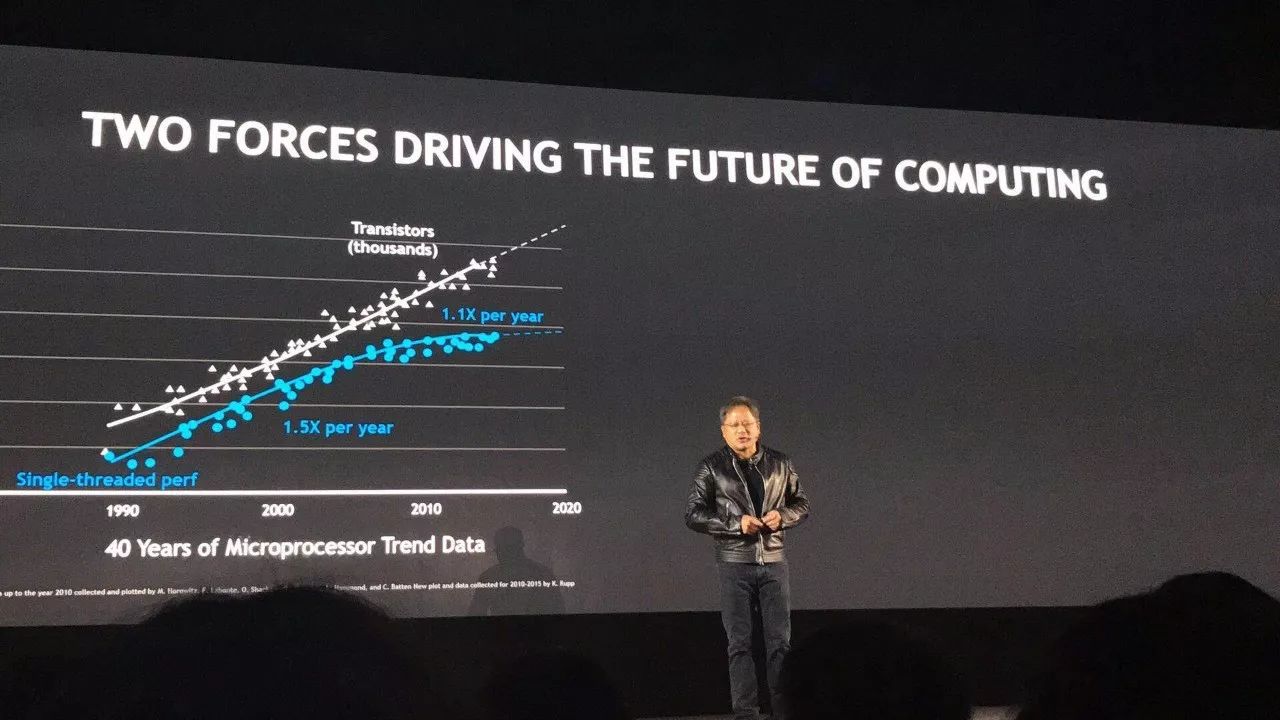
9 月 26 日上午,英伟达 GTC 大会中国站在北京开幕。作为每年 GPU 开发者最为重要的盛会,GTC 和全球一系列活动为开发者们提供了宝贵的培训机会。同时,大会上也展出了当今计算行业最重要的研究成果,涉及领域包括人工智能、深度学习、医疗保健、虚拟现实、加速分析和自动驾驶汽车。在黄仁勋上午的 Keynote 演讲中,我们看到了英伟达和整个业界在人工智能领域的最新进展。作为 GTC 特邀媒体,机器之心亲临大会现场,第一时间对本次大会的亮点进行了报道。
本次 GTC 大会上不乏重要新闻,除了新版优化引擎 TensorRT 3.0 以外,英伟达还宣布与国内 OEM 厂商展开合作,准备共同推出基于 Tesla V100 的 HGX-1 