本文是 Adit Deshpande 的 Deep Learning Research Review 系列文章的第三篇,总结和解读了深度学习在自然语言处理领域的应用。在这里,机器之心随带推荐一篇之前发过的文章《
总结 | 2016 年最值得读的自然语言处理领域 Paper
》
自然语言处理介绍
介绍
自然语言处理(NLP)研究的问题是关于如何构建通过处理和理解语言来执行某些任务的系统。这些任务可包括
传统的 NLP 方法涉及很多语言学领域自身的知识。要理解诸如音位和语素这样的术语是非常基本的要求,就好像他们的研究统统都是语言学问题一样。让我们来看看传统 NLP 是如何尝试理解下面的话的。

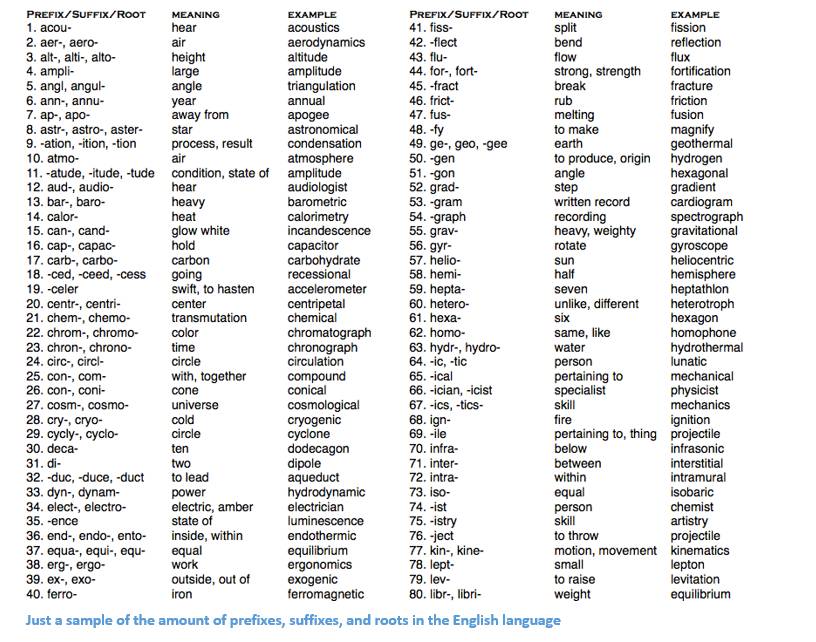
假设我们的目标是收集关于这个词的一些信息(表征其情感,找到它的定义等)。使用我们语言领域的知识,我们可以把这个词分成 3 部分。

我们知道前缀「un」表示反对或相反的想法,我们知道「ed」可以指定单词的时间段(过去时态)。通过识别词干「兴趣」的含义,我们可以很容易地推导出整个词的定义和情感。看起来很简单吧?然而,当考虑英语中所有不同的前缀和后缀时,需要非常熟练的语言学家来理解所有可能的组合和意义。
深度学习如何很好地解决这些问题?
