看点:溯源云端AI造芯起点,谷歌TPU背后的创新与破局。


距离2016年那场世界著名的人机大战——AlphaGo对战李世石已经过去了四年。那一年,AlphaGo以4:1总分打败围棋世界冠军李世石,随后独战群雄,在与排名世界第一围棋的冠军柯洁对战胜利后宣布“隐退”,但其背后的那块芯片却开启了芯片产业的新篇章。正是这翻天覆地的四年,AI芯片领域——尤其是云端AI芯片的市场规模一路扶摇直上,成为一众芯片巨头和新势力虎视眈眈之地。据赛迪顾问在2019年8月发布的《中国人工智能芯片产业发展白皮书》,2018年全球云端AI芯片市场规模为62.1亿美元(约427.5亿人民币),预计这一数值将在2021年达到221.5亿美元(约1524.7亿人民币),巨大的市场将如火山爆发般呈现在众人眼前。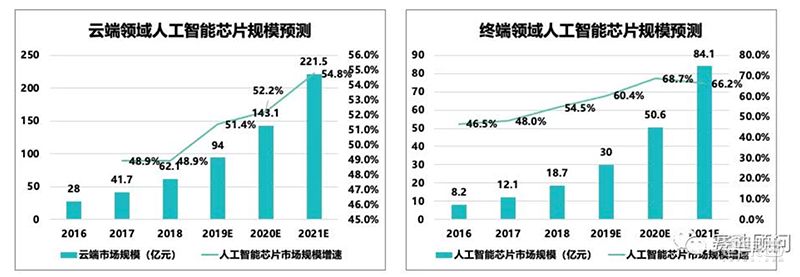
在这片浩淼蓝海中,有一个角色则起到了划时代的重要意义,它就是谷歌TPU(Tensor Processing Unit,张量处理单元)。自打与李世石、柯洁,以及中日韩数十位围棋高手的围棋对战中脱颖而出后,谷歌TPU曾一路狂飙突进,现在已演进到了第三代。它的出现,无疑打破了GPU曾一度称霸神经网络推理和训练市场的局面。虽然,在2019年5月的谷歌I/O开发者大会上,万众瞩目的第四代TPU却意外缺席,取而代之的是以1000个TPUv3组成的TPUv3 Pod,以及边缘AI芯片Edge TPU。即便如此,它仍通过一定程度的对外开放,以及辅助谷歌内部服务器应用深刻地影响着云端AI芯片市场。但从市场角度看,未来云端AI芯片巨大的发展潜力和市场机遇为谷歌TPU提供了肥沃的土壤;另一方面,紧迫的算力瓶颈和摩尔定律放缓等问题也越来越难以忽视。这次,我们通过起底谷歌TPU的发展史,探究它是如何从最初的机器学习推理应用,发展为如今覆盖云端至边缘端的TPU生态?它的诞生为云端AI芯片市场带来了哪些重要变化?
