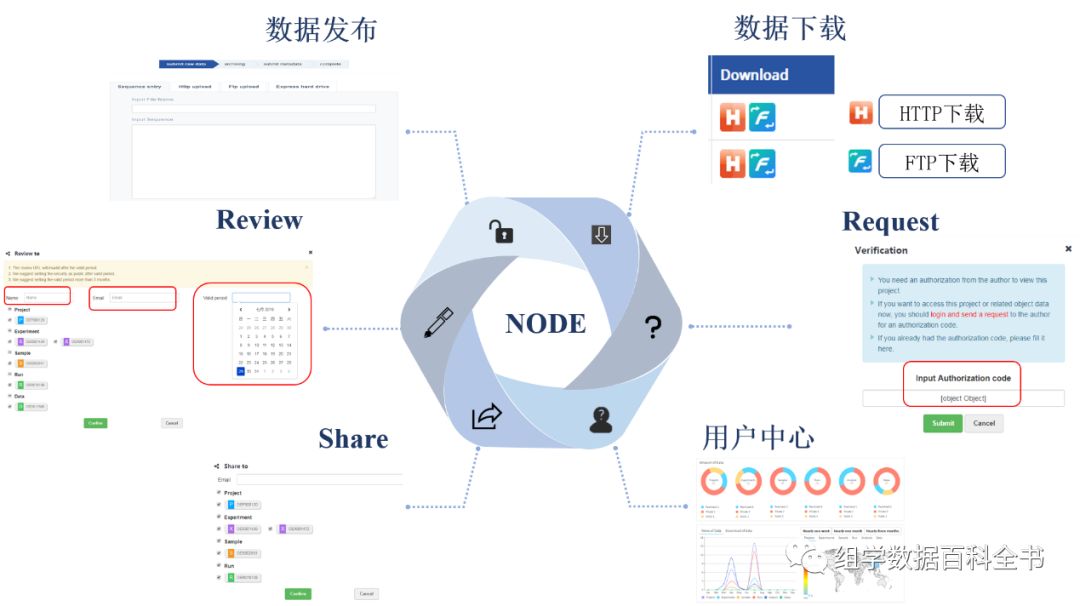
四、NODE功能
围绕数据管理和发布的各个环节,
NODE
为用户提供了相应的功能。
4.1
数据浏览及搜索
NODE
数据搜索是对
PB
级的组学原始测序大数据进行检索的核心功能和方法。如果说
NODE
数据归档为组学原始测序数据提供了数据基础,那么
NODE
数据搜索就为组学原始数据的查询和共享提供了基本方法。虽然数据归档生成的元数据是经过分类后的结构化数据,但经过不同数据表的存储后并不能形成统一的搜索界面,并且对各类数据字段的搜索在搜索语句上相对复杂,普通用户很难理解。因此,在设计上,
NODE
的搜索功能分为浏览和搜索两部分,并用相似的界面实现结果的展示。
首先是数据浏览,
NODE
在各数据页面的最上部设置了快捷方式导航条,用户只需选择需要的数据类型(
Project
、
Experiment
、
Sample
、
Run
、
Analysis
)就能实现对相应元数据的列表式浏览,浏览结果中包括了该类数据中已经公开发表和处于受限状态的所有元数据列表信息(私有数据不显示)。同时,对于注册登录用户,也会显示该用户自己的私有数据,保证可浏览数据的完整性和安全性。在数据列表中,包括了元数据类型、元数据名称、元数据编号、数据安全状态、数据所属用户名称、单位、提交时间、以及与该元数据类型相关的一些基础信息。同时,在列表上显示了对显示结果进行排序的功能,在列表右侧提供了根据元数据的部分类型字段进行结果筛选的功能。
数据浏览在单一元数据的列表展示、排序和筛选上有比较丰富的功能,但在数据量庞大、数据类型复杂、数据内容异质性强的组学原始测序数据面前,浏览功能还是无法帮助用户准确定位所需数据。因此,
NODE
设计和部署了全文语义检索来帮助用户通过关键词检索就能定位所需的数据。
NODE
的搜索功能出现和页面顶部的导航工具栏一样出现在首页以及
NODE