从最基础层面来说,深度学习即是表征学习(representation learning)。通过卷积神经网络(CNN),我们可以看到不同的过滤器(filter)组合可以用来将各种物体分类。这里,我们将采用一种相似的方式,通过大数据集来创建对各种词的表征。
本文概论
本文将以这样的方式来组织文章的内容结构:我们将首先浏览一下构建 NLP 深度网络的基本构建块,然后来谈一谈最近研究论文所能带来的一些应用。不知道我们为什么使用 RNN 或者为什么 LSTM 很有效?这些疑问都很正常,但希望你在读完下面的这些研究论文之后能更好地了解为什么深度学习技术能够如此显著地促进了 NLP 的发展。
词向量(Word Vectors)
由于深度学习爱用数学进行工作,我们将把每个词表示为一个 d 维向量。让我们使 d = 6。
[Image: https://quip.com/-/blob/cGAAAAubYyb/u9YfGL3mGnMUFhrXOfGArQ] 现在让我们考虑如何填这些值。我们想要以这样的方式填充值:向量以某种方式表示词及其语境、含义或语义。一种方法是创建共生矩阵(coocurence matrix)。假设我们有以下句子:
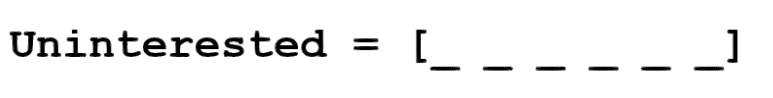
从这句话,我们要为每个特定的词都创建一个词向量。

共生矩阵是包含了在语料库(或训练集)中每个词出现在所有其他词之后的计数数目的矩阵。让我们看看这个矩阵。
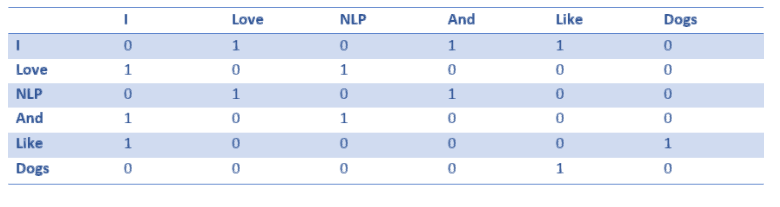
从该矩阵中提取行可以让我们的词向量简单初始化。

请注意,通过这个简单的矩阵,我们可以获得一些非常有用的见解(insight)。例如,请注意「love」和「like」这两个词都包含 1,用于名词(NLP 和狗)后的计数。它们与「I」的交集也是 1,因此表明这些词必须是动词。对于远比一个句子更大的数据集,你可以想象这种相似性将变得更加清楚,因为「like」,「love」和其他同义词将开始具有相似的单词向量,因为它们都在相似的上下文中使用。
现在,尽管这是一个了不起的起点,但我们注意到每个词的维数将随着语料库的大小线性增加。如果我们有一个百万词(在 NLP 标准中并不是很多),我们将有一个一百万乘一百万尺寸的矩阵,它将会非常稀疏(大量的 0)。从存储效率上讲这绝对不是最好的。在寻找表示这些词向量的最优方法方面已经有许多进步。其中最著名的是 Word2Vec。
Word2Vec
词向量初始化技术背后的基本思想是,我们要在这种词向量中存储尽可能多的信息,同时仍然保持维度在可管理的规模(25 - 1000 维度是理想的)。Word2Vec 基于这样一个理念来运作,即我们想要预测每个单词周围可能的词。让我们以上一句话「I love NLP and I like dogs」为例。我们要看这句话的前 3 个词。3 因此将是我们的窗口大小 m 的值。

