选自DeepMind
机器之心编译
参与:杨旋、Terrence、吴攀、李亚洲
几天前,机器之心介绍了
DeepMind 在 NIPS 2016 发表的部分论文(part1)
。昨日,DeepMind 更新 Part2,介绍了另外 6 篇论文。
1. 带有随机层数的序贯神经模型(Sequential Neural Models with Stochastic Layers)
-
作者:Marco Fraccaro, Søren Kaae Sønderby, Ulrich Paquet, Ole Winther
-
论文链接:https://arxiv.org/abs/1605.07571
摘要:我们对这个世界的大多数事物的推理都是按顺序进行的 sequential):从开始聆听到声音和音乐,到想象我们到达目的地的路线,到随着时间去观察一个网球的运动轨迹。所有这些序列中都具有一定量的潜在随机结构。有两个强大且互补的模型(循环神经网络(recurrent neural networks(RNN)和随机状态空间模型(stochastic state space models(SSM))被广泛用于对这样的序列数据进行建模。RNN 在捕获数据中的长期依赖性方面表现优异,而 SSM 可以对序列中的潜在随机结构中的不确定性进行建模,并且善于跟踪和控制。
有没有可能将这两者的最好一面都集中到一起呢?在本论文中,我们将告诉你如何通过分层确定的(RNN)层和随机的(SSM)层去实现这个目标。我们将展示如何通过给定一个序列的过去(过滤)、以及它的过去和未来(平滑)的信息来有效地推理它当前的隐含结构。
2.通过梯度下降去学习通过梯度下降的学习(Learning to learn by gradient descent by gradient descent)
-
作者:Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew Hoffman, David Pfau, Tom Schaul, Nando De Freitas
-
论文链接:https://arxiv.org/abs/1606.0447 (https://arxiv.org/abs/1606.04474)
摘要:当今的优化算法通常是人工设计的;算法设计者们在仔细思考了每个问题之后,设计出能探索到可以精确地表征结构的算法。这个过程即是 2000 年代早期,计算机领域根据人工设计的特征采用人工的方式来特征化和定位图像中边缘和角等特征。现代计算机视觉的最大突破是直接从数据中学习这些特征,把人工设计从这个过程中移除了。本论文展示了我们可以如何将这些技术扩展到算法设计中——不仅学习特征,而且也学习整个学习的过程。
我们展示了如何将优化算法的设计作为一个学习问题,允许算法学习以一种自动的方式在相关问题中探索结构。我们学习到的算法在已经被训练过的任务上的表现胜过了标准的人工设计的算法,并且也可以很好地推广到具有类似结构的新任务中。我们在一些任务上演示了这种方法,包括神经网络训练和使用神经艺术为图像赋予风格。
3. 一个使用部分调节的在线序列到序列的模型(An Online Sequence-to-Sequence Model Using Partial Conditioning)
-
作者:Navdeep Jaitly, Quoc V. Le, Oriol Vinyals, Ilya Sutskever, David Sussillo, Samy Bengio
-
论文链接:http://papers.nips.cc/paper/6594-an-online-sequence-to-sequence-model-using-partial-conditioning.pdf
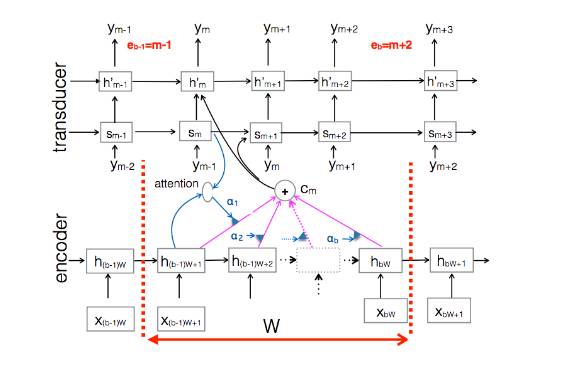
摘要:由于从一个序列到另一个序列(序列到序列(seq2seq))的映射的模型的通用性比较优异,所以它们在过去两年变得非常流行,在翻译、字幕或者解析等一系列任务中达到了顶尖水准。这些模型的主要缺点是它们在开始产生结果输出序列「y」之前需要读取整个输入序列「x」。在我们的论文中,我们通过允许模型在整个输入序列被读取之前发出输出符号来规避这些限制。虽然这引入了一些独立假设,但也在语音识别或机器翻译等特定领域的在线决策中使得这些模型更加理想。
4. 通过时间的记忆有效的反向传播(Memory-Efficient Backpropagation through time)
-
作者:Audrunas Gruslys, Remi Munos, Ivo Danihelka, Marc Lanctot, Alex Graves