始于算力瓶颈,首秀人类围棋界
简单地说,它是谷歌在2015年6月的I/O开发者大会上推出的计算神经网络专用芯片,为优化自身的TensorFlow机器学习框架而打造,主要用于AlphaGo系统,以及谷歌地图、谷歌相册和谷歌翻译等应用中,进行搜索、图像、语音等模型和技术的处理。区别于GPU,谷歌TPU是一种ASIC芯片方案。ASIC全称为Application-Specific Integrated Circuit(应用型专用集成电路),是一种专为某种特定应用需求而定制的芯片。但一般来说,ASIC芯片的开发不仅需要花费数年的时间,且研发成本也极高。对于数据中心机房中AI工作负载的高算力需求,许多厂商更愿意继续采用现有的GPU集群或GPU+CPU异构计算解决方案,也甚少在ASIC领域冒险。
那么,谷歌为何执意要开发一款ASIC架构的TPU?实际上,谷歌在2006年起就产生了要为神经网络研发一款专用芯片的想法,而这一需求在2013年也开始变得愈发急迫。当时,谷歌提供的谷歌图像搜索、谷歌照片、谷歌云视觉API、谷歌翻译等多种产品和服务,都需要用到深度神经网络。在庞大的应用规模下,谷歌内部意识到,这些夜以继日运行的数百万台服务器,它们内部快速增长的计算需求,使得数据中心的数量需要再翻一倍才能得到满足。然而,不管是从成本还是从算力上看,内部中心已不能简单地依靠GPU和CPU来维持。在种种因素的推动下,不差钱的谷歌正式开始了TPU的研发之旅。经过研发人员15个月的设计、验证和构建,TPU在2014年正式研发完成,并率先部署在谷歌内部的数据中心。除了在内部秘密运行了一年外,谷歌TPU还在围棋界“大杀四方”,斩下一个个“人机大战”的神话。据了解,在使用TPU之前,AlphaGo曾内置1202个CPU和176个GPU击败欧洲冠军范惠。直到2015年与李世石对战时,AlphaGo才开始使用TPU,而当时部署的TPU数量,只有48个。这场对战胜利的“秘密武器”也在一年后的谷歌I/O开发者大会上被揭开神秘面纱,TPU正式面世。

谷歌TPU的迭代、上云、发力终端
