
来源:本文授权转载自知乎作者端点星,版权归作者所有。
在摩尔定律的指导下,集成电路的制造工艺一直在往前演进。得意与这几年智能手机的流行,大家对节点了解甚多。例如40nm、28nm、20nm、16nm等等,但是你知道的这些节点的真正含义吗?你知道他们是怎么演进的吗?我们来看一下这个报道。
首先解析一下技术节点的意思是什么。
常听说的,诸如,台积电16nm工艺的Nvidia GPU、英特尔14nm工艺的i5,等等,这个长度的含义,具体的定义需要详细的给出晶体管的结构图才行,简单地说,在早期的时候,可以姑且认为是相当于晶体管的尺寸。
为什么这个尺寸重要呢?因为晶体管的作用,简单地说,是把电子从一端(S),通过一段沟道,送到另一端(D),这个过程完成了之后,信息的传递就完成了。因为电子的速度是有限的,在现代晶体管中,一般都是以饱和速度运行的,所以需要的时间基本就由这个沟道的长度来决定。越短,就越快。这个沟道的长度,和前面说的晶体管的尺寸,大体上可以认为是一致的。但是二者有区别,沟道长度是一个晶体管物理的概念,而用于技术节点的那个尺寸,是制造工艺的概念,二者相关,但是不相等。
在微米时代,一般这个技术节点的数字越小,晶体管的尺寸也越小,沟道长度也就越小。但是在22nm节点之后,晶体管的实际尺寸,或者说沟道的实际长度,是长于这个数字的。比方说,英特尔的14nm的晶体管,沟道长度其实是20nm左右。
根据现在的了解,晶体管的缩小过程中涉及到三个问题,分别是:
第一,为什么要把晶体管的尺寸缩小?以及是按照怎样的比例缩小的?这个问题就是在问,缩小有什么好处?
第二,为什么技术节点的数字不能等同于晶体管的实际尺寸?或者说,在晶体管的实际尺寸并没有按比例缩小的情况下,为什么要宣称是新一代的技术节点?这个问题就是在问,缩小有什么技术困难?
第三,具体如何缩小?也就是,技术节点的发展历程是怎样的?在每一代都有怎样的技术进步?这也是题主所提的真正的问题。在这里我特指晶体管的设计和材料,前面已经说明过了。
下面尽我所能来回答,欢迎指正。
为什么要缩小晶体管尺寸?
第一个问题,因为晶体管尺寸越小,速度就越快。这个快是可以直接翻译为基于晶体管的集成电路芯片的性能上去的。下面以微处理器CPU为例,首先上图,来源是《40 Years of Microprocessor Trend Data》
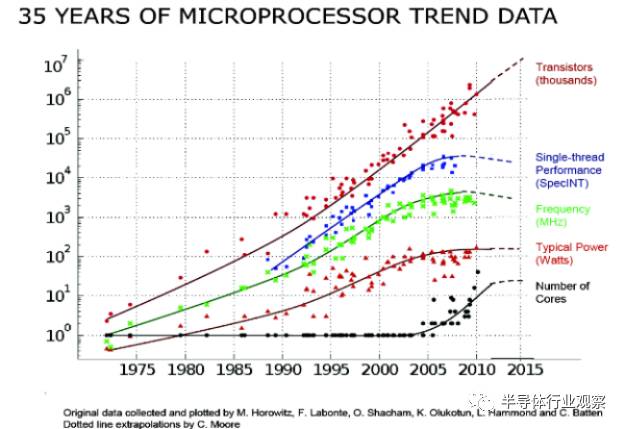
这张图的信息量很大,这里相关的是绿色的点,代表CPU的时钟频率,越高当然越快。可以看出直到2004年左右,CPU的时钟频率基本是指数上升的,背后的主要原因就是晶体管的尺寸缩小。
另外一个重要的原因是,尺寸缩小之后,集成度(单位面积的晶体管数量)提升,这有多个好处,一来可以增加芯片的功能,二来更重要的是,根据摩尔定律,集成度提升的直接结果是成本的下降。这也是为什么半导体行业50年来如一日地追求摩尔定律的原因,因为如果达不到这个标准,你家的产品成本就会高于能达到这个标准的对手,你家就倒闭了。
还有一个原因是晶体管缩小可以降低单个晶体管的功耗,因为缩小的规则要求,同时会降低整体芯片的供电电压,进而降低功耗。
但是有一个重要的例外,就是从物理原理上说,单位面积的功耗并不降低。因此这成为了晶体管缩小的一个很严重的问题,因为理论上的计算是理想情况,实际上,不仅不降低,反而是随着集成度的提高而提高的。在2000左右的时候,人们已经预测,根据摩尔定律的发展,如果没有什么技术进步的话,晶体管缩小到2010左右时,其功耗密度可以达到火箭发动机的水平,这样的芯片当然是不可能正常工作的。即使达不到这个水平,温度太高也会影响晶体管的性能。