平台的各页面上。对于用户而言,在搜索栏中仅需输入对所需数据的关键词描述,用户理解层面的语义信息,就可以在搜索结果列表中找到对应的元数据信息。与数据浏览不同,数据搜索功能不需要用户对数据库中的字段有熟悉和了解,也不需要用户关心元数据的数据类型。在用户搜索得到的结果中包括了
Project
、
Experiment
、
Sample
、
Run
、
Data
、
Analysis
在内的所有与输入关键词相关的元数据记录。数据结果页面与数据浏览页面的展示方式类似,不同之处在数据搜索结果中不仅包含一种数据类型的元数据、而是把各种数据类型的结果都展示在同一个页面上。同时,数据搜索结果页面因为数据异质性的问题取消了结果排序功能,并且根据结果的数据字段丰富了右侧的数据筛选功能。
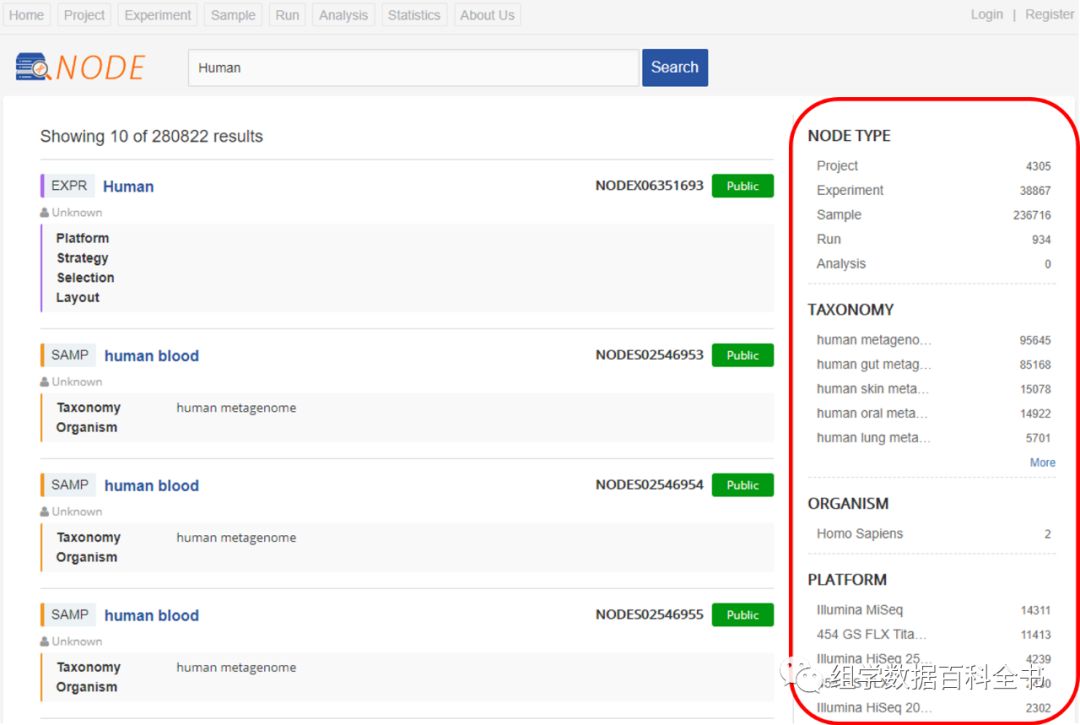
不论在数据浏览页面还是数据搜索结果页面,直接选择得到的数据记录就能转接到该条元数据的详情页面。
4.2
数据发布
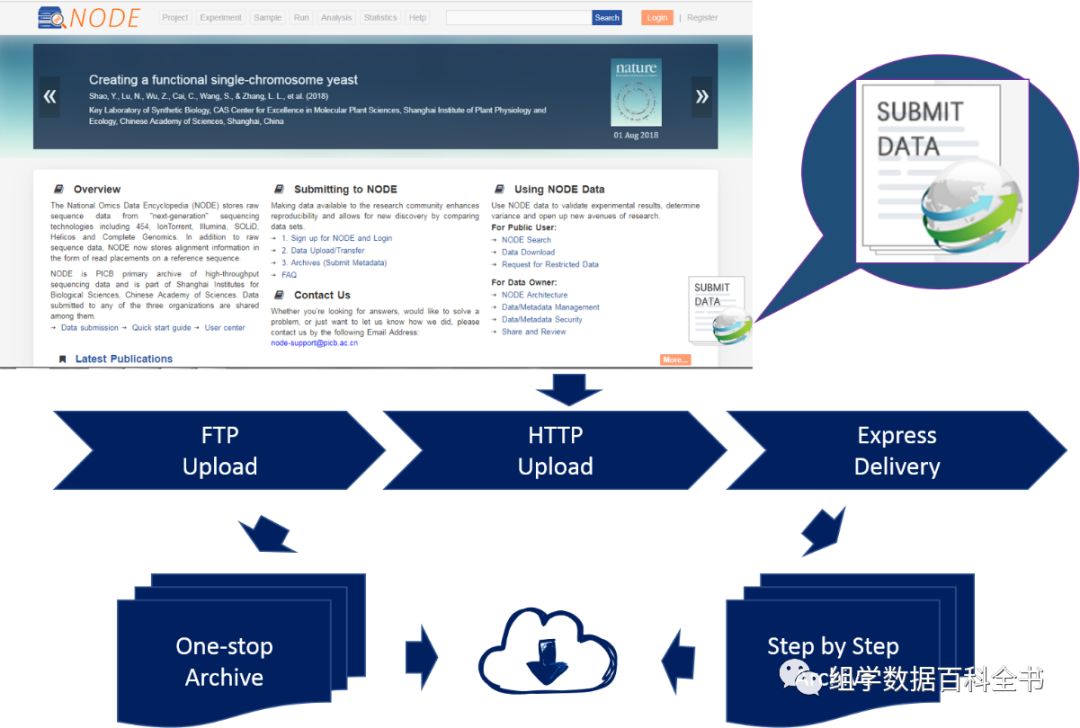
传统的先提交元数据后数据的发布方式要求平台用户对平台数据结构和字段设计有一定的了解,或阅读平台文档后再填写相关信息,而在元数据审核完毕后,若无法保证网络的连通性(特别是海外用户),也会对已经上传元数据的用户造成困扰,在易用性上形成障碍。为了解决这个问题,
NODE
将数据上传步骤提前。用户可以在数据成功上传到平台后再通过平台的“一站式”或者分步创建的功能在系统提示的帮助下填写元数据将数据顺利归档。同时
NODE
在平台几乎所有的页面上都保留的数据上传的快捷入口,用户可以将任何工作数据上传到平台,形成个人的工作平台。
用户可以选择使用
FTP
,
HTTP
或者邮寄硬盘的方式将原始数据上传至
NODE
中,原始数据上传完成后用户可以选择一站式(
one-stop
)或者按步骤(
step by step
)完成元数据的填写及数据的归档,数据归档后则完成了一次完整的数据发布。
4.3
数据下载
NODE
的数据直接关联在
Run
层级,因此用户可以在