在面世后的短短两年,谷歌TPU已经迭代到了第三代,性能亦不断跃升。与此同时,随着研发的投入和广泛应用,谷歌也逐步推出可扩展云端超级计算机TPU Pod,以及Edge TPU。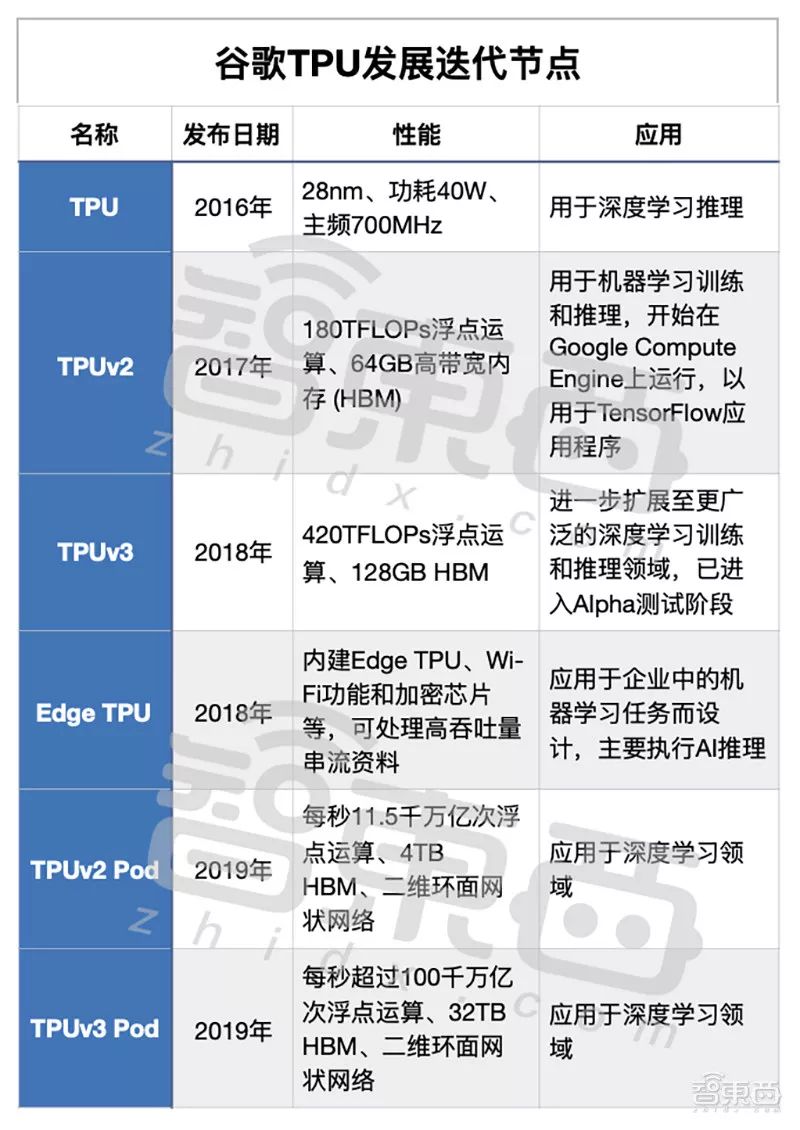
虽是为神经网络而研发,但谷歌最初的第一代TPU仅用于深度学习推理。从性能上看,第一代谷歌TPU采用了28nm工艺制造,功耗约为40W,主频700MHz。研发之初,由于谷歌需要尽快将TPU部署到内部现有的服务器中,因此研发人员选择将处理器打包成外部加速卡,以插入SATA硬盘插槽后进行嵌入式安装。同时,TPU通过PCIe Gen3 x16总线连接到主机,实现了12.5GB/s的有效带宽。除了在AlphaGo上应用之外,谷歌第一代TPU还用于谷歌的搜索、翻译和相册等应用的机器学习模型中。
▲Google第一代TPU(左),在谷歌数据中心中部署的TPU(右)2、2017年:第二代TPU,引入Google Cloud历经一年的更新、研发和迭代,谷歌在2017年5月发布了第二代TPU,并从这一代起能够用于机器学习模型的训练和推理。与第一代相比,第二代TPU能够实现180TFLOPs浮点运算的计算能力,同时其高带宽内存(HBM)也提升到了64GB,解决了第一代TPU内存受带宽限制的问题。在运行AI工作负载上,谷歌第二代TPU与同期的CPU、GPU相比,性能比传统的GPU高了15倍,比CPU高了30倍,每瓦性能亦提高了30至80倍。也是从第二代TPU起,谷歌第二代TPU引入Google Cloud,应用在谷歌计算引擎(Google Compute Engine ,简称GCE)中,也称为Cloud TPU,进一步优化谷歌搜索引擎、Gmail、YouTube和其他服务的运行。与此同时,Cloud TPU通过TensorFlow进行编程,并与CPU、GPU及基础设施和服务结合,以根据用户应用需求构建和优化机器学习系统。同时,随着谷歌第二代TPU的发布,新一轮的人机大战也再次揭开序幕。而这一代AlphaGo的芯片配置,仅用了4块TPUv2,便击败当时的世界围棋冠军柯洁。实际上,谷歌除了推出第二代TPU外,还宣布计划研发可扩展云端超级计算机TPU Pods,通过新的计算机网络将64块Cloud TPU相结合,能够提供约11500万亿次浮点运算能力。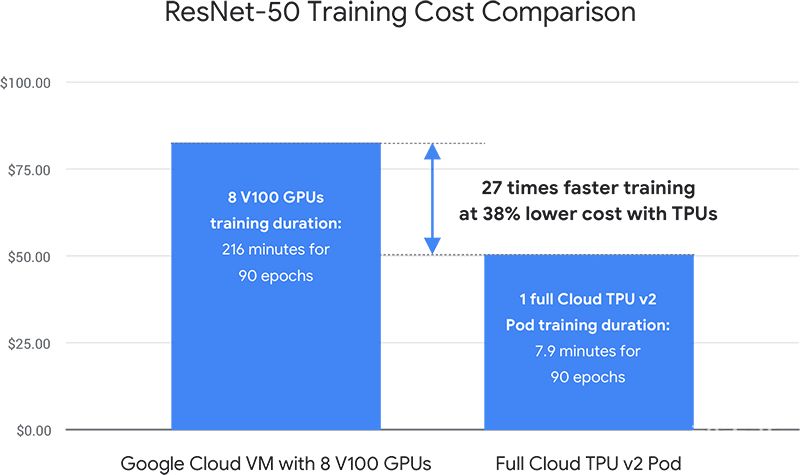