事实上,业界现在也没有找到真正彻底解决晶体管功耗问题的方案,实际的做法是一方面降低电压(功耗与电压的平方成正比),一方面不再追求时钟频率。因此在上图中,2005年以后,CPU频率不再增长,性能的提升主要依靠多核架构。这个被称作“功耗墙”,至今仍然存在,所以你买不到5GHZ的处理器,4G的都几乎没有。
以上是三个缩小晶体管的主要诱因。可以看出,都是重量级的提升性能、功能、降低成本的方法,所以业界才会一直坚持到现在。
那么是怎样缩小的呢?物理原理是恒定电场,因为晶体管的物理学通俗的说,是电场决定的,所以只要电场不变,晶体管的模型就不需要改变,这种方式被证明效果最佳,被称为Dennard Scaling,提出者是IBM。
电场等于电压除以尺寸。既然要缩小尺寸,就要等比降低电压。
如何缩小尺寸?简单粗暴:将面积缩小到原来的一半就好了。面积等于尺寸的平方,因此尺寸就缩小大约0.7。如果看一下晶体管技术节点的数字:
130nm、90nm、 65nm、 45nm、 32nm、 22nm、 14nm、 10nm、 7nm (5nm)
会发现是一个大约为0.7为比的等比数列,就是这个原因。当然,前面说过,在现在,这只是一个命名的习惯,跟实际尺寸已经有差距了。
为什么节点的数字不能等同于晶体管的实际尺寸?
第二个问题,为什么现在的技术节点不再直接反应晶体管的尺寸呢?
原因也很简单,因为无法做到这个程度的缩小了。有三个原因是主要的:
首先,原子尺度的计量单位是安,为0.1nm。
10nm的沟道长度,也就只有不到100个硅原子而已。晶体管本来的物理模型这样的:用量子力学的能带论计算电子的分布,但是用经典的电流理论计算电子的输运。电子在分布确定之后,仍然被当作一个粒子来对待,而不是考虑它的量子效应。因为尺寸大,所以不需要。但是越小,就越不行了,就需要考虑各种复杂的物理效应,晶体管的电流模型也不再适用。
其次,即使用经典的模型,性能上也出了问题,这个叫做短沟道效应,其效果是损害晶体管的性能。
短沟道效应其实很好理解,通俗地讲,晶体管是一个三个端口的开关。前面已经说过,其工作原理是把电子从一端(源端)弄到另一端(漏端),这是通过沟道进行的,另外还有一个端口(栅端)的作用是,决定这条沟道是打开的,还是关闭的。这些操作都是通过在端口上加上特定的电压来完成的。
晶体管性能依赖的一点是,必须要打得开,也要关得紧。短沟道器件,打得开没问题,但是关不紧,原因就是尺寸太小,内部有很多电场上的互相干扰,以前都是可以忽略不计的,现在则会导致栅端的电场不能够发挥全部的作用,因此关不紧。关不紧的后果就是有漏电流,简单地说就是不需要、浪费的电流。
这部分电流可不能小看,因为此时晶体管是在休息,没有做任何事情,却在白白地耗电。目前,集成电路中的这部分漏电流导致的能耗,已经占到了总能耗的接近半数,所以也是目前晶体管设计和电路设计的一个最主要的目标。
最后,制造工艺也越来越难做到那么小的尺寸了。
决定制造工艺的最小尺寸的东西,叫做光刻机。它的功能是,把预先印制好的电路设计,像洗照片一样洗到晶片表面上去,在我看来就是一种bug级的存在,因为吞吐率非常地高。否则那么复杂的集成电路,如何才能制造出来呢?比如英特尔的奔腾4处理器,据说需要30多还是40多张不同的设计模板,先后不断地曝光,才能完成整个处理器的设计的印制。
但是光刻机,顾名思义,是用光的,当然不是可见光,但总之是光。
而稍有常识就会知道,所有用光的东西,都有一个本质的问题,就是衍射。光刻机不例外。