现在,我们的目标是找到中心词,「love」,并预测之前和之后的词。我们如何做到这一点?当然是通过最大化/优化某一函数!正式地表述是,我们的函数将寻求给定当前中心词的上下文词的最大对数概率。
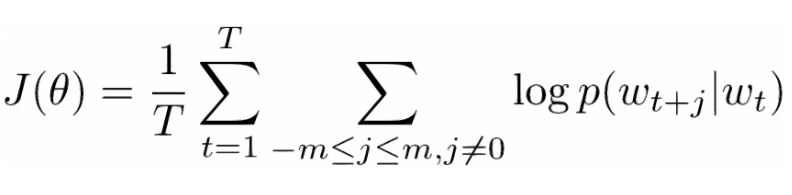
让我们对这一点再深入地探究。上面的成本函数(cost function)基本上是说我们要添加'I'和'love'以及'NLP'和'love'的对数概率(其中「love」是两种情况下的中心词)。变量 T 表示训练句子的数量。让我们再仔细研究一下那个对数概率。
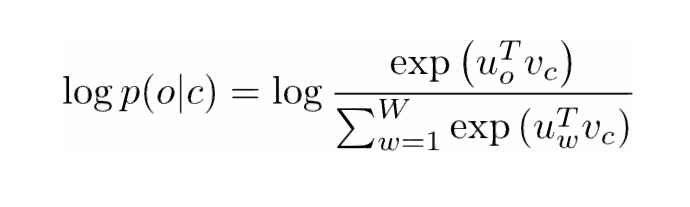
Vc 是中心词的词向量。每个词由两个向量表示(Uo 和 Uw),一个用于当该词用作中心词时,一个用于当它用作外部词(outer word)时。向量是用随机梯度下降(SGD)来训练的。这绝对是一个理解起来更让人困惑的方程之一,所以如果你仍然有疑问想了解到底发生了什么,你可以查看以下两个资源:
一句总结:Word2Vec 寻求通过最大化给定中心词的上下文词的对数概率并通过 SGD 修改向量来找到不同词的向量表示。
(可选:论文《Distributed Representations of Words and Phrases and their Compositionality》的作者接着详细介绍了如何使用频繁词的负采样(negative sampling)和下采样(subsampling)获得更精确的词向量。)
有人认为,Word2Vec 最有趣的贡献是使得不同词向量之间表现出线性关系。经过训练,词向量似乎能捕获不同的语法和语义概念。这些线性关系是如何能通过简单的对象函数和优化技术来形成的,这一点真是相当难以置信。
额外补充:另一种很酷的词向量初始化方法:GloVe(将共生矩阵与 Word2Vec 的思想结合在一起):http://nlp.stanford.edu/pubs/glove.pdf
循环神经网络(RNN)
好吧,那么现在我们有了我们的词向量,让我们看看它们如何与循环神经网络结合在一起的。RNN 是当今大多数 NLP 任务的必选方法。RNN 的最大优点是它能够有效地使用来自先前时间步骤的数据。这是一小片 RNN 的大致样子。
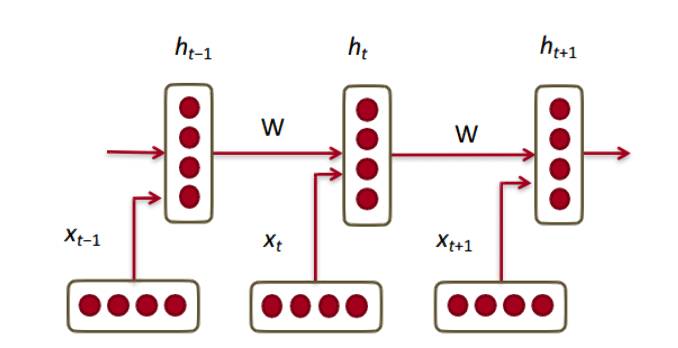
因此,在底层,我们有我们的词向量(xt,xt-1,xt + 1)。每个向量在同一时间步骤(ht,ht-1,ht + 1)有一个隐藏状态向量。让我们称之为一个模块(module)。
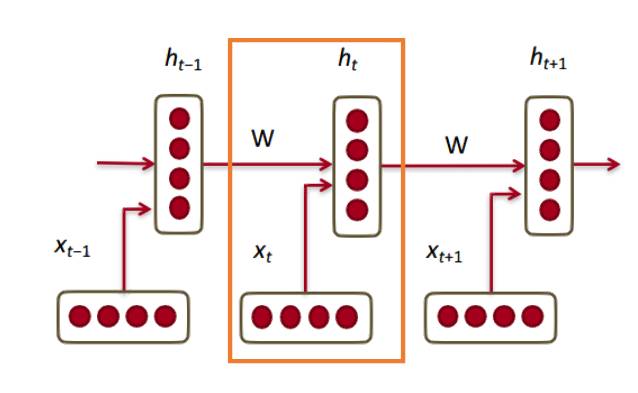
RNN 的每个模块中的隐藏状态是在前一时间步骤的词向量和隐藏状态向量二者的函数。
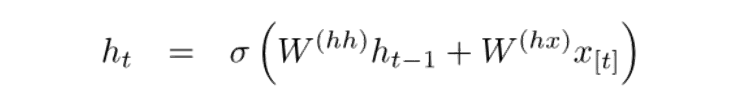
