Alteryx作为在国内比较少见的数据分析工具,大概在
2016
年末开始注意到它,起初感觉跟
SAS EM
很像,但由于工作比较忙所以一直没有来得及尝试。前些天在
youtube
上搜
datarobot
视频时候看到了
alteryx+datarobot
的案例,感觉非常棒,简直是为不太会
coding
或者不想消耗太多精力在学习
coding
方面的
BA
们打开了一扇新世界的大门
~
所以趁着假期在家认真的翻了下
alteryx
的官网,恰巧发现他家给
udacity
贡献了很多免费
BA
学习材料,正是我最近非常想系统化学习的,于是乎便有想做这么个
14
天试用的专题,能做多少我不确定,
14
天的时间不够了解这个软件的一切,但是我尽力多展示下这个软件的功能吧。
Alteryx为
udacity
贡献的
BA
系列学习视频也非常不错,并没有从第一章就开始推销产品,而是从方法论入手,不只是知其然更是要知其所以然,系列课程一般在最后一课才用自己的产品做演示。在靠前的课程中为了体现其方法论甚至会教你用
excel
该怎样处理类似问题,所以我也打算加大篇幅分享下这些方法论的东西,具体怎样实现每个
BA
都有自己得心应手的工具,用着得手就好。
随机
AB
测试与配对
AB
测试
更多的解释请百度,在此只是根据对原厂课程本身的理解来说明。总的来说分为
随机
ABtest
与
配对
ABtest
两种类型的实验框架。
1.
两者的不同:
随机
ABtest
在进行测试时会随机分配控制组和实验组,多用于电话呼叫或者互联网
/
移动互联网这类可测试单元量(比如人
/
账户)非常大的场景使用,单位测试单元成本低,效果检验可通过
T
检验获得。主要适用场景如页面布局的改变是否有助于提高某些指标这种互联网命题。电话中心既可以使用此框架也可以参考以下框架。
配对
ABtest
在测试前需要先确定测试组的划分,然后通过控制变量匹配与之特点模式最为接近的匹配组。
这种测试方案可以削减不同外部环境造成的偏差并提高实验结果的可信度
,但是此类方案难以获得大量样本,且单位测试成本高,效果检验通过配对
T
检验获得(
excel
中
t.test()
函数提供以上两种
T
检验方法),该框架必须提前设计并确定,并且需要梳理清楚所有参与实验的单元。个人认为比较适合更加细化的经营类场景使用。
2.
两者的共同点:
-
目标(target)变量:本实验要达到的目的,收入的提升还是用户的增加?
-
实验(experimental/treatment)变量:对照组与实验组之间不同的地方,用于测试对目标变量有何种影响的变量。
-
控制(control)变量:实验组与对照组都存在以保证组之间的相似性关系的属性,此属性可以对目标变量产生影响。
-
实验单元(units):进行abtest的主体单位是什么?人,账户,IP地址,店铺?
-
实验期限(cycle):根据测试变量可获取的样本规模确定实验周期的长度。确保实验单元可以在周期内产生表现。
关于控制变量
-
控制变量解释:控制变量类似于建模使用的自变量,代表了单元自身包含的属性,但是控制变量并是为了建模与预测,也不需要达到建模预测的效果,控制变量相当于一座实验组与参照组之间的桥梁,保证两者之间的相似性,从而使实验设计产生意义。
-
避免错误的控制变量:对于同时与实验变量和其他控制变量均存在高度相关性的控制变量,应避免选择此类变量。比如冰淇淋销量与死亡人数呈线性关系,但实际上冰淇淋销量与气温高度相关,死亡人数也与气温高度相关,但是并不能说冰淇淋与死亡人数存在必然联系。
-
选择控制变量的基本过程:列出备选变量>备选变量数据可使用性>控制变量与目标变量之间的关系>控制变量与目标变量间相关性检验>多个控制变量内部相关性检验。
-
控制变量的作用方式: 随机abtest的控制变量作用于收集数据后的评估范围选择阶段;配对abtest可以用控制变量进行组间匹配。
3. ABtest
的基本流程

案例:用Alteryx处理spa store的价格弹性问题
1. 背景
需求价格弹性是指因服务或者商品价格变动体现在需求量方面的响应,具体参考微观经济学弹性部分吧......简单说分析的场景是这样的。有一家spa产品连锁店,有一个面部护理的产品售价98.99,但是他们希望做一个促销活动活动价格可以做到76.99或者87.99,所以需要做一个测试来分析哪一种促销方案更好,其实对零售业来说,更好就是可以带来更大的毛利润了。
2.