加速器;同时宣布全球首款自动机器处理器 Xaiver,正在与京东合作,共同探索无人机和送货机器人等设备的发展。
大会 Keynote 亮点:
-
发布 TensorRT3 深度学习引擎;
-
全球首款自动机器处理器 Xavier;
-
一系列产业合作。

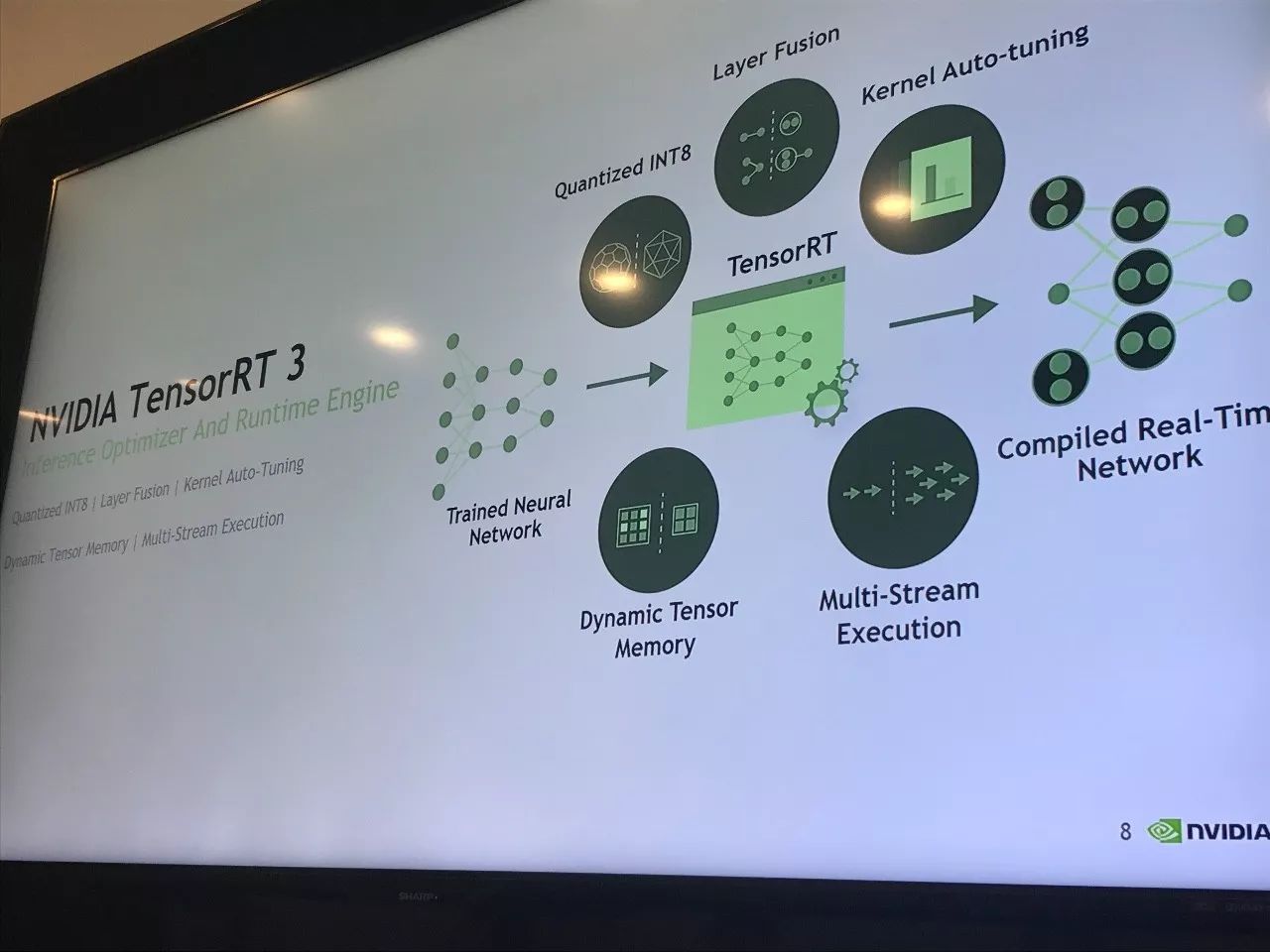
TensorRT3 深度学习引擎
在本次大会中,最为引人关注的就是正式发布的 TensorRT 3.0 了。黄仁勋在大会上花费了大量篇幅对其进行了详细介绍。「深度学习推理引擎」TensorRT 是连接神经网络框架和硬件(GPU)平台的桥梁,它的支持范围覆盖终端设备芯片到服务器级别的各种芯片。由于英伟达的硬件优势,TensorRT 可以将神经网络计算的延迟降低至业内最低水平,这对于面向消费者的应用级产品而言非常重要。