如果你仔细看看上标,你会看到有一个权重矩阵 Whx,我们将它乘以我们的输入,并且在上一个时间步骤中,用一个循环出现的权重矩阵 Whh 乘以隐藏状态向量。请记住,这些循环出现的权重矩阵(recurrent weight matrix)在所有时间步骤上都是相同的。这是 RNN 的关键点。仔细考虑一下这一点,它与传统的(比如 2 层的神经网络)非常不同。在这种情况下,我们通常对于每个层(W1 和 W2)都有不同的 W 矩阵。这里,循环权重矩阵在网络中是相同的。
为了得到特定模块的输出(Yhat),将以 h 乘以 WS,这是另一个权重矩阵。
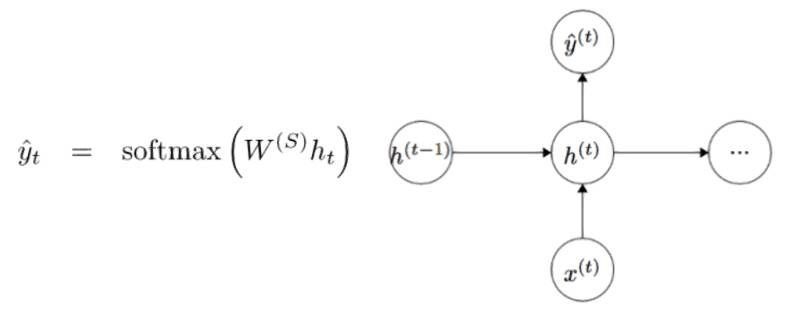
让我们现在退一步并且来理解 RNN 的优点是什么。与传统神经网络的最明显的区别是,RNN 接受输入的序列(在我们的例子中是词)。你可以将其与典型的 CNN 进行对比,在 CNN 中你只需要一个单一的图像作为输入。然而,使用 RNN,输入可以是从一个短句到一篇 5 段文章等各种长度。此外,该序列中的输入的顺序(order)可以极大地影响在训练期间权重矩阵和隐藏状态向量的改变情况。在训练之后,隐藏状态将有望捕获来自过去的信息(以前的时间步骤)。
门控循环单位(GRU)
现在让我们来看门控循环单元(GRU)。这种单元的目的是为计算 RNN 中的隐藏状态向量提供一种更复杂的方法。这种方法得以使我们保留捕获长距依赖(long distance dependencies)的信息。让我们想想看为什么在传统 RNN 设置中长期依赖会成为一个问题。在反向传播期间,误差将流经 RNN,即从最近的时间步骤至最早的时间步骤。如果初始梯度是个小数字(例如
在传统的 RNN 中,隐藏状态向量通过下面的公式计算得来。
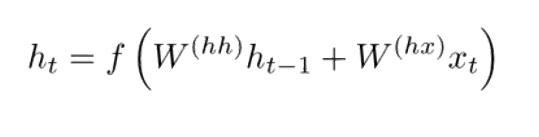
GRU 提供了一个计算此隐藏状态向量 h(t) 的不同方式。计算分为 3 个分量,一个更新门(update gate),一个重置门(reset gate)以及一个新的记忆容器(memory container)。两个门均是前一时间步骤上输入词向量和隐藏状态的函数。
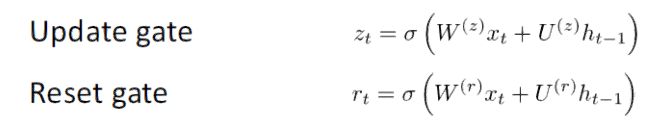
关键区别在于每个门使用不同的权重。这种区别通过不同的上标来表示。更新门使用 Wz 和 Uz,而重置门使用 Wr 和 Ur。
现在,通过以下方式计算新的记忆容器:
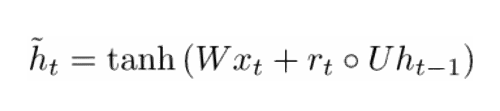
空心点表示Hadamard积
现在,如果你仔细看看公式,你将看到,如果重置门单元接近 0,那么整个项也变为 0,此时可以忽略来自之前时间步骤的 ht-1 的信息。在这种情况下,单元只是新的词向量 xt 的函数。
h(t) 的最终公式写为:
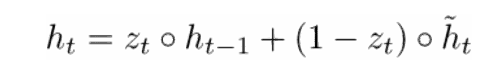