实验设计
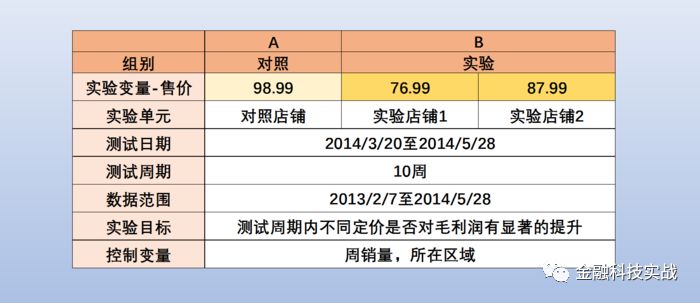
3、通过数据分析选择控制变量
3.1 数据结构
通过实验设计共获得两个数据输入:一是该公司的交易明细数据,二是实验组列表。SKU=StockKeeping Unit(库存量单位),即库存进出计量的单位,可以是以件,盒,托盘等为单位。SKU这是对于大型连锁超市DC(配送中心)物流管理的一个必要的方法。当下已经被我们引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
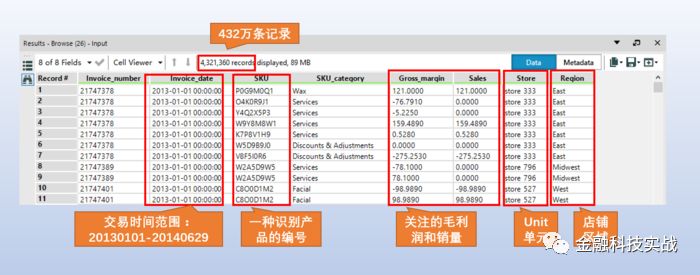 交易数据结构
交易数据结构
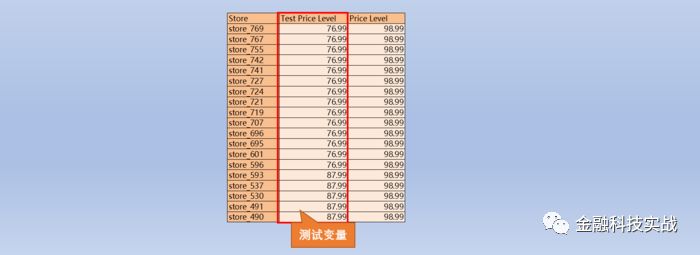
测试组数据源
3.2 控制变量的处理方式
控制变量为更好的匹配实验组与参照组,本案例中选择
周销量
(invoice)来表示店铺销售的
时间趋势及季节特征
,用
周面部产品毛利润
表示测试目标。最终通过周销量,区域双因素决定实验组与参照组的匹配方式。