因为这个问题的制约,任何一台光刻机所能刻制的最小尺寸,基本上与它所用的光源的波长成正比。波长越小,尺寸也就越小,这个道理是很简单的。
目前的主流生产工艺采用荷兰艾斯摩尔生产的步进式光刻机,所使用的光源是193nm的氟化氩(ArF)分子振荡器(这个名称记不清了)产生的,被用于最精细的尺寸的光刻步骤。
相比之下,目前的最小量产的晶体管尺寸是20nm (14nm node),已经有了10倍以上的差距。
有人问为何没有衍射效应呢?答案是业界十多年来在光刻技术上投入了巨资,先后开发了各种魔改级别的暴力技术,诸如浸入式光刻(把光程放在某种液体里,因为光的折射率更高,而最小尺寸反比于折射率)、相位掩模(通过180度反向的方式来让产生的衍射互相抵消,提高精确度),等等,可歌可泣,就这样一直撑到了现在,支持了60nm以来的所有技术节点的进步。
那又有人问,为何不用更小波长的光源呢?答案是,工艺上暂时做不到。
是的,高端光刻机的光源,是世界级的工业难题。
以上就是目前主流的深紫外曝光技术(DUV)。业界普遍认为,7nm技术节点是它的极限了,甚至7nm都不一定能够做到量产。下一代技术仍然在开发之中,被称为极紫外(EUV),其光源降到了13nm。但是别高兴地太早,因为在这个波长,已经没有合适地介质可以用来折射光,构成必须的光路了,因此这个技术里面的光学设计,全部是反射,而在如此高的精度下,设计如此复杂的反射光路,本身就是难以想象的技术难题。
这还不算(已经能克服了),最难的还是光源,虽然可以产生所需的光线,但是强度远低于工业生产的需求,造成EUV光刻机的晶圆产量达不到要求,换言之拿来用就会赔本。一台这种机器,就是上亿美元。所以EUV还属于未来。
有以上三个原因,其实很早开始就导致晶体管的尺寸缩小进入了深水区,越来越难,到了22nm之后,已经无法做大按比例缩小了,因此就没有再追求一定要缩小,反而是采用了更加优化的晶体管设计,配合上CPU架构上的多核多线程等一系列技术,继续为消费者提供相当于更新换代了的产品性能。
因为这个原因,技术节点的数字仍然在缩小,但是已然不再等同于晶体管的尺寸,而是代表一系列构成这个技术节点的指标的技术和工艺的总和。
晶体管缩小过程中面对的问题
第三个问题,技术节点的缩小过程中,晶体管的设计是怎样发展的。
首先搞清楚,晶体管设计的思路是什么。主要的无非两点:第一提升开关响应度,第二降低漏电流。
为了讲清楚这个问题,最好的方法是看图。晶体管物理的图,基本上搞清楚一张就足够了,就是漏电流-栅电压的关系图,比如下面这种:
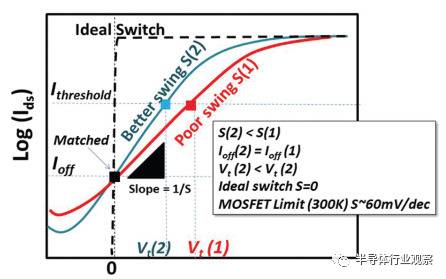
横轴代表栅电压,纵轴代表漏电流,并且纵轴一般是对数坐标。
前面说过,栅电压控制晶体管的开关。可以看出,最好的晶体管,是那种能够在很小的栅电压变化内,一下子就从完全关闭(漏电流为0),变成完全打开(漏电流达到饱和值),也就是虚线。这个性质有多方面的好处,接下来再说。
显然这种晶体管不存在于这个星球上。原因是,在经典的晶体管物理理论下,衡量这个开关响应能力的标准,叫做Subthreshold Swing(SS,不是党卫军...),有一个极限值,约为60,背后的原因就不细说了。
英特尔的数据上,最新的14nm晶体管,这个数值大概是70左右(越低越好)。
并且,降低这个值,和降低漏电流、提升工作电流(提高速度)、降低功耗等要求,是等同的,因为这个值越低,在同样的电压下,漏电流就越低。而为了达到同样的工作电流,需要的电压就越低,这样等同于降低了功耗。所以说这个值是晶体管设计里面最重要的指标,不过分。
围绕这个指标,以及背后的晶体管性能设计的几个目标,大家都做了哪些事情呢?