ht 是一个由三部分构成的函数:重置门、更新门和记忆容器。通过观察当 zt 接近 1 和接近 0 时会发生什么是理解这点最好的方法。当 zt 接近 1 时,新的隐藏状态向量 ht 主要取决于先前的隐藏状态,且因为(1-zt)变为 0 使得我们会忽略当前的存储容器。当 zt 接近 0 时,新的隐藏状态向量 ht 主要取决于当前的存储容器,此时我们会忽略之前的隐藏状态。观察这三部分最直观的方法可以总结如下。
-
更新门, 如果 zt〜1,则 ht 完全忽略当前词向量,且只复制上一个隐藏状态(如果行不通,看看 ht 方程,并且注意当 zt〜1 时 1 - zt 项发生什么)。如果 zt〜0,则 ht 完全忽略上一时间步骤上的隐藏状态,且依赖新的记忆容器。此门让模型控制着之前隐藏状态中应影响当前隐藏状态的信息的多少。
-
重置门, 如果 rt〜1,则存储容器阻止来自之前隐藏状态的信息。如果 rt〜0,则存储容器忽略之前的隐藏状态。如果该信息在将来不具有相关性,则此门会令模型删除信息。
-
记忆容器:取决于重置门。
阐明 GRU 有效性的常见示例如下。假设你有以下语段。

和相关问题「2 个数字的和是什么?」。由于中间语句对手头问题绝对没有影响,重置门和更新门将允许网络在一定意义上「忘记」中间语句,同时仅学习应修改隐藏状态的特定信息(这种情况下是数字)。
长短时记忆单元(LSTM)
如果你对 GRU 感到满意的话,那么 LSTM 并不会让你更加满意。LSTM 也是由一系列的门组成。
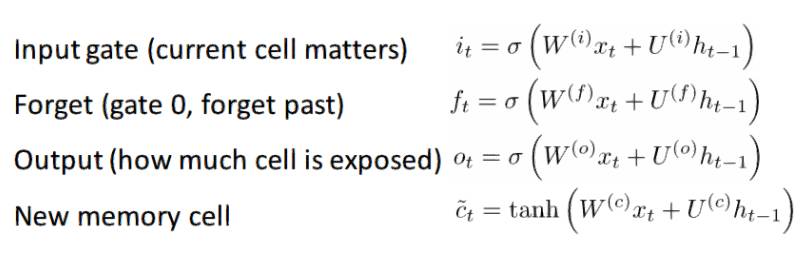
肯定有更多的信息需要采集。因为这可以被认为是 GRU 背后的想法的延伸,我不会进行深入地分析。如果你想对每一个门和每一步计算进行深入地演算,请查看 Chris Olah 的一篇非常好的博客文章:http://colah.github.io/posts/2015-08-Understanding-LSTMs/。这是迄今为止,在 LSTM 上最受欢迎的教程,它一定会帮助你理解这些单元工作的这么好的原因和其工作方式。
LSTM 和 GRU 的比较
让我们从两者相似之处看起。这两种单元具有能够保持序列中字的长期依赖性的特殊功能。长期依赖性指两个词或者短语可能会在不同的时间段出现的情况,但是它们之间的关系对于解决最终目标仍然至关重要。LSTM 和 GRU 能够通过忽略或者保持序列中的某些信息的门来获取这些依赖性。
两个单元之间的差异在于它们所拥有的门的数量(GRU – 2, LSTM – 3)。这影响了输入通过的非线性数,并最终影响整体计算。GRU 也不具有与 LSTM 相同的记忆单元(ct)。
看论文之前
只是做一个快速的注释。还有一些其他的深度模型在自然语言处理(NLP)当中很有用。递归神经网络(recursive neural networks)和用于自然语言处理(NLP)的卷积神经网络(CNN)有时会在实践中应用,但不像循环神经网络(Recurrent neural Network)那样流行。循环神经网络(RNN)是在大多数深度学习自然语言处理(NLP)系统中的支柱。