Alteryx中提供自动分析时间趋势与季节特征的工具——AB trend,该工具要求至少一年的数据量以及附加六期的评估周期。比如测试周期是14周,周期单元为周的实验,AB trend工具分析需要数据量为52周+6周。
4、Alteryx实战
4.1、功能简介
Alteryx的功能区包含了输入输出,数据准备,关联,文本抽取,转换,空间分析,预测,数据调研,ABtest等。
具体包含了哪些功能请自行尝试或者参考官网:https://help.alteryx.com/11.8/index.htm
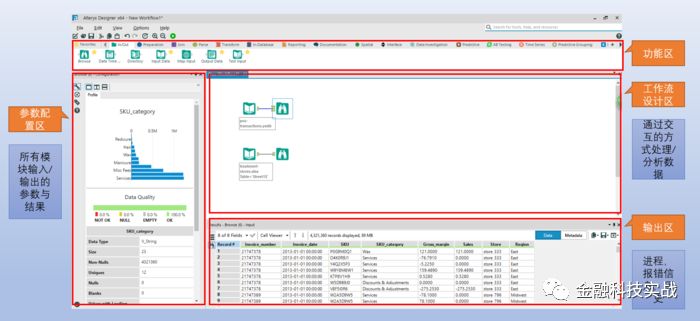
个人体验来说alteryx更加偏重于数据获取,数据处理,到分析方法与建模方法落地的全流程,甚至还融合了许多GIS方面的分析能力。此外alteryx + datarobot也为全自动化建模提供了一条新的途径,如果后期有机会会尝试写一篇alteryx + datarobot的文章。
4.2 数据预处理
4.2.1 导入数据
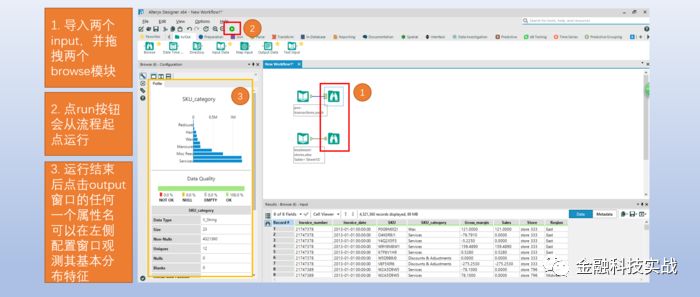
4.2.2 生成周销量,周毛利润(面部),商户测试属性列表
1)数据选择工具:修改变量格式,选择分析变量
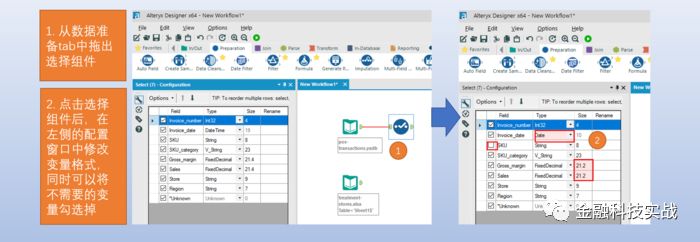