3、2018年:第三代TPU,边缘AI芯片Edge TPU同样的研发节奏,2018年5月,谷歌不出意外地发布了第三代TPU,其各方面性能不仅实现了升级,也进一步扩展到更广泛的深度学习训练和推理领域。谷歌表示,第三代TPU的性能均是第二代TPU的两倍,可实现420TFLOPs浮点运算,以及128GB的高带宽内存。同时,它还可部署在基于云计算的超级计算机TPU Pod中,其中的芯片数量是上一代的四倍。与第二代TPU Pod的部署相比,第三代每个Pod的性能提高了8倍,且每个Pod最多拥有1024个芯片。
谷歌在2018年还发布了用于边缘推理的微型AI加速芯片——Edge TPU,专为企业机器学习任务而设计,用于IoT设备中。Edge TPU同样是一款ASIC芯片。从应用上看,它与Cloud TPU相互补,用户能够先使用Cloud TPU对机器学习模型进行加速训练,再将训练好的模型放入相关设备中,进一步用Edge TPU进行机器学习推理。据了解,Edge TPU能够让IoT设备以每秒30帧以上的速度,在高分辨率视频上运行多个先进的计算机视觉模型。
同时,谷歌还为Edge TPU推出了一套名为Cloud IoT Edge的软件平台,该平台拥有Edge IoT Core和Edge ML两大主要组件,能够帮助用户将在Google Cloud上构建和训练的机器学习模型,通过Edge TPU扩展到边缘设备中运行。虽然这一年谷歌并未发布第四代TPU,却上演了另一个重头戏——发布第二代和第三代TPU Pod,可以配置超过1000颗TPU。作为TPU的“升级版”,谷歌第二代TPU Pod能够容纳512个内核,实现每秒11.5千万亿次浮点运算;第三代TPU Pod速度则更快,可实现每秒超过100千万亿次浮点运算。据悉,在相同配置(265块TPU)下训练ResNet-50模型时,第二代TPU Pod需要11.3分钟,而第三代TPU Pod只需7.1分钟。