好的。现在我们对与自然语言处理(NLP)相关的深度学习有了不错的理解,让我们来看一些论文。由于在自然语言处理(NLP)中有许多不同领域的问题(从机器翻译到问题回答),我们可以研究许多论文,但是我发现其中有三篇论文有着独到的见解。2016 年,在自然语言处理(NLP)方面有着巨大的进步,但是让我们从 2015 年的一篇论文看起。
简介:
第一篇文章,我们将要讨论的是在问答(Queston Answering)子领域的一个非常有影响力的论文。作者是 Jason Weston、Sumit Chopra 和 Antoine Bordes,这篇论文介绍了一类称为记忆网络的模型。
记忆网络的直观思想是:为了准确地回答关于一段文本的问题,你需要以某种方式记忆被提供的最初的信息。如果我问你「RNN 代表什么?」,(假设你已经完全阅读了这篇文章),你将会给我一个答案。因为你通过阅读这篇文章的第一部分所得到的信息,将会存储在你记忆中的某个地方。你只需要几秒钟来找到这个信息,并用文字将其表述出来。现在,我不知道大脑是如何作到这一点的,但是为信息保留存储空间的想法仍然存在。
本文中描述的记忆网络是唯一的,因为它是一种能够读写的关联记忆(associative memory)。有趣的是,我们并没有这种类型的卷积神经网络或者 Q 网络(Q-Network)(应用于强化学习)或者传统的神经网络的记忆。这是因为问答任务很大程度上依赖于建模的能力或者保持追踪长期依赖性的能力,比如追踪故事中的角色或事件的时间线。使用卷积神经网络和 Q 网络,「记忆(memory)」是一种内置在网络的权重。因为它可以学习从状态到动作的不同的筛选或者映射。首先,可以使用 RNN 和 LSTM,但是它们通常不能记忆来自过去的输入(这在回答任务中中非常重要)。
网络架构
好的,现在让我们来看一看这个网络如何处理它给出的初始文本。就像大多数机器学习算法一样,第一步是将输入转化为特征表示。这需要使用词向量、词性标签等。这真的取决于编程者。

下一步将采用特征表示 I(x),并允许更新我们的记忆 m 以反映我们接收到的最新的输入 x。

你可以认为记忆 m 是一种由单独的记忆 mi 组成的数组。这些单独的记忆 mi 中的每一个都可以作为整体的记忆 m,特征表示 I(x) 和/或者它本身。该函数 G 可以简单地将整个表示 I(x) 存储在单独的记忆单元 mi 中。基于新的输入,你可以修改函数 G 来更新过去的记忆。第三和第四步包括基于问题读取记忆以获得特征表示 o,然后对其解码以输出最终答案 r。

R 函数可以用来将特征表示从记忆转化为问题的即可靠又准确的答案。
现在,让我们来看第三步。我们希望这个 O 模块输出一个特征表示,使其最佳地匹配给定问题 X 的一个可能的答案。现在这个问题将要与每个独立的记忆单元进行匹配并且基于记忆单元支持该问题的程度被「评分」。