2)数据筛选工具:通过基本逻辑运算符/函数表达式方式筛选数据
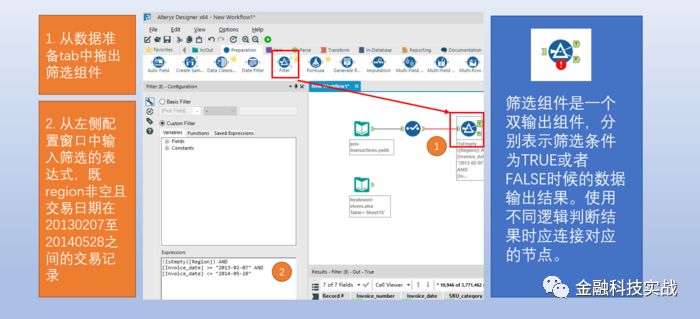 3)变量公式工具:创建新变量,对已有变量进行公式运算与编辑。
3)变量公式工具:创建新变量,对已有变量进行公式运算与编辑。
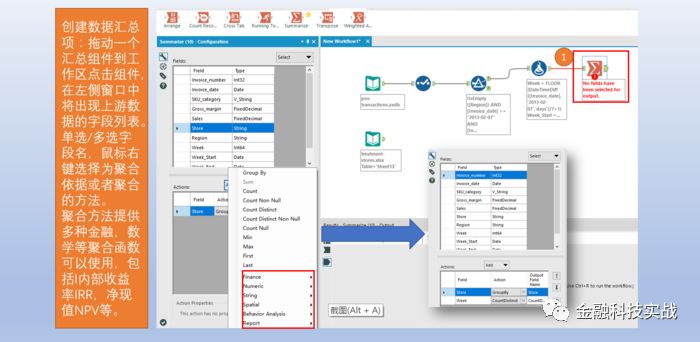
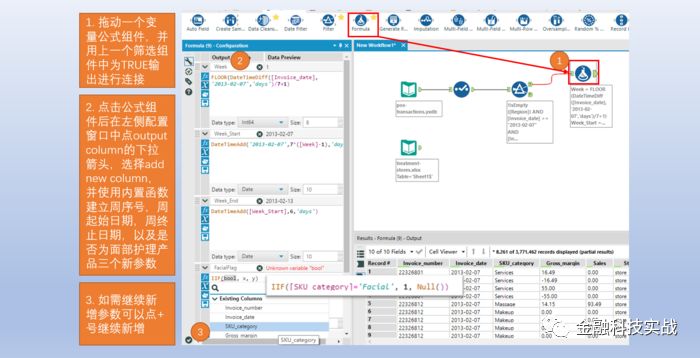 4
)数据汇总:数据聚合与汇总,相当于group by功能,没有having部分。通过这一步,已经获得所有店铺在分析数据范围内共产生了多少个数据考察周期,其中用周表示。下一步则需要将所有表现周期达68的店铺的交易数据筛选出来。这部分需要用到筛选与关联工具。
4
)数据汇总:数据聚合与汇总,相当于group by功能,没有having部分。通过这一步,已经获得所有店铺在分析数据范围内共产生了多少个数据考察周期,其中用周表示。下一步则需要将所有表现周期达68的店铺的交易数据筛选出来。这部分需要用到筛选与关联工具。
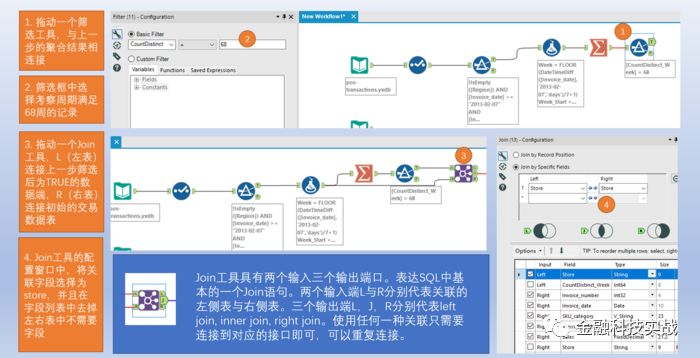
5