架构创新,掀起云端造芯大浪潮
谷歌TPU系列的出现,不仅突破了最初深度学习硬件执行的瓶颈,还在一定程度上撼动了英伟达、英特尔等传统GPU芯片巨头的地位。自2015年以来,与AI芯片相关的研发逐渐成为整个芯片行业的热点,在云端的深度学习训练和推理领域,已然不是GPU——尤其是英伟达的独霸一方。而谷歌TPU的诞生,也让越来越多的公司前赴后继地尝试设计GPU之外的专用AI芯片,以进一步实现更高效的性能。从技术层面看,谷歌TPU的出现在架构创新上也为行业带来了几点思考[1]:在谷歌看来,片外内存低是GPU能效比低的主要原因。一些GPU由于片上内存较少,因此在运行过程中需要不断地去访问片外动态随机存取存储器(DRAM),从而在一定程度上浪费了不必要的能耗。因此,谷歌在最初设计TPU时,总共设计了占总芯片面积37%的内存,其中包括24MB的局部内存、6MB的累加器内存,以及用于与主控处理器对接的内存。一般来说,神经网络的预测并不需要32位或16位的浮点计算精度,因此它可以通过8位低精度运算的方法,在保证适当准确度的同时,对神经网络进行预测。通过量化技术,神经网络预测的成本大大减少,并相应减少了内存的使用。例如,当研发人员将量化应用于流行的图像识别模型Inception时,芯片内存从91MB压缩到了23MB,约为其原始大小的四分之一。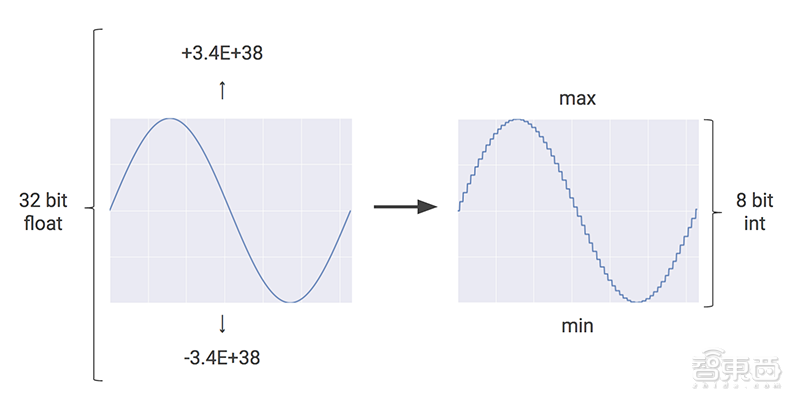
虽然谷歌TPU是ASIC芯片,但却与FPGA又有些类似,它具备一定的可编程性能力。在谷歌看来,TPU的研发并非只用于运行一种神经网络模型。因此,谷歌选择采用了复杂指令集(CISC)作为TPU指令集的基础,能够较为侧重地运行更复杂的任务。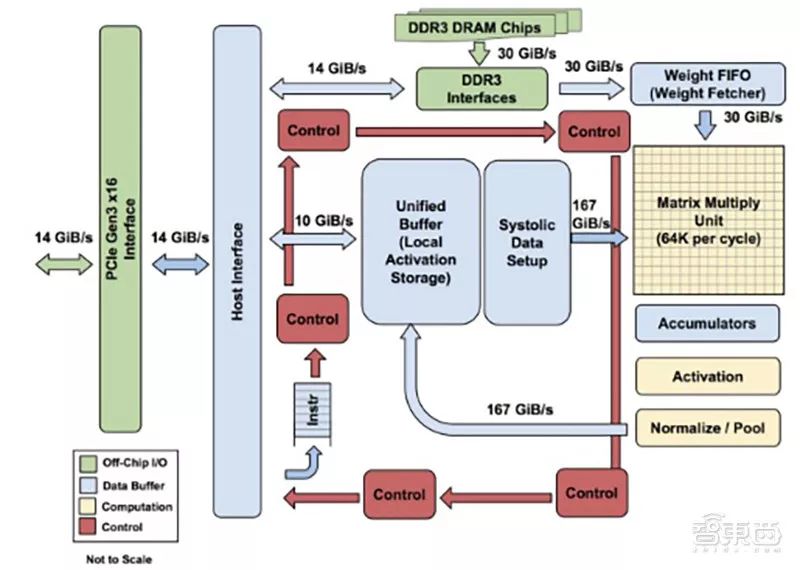
谷歌还定义了十二个专门为神经网络推理而设计的高级指令,能够在输入数据和权重之间执行矩阵乘法,并应用激活函数。为了能进一步对TPU进行编程,谷歌还创建了一个编译器和软件堆栈,能够调用TensorFlow图中的API,转化成TPU指令。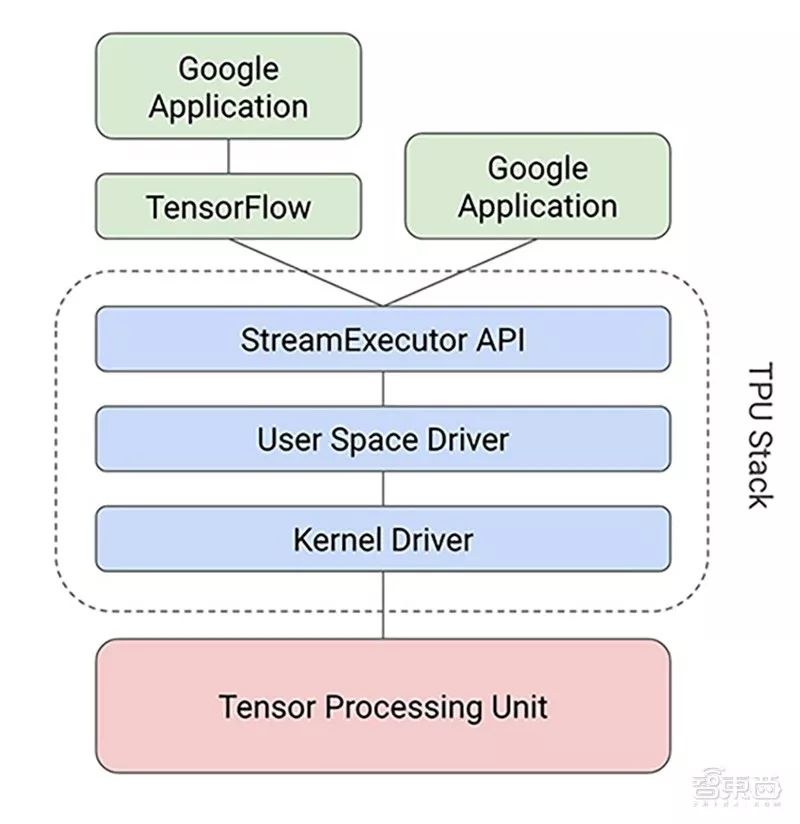