先看工业界,毕竟实践是检验真理的唯一标准。下面是我的记忆,和节点的对应不一定完全准确,但具体的描述应该没错:
65nm 引入Ge strained的沟道。
strain我不知道如何翻译成中文词汇,但是其原理是通过在适当的地方掺杂一点点的锗到硅里面去,锗和硅的晶格常数不同,因此会导致硅的晶格形状改变,而根据能带论,这个改变可以在沟道的方向上提高电子的迁移率,而迁移率高,就会提高晶体管的工作电流。而在实际中,人们发现,这种方法对于空穴型沟道的晶体管(pmos),比对电子型沟道的晶体管(nmos),更加有效。
里程碑的突破,45nm引入高K值的绝缘层
45nm 引入了高k值绝缘层/金属栅极的配置。
这个也是一个里程碑的成果,我在念书的时候曾经有一位帮他搬过砖的教授,当年是在英特尔开发了这项技术的团队的主要成员之一,因此对这一点提的特别多,耳濡目染就记住了。
这是两项技术,但其实都是为了解决同一个问题:在很小的尺寸下,如何保证栅极有效的工作。
前面没有细说晶体管的结构,下面补一张图:
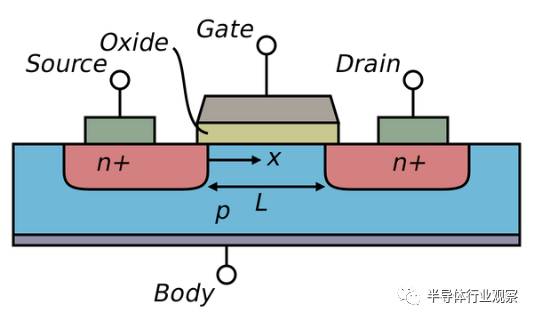
这是一个最基本的晶体管的结构示意图,现在的晶体管早就不长这样了,但是任何半导体物理都是从这儿开始讲起的,所以这是“标配版”的晶体管,又被称为体硅(bulk)晶体管。
gate就是栅。
其中有一个oxide,绝缘层,前面没有提到,但是却是晶体管所有的构件中,最关键的一个。它的作用是隔绝栅极和沟道。因为栅极开关沟道,是通过电场进行的,电场的产生又是通过在栅极上加一定的电压来实现的,但是欧姆定律告诉我们,有电压就有电流。如果有电流从栅极流进了沟道,那么还谈什么开关?早就漏了。
所以需要绝缘层。为什么叫oxide(or "dielectric")而不叫insulator呢?因为最早的绝缘层就是和硅非常自然地共处的二氧化硅,其相对介电常数(衡量绝缘性的,越高,对晶体管性能来说,越好)约是3.9。一个好的绝缘层是晶体管的生命线,这个“好”的定义在这里不多说了,但是要说明,硅天然就具有这么一个性能超级好的绝缘层,对于半导体工业来说,是一件有历史意义的幸运的事情。有人曾经感慨,说上帝都在帮助人类发明集成电路,首先给了那么多的沙子(硅晶圆的原料),又给了一个完美的自然绝缘层。所以至今,硅极其难被取代,一个重要原因就是,作为制造晶体管的材料,其综合性能太完美了。
二氧化硅虽好,在尺寸缩小到一定限度时,也出现了问题。别忘了缩小的过程中,电场强度是保持不变的,在这样的情况下,从能带的角度看,因为电子的波动性,如果绝缘层很窄很窄的话,那么有一定的几率电子会发生隧穿效应而越过绝缘层的能带势垒,产生漏电流。可以想象为穿过一堵比自己高的墙。这个电流的大小和绝缘层的厚度,以及绝缘层的“势垒高度”,成负相关。因此厚度越小,势垒越低,这个漏电流越大,对晶体管越不利。
但是在另一方面,晶体管的开关性能、工作电流等等,都需要拥有一个很大的绝缘层电容。实际上,如果这个电容无限大的话,那么就会达到理想化的60的那个SS指标。这里说的电容都是指单位面积的电容。这个电容等于介电常数除以绝缘层的厚度。显然,厚度越小,介电常数越大,对晶体管越有利。