)关联工具:通过数据关联获得符合需求的数据。
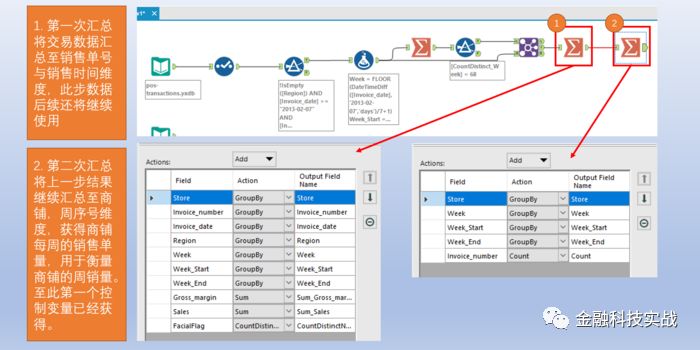
6
)进行两步汇总,产出店铺周销售毛利润(面部护理)分析的中间过程表以及店铺周销量表。
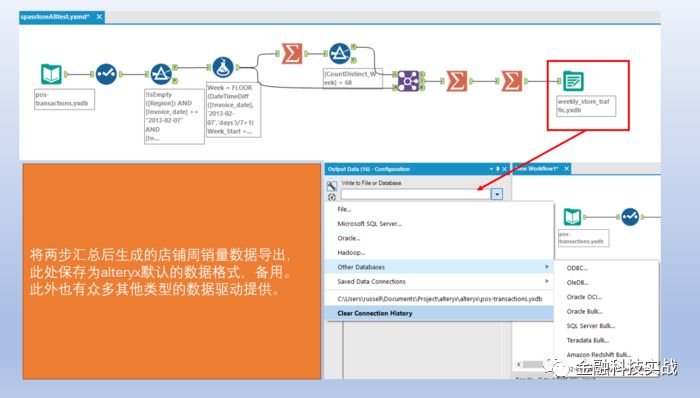
7
)数据导出备用
8
)接下来需要生成一个关于面部产品销售的商店,地区,周次和周毛利润的汇总表,其中周毛利润将作为评估的目标指标(本次实验目的是为了观测价格变动对利润的影响是否显著)。
此外还将根据另一个input测试组名单生成一个全量店铺编号、区域与测试组策略关系表,而且在这里要注意本测试数据中实验变量有两个不同的值,所以是要同时判断两个策略哪个更好的,且要判断跟对照组相比较是否有显著性提升的实验。
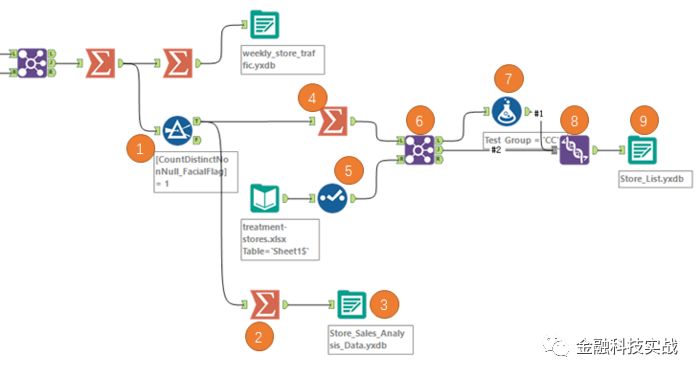 数据处理顺序
数据处理顺序
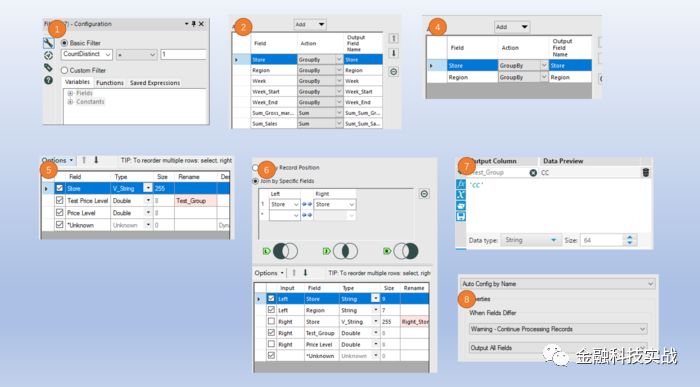
重点步骤的参数设置
4.3 配对组别处理
4.3.1 处理组别配对工作流
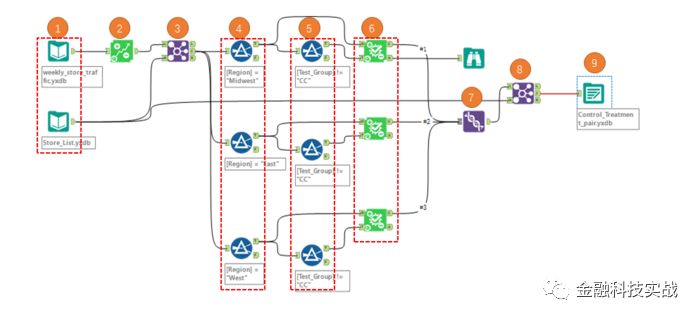
处理组配对的workflow