谷歌为TPU设计了矩阵乘法单元(MXU)的并行计算。它能够在一个时钟周期内处理数十万次矩阵运算,相当于一次打印一个字符、一次打印一行字或一次打印一页文档。MXU具有与传统CPU和GPU截然不同的架构,又称为脉动阵列(systolic array)。脉动阵列使得在每次运算过程中,谷歌TPU能够将多个运算逻辑单元(ALU)串联在一起,并复用从一个寄存器中都取得结果。这种设计,不仅能够将数据复用实现最大化,减少芯片在运算过程中的内存访问次数,同时也降低了内存带宽压力,进而降低内存访问的能耗。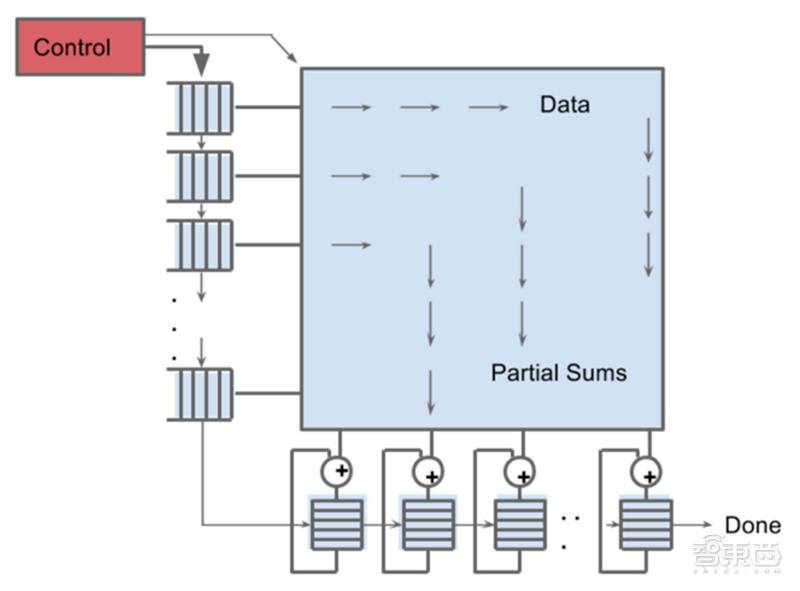
谷歌TPU的一鸣惊人,不仅为AI芯片领域带来了架构创新,同时亚马逊、微软等一众科技巨头,以及寒武纪、天数智芯等新势力亦开始纷纷入局,势要在云端AI芯片市场中抢占地盘,逐渐掀起行业云端造芯大浪潮。
结语:加速云端AI芯片市场的发展
从CPU到GPU,再到如今ASIC和FPGA相继入局,云端AI芯片市场的百花齐放,与谷歌TPU的努力息息相关。如今,云端AI芯片市场依然杀得热火朝天,前有赛灵思和寒武纪等新老势力不断崛起,进一步蚕食非GPU领域的市场,后有科技巨头四处找寻机会“大鱼吃小鱼”,合并有潜力的新玩家,整片市场呈一派割据混战之势。但不容忽视的是,随着云端AI芯片的不断发展,大数据持续爆发,以及摩尔定律逐渐放缓,算力也再次来到了新的瓶颈。届时,这些玩家是通过先进制程再次撕开云端AI芯片的新技术领域,还是依靠研发创新架构来实现算力的飞跃,不管走向哪条路都需直面种种挑战。回头看,在AI芯片市场开辟之初,谷歌凭借TPU逐渐打开云端AI芯片市场新的竞争格局,但当云端AI芯片开始进入新时代,谷歌TPU能否再次延续过往辉煌,为市场开辟新的方向和思路?我们拭目以待。[1]文章相关内容参考:Google Blog等。(本账号系网易新闻·网易号“各有态度”签约帐号)