1
) 导入上一步生成的店铺周销量,店铺列表两个数据。可以将数据从文件夹直接拖入。
2
) 对店铺周销量数据进行时间趋势,季节趋势分解。后面会用到这两个趋势因子作为店铺的模式特征,并通过这两个特征,学习店铺间匹配关系。
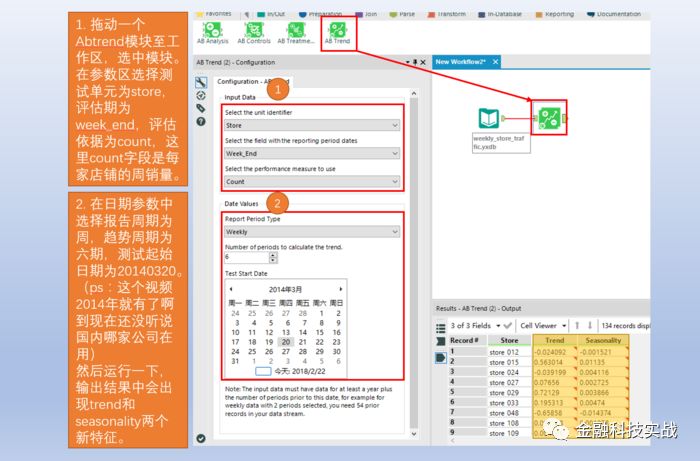 时间趋势与季节因素抽取
时间趋势与季节因素抽取
3
) 将含趋势特征的店铺数据与含测试信息的店铺数据合并,并根据区域拆分测试组与对照组数据。
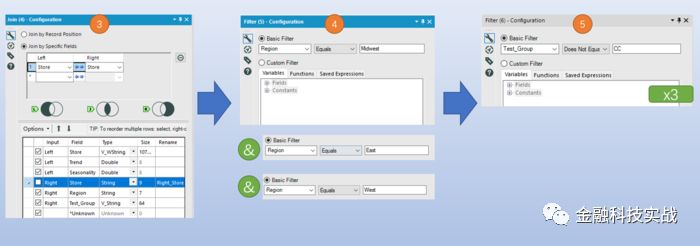 数据分组处理
数据分组处理
4
) 使用AB control工具对实验单元进行模式匹配。
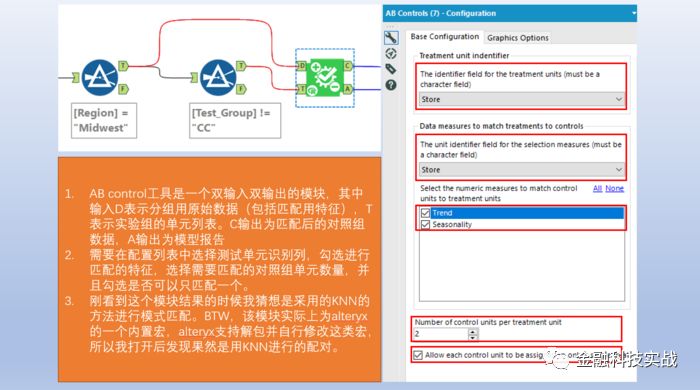 AB control
工具
AB control
工具
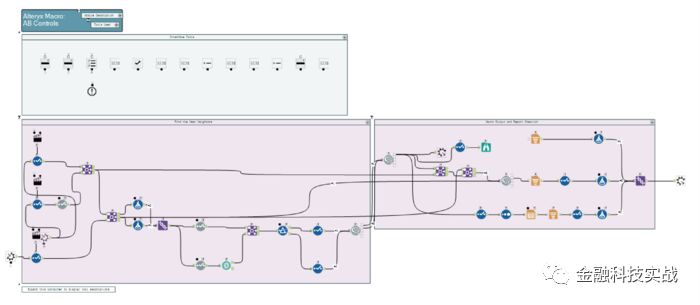
AB control
的宏流程
虽然alteryx公司开放了这些宏的代码(因为R的开源属性?),但是我个人不建议大家把这些代码直接copy走自己去包装类似的系统或者平台用于商业目的~
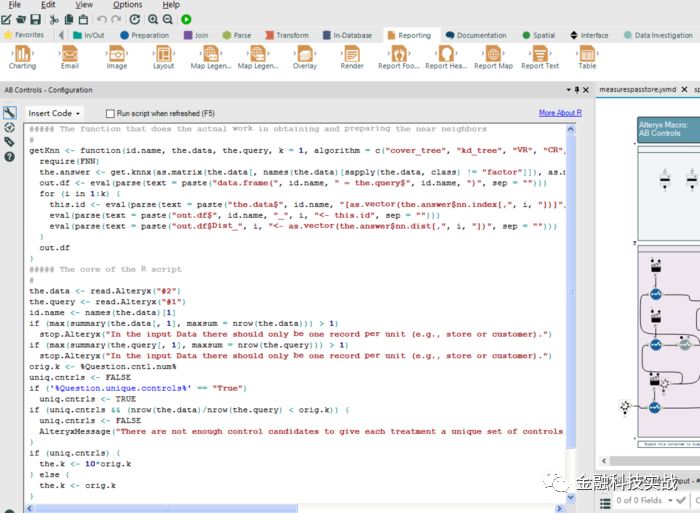 B control
的核心算法部分——KNN
B control
的核心算法部分——KNN
5
) 将分区域匹配后的数据进行整合并输出存档。
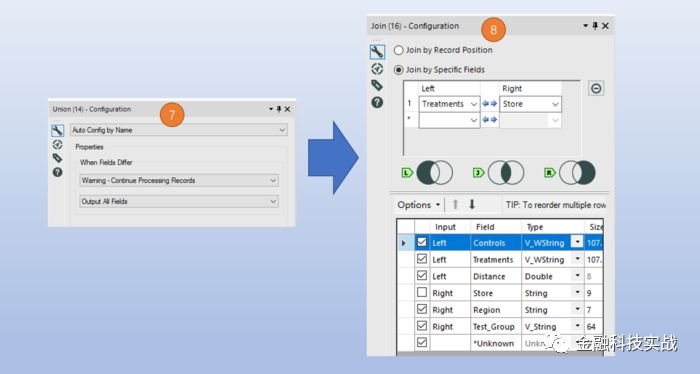 合并数据并将剩余字段整合
合并数据并将剩余字段整合
PS: AB control
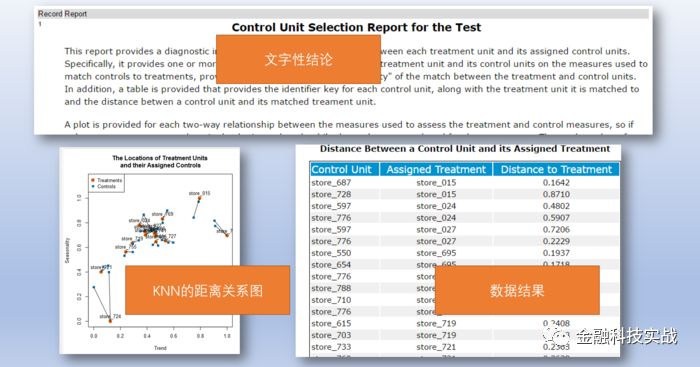
工具运行完成后可以生成模型分析报告,只需要在A输出口连接一个browse模块即可查阅这个报告,alteryx每个分析类模块都会生成一份阅读体验非常好的报告,这点是该软件的非常棒的地方。报告形式具体如下:
4.4 实验评估
4.4.1 实验评估的工作流
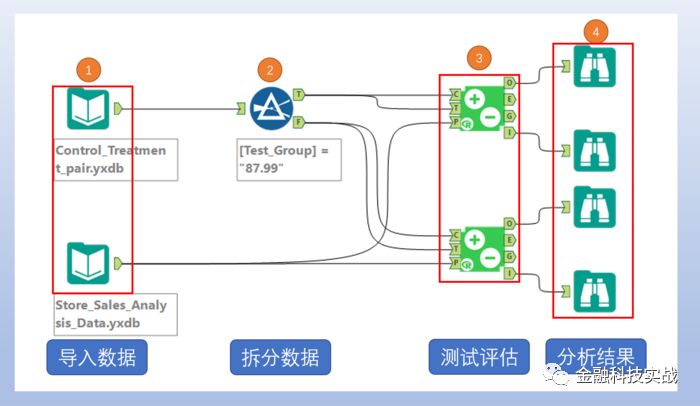
评估工作流
1
) 导入上一步生成了实验组对照组匹配关系数据表,以及第一步生成的店铺面部产品周毛利润表。
2
) 由于本次测试的实验变量有两种选择,所以需要对两种选择进行分离后再评估。这里选择test_group=87.99的组别进入T输出,另外76.99的组别进入F输出。