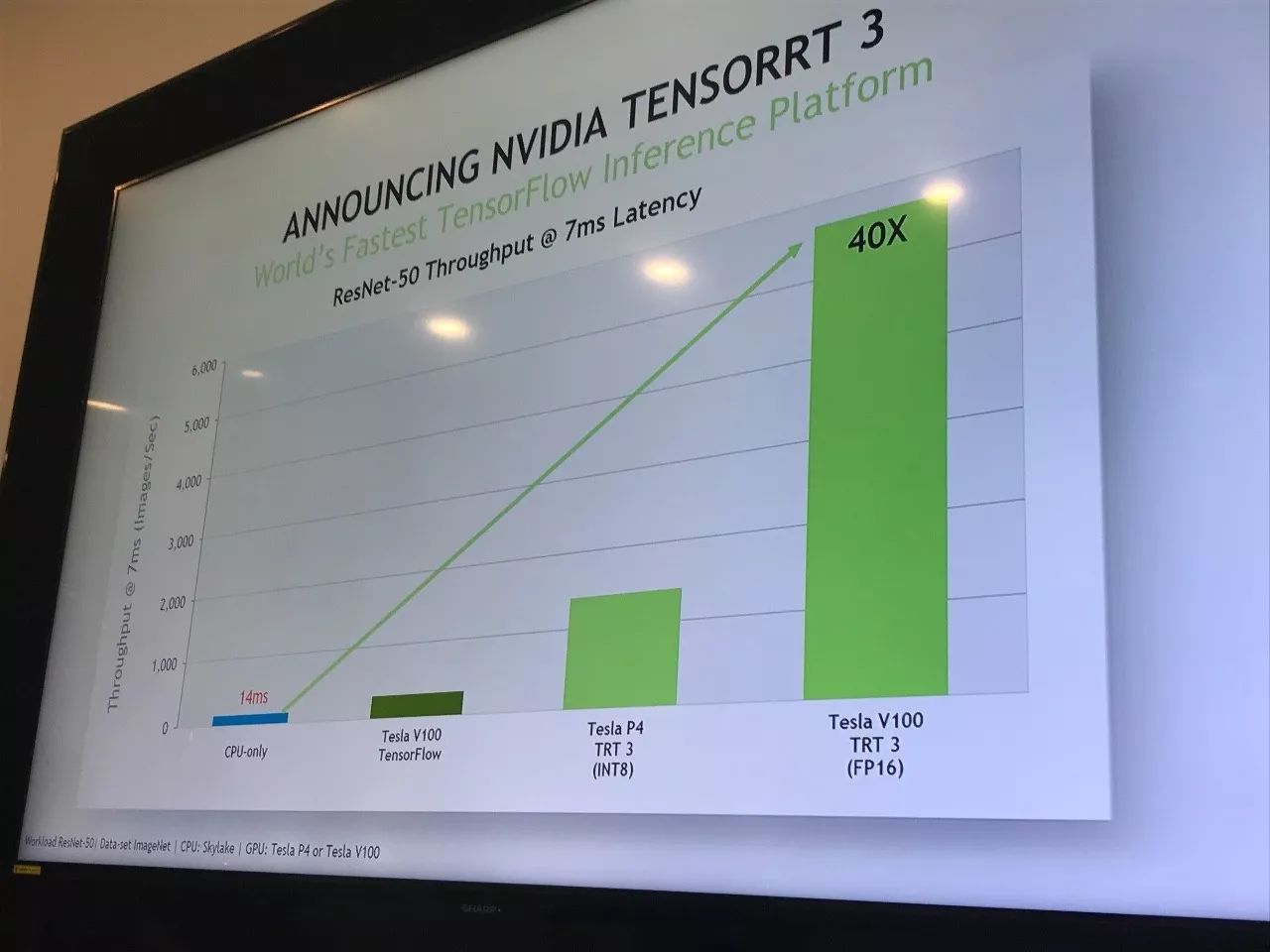
在使用 TensorRT 3.0 之后,ResNet-50 处理图像的速度是 CPU 的 40 倍。
英伟达宣称,新的 TensorRT 3.0 已经支持所有种类的流行神经网络框架(包括 TensorFlow、Microsoft Cognitive Tookit、MXNet、PyTorch、Caffe2、PaddlePaddle 与 Theano),并覆盖支持更多种类的 GPU(包括最近推出的 Jetson TX2 与 Tesla V100)。在过去主要面向于图像处理任务的基础上,英伟达的持续开发让 TensorRT 支持了更多的应用和神经网络种类。作为一个可编程的通用平台,TensorRT 让 GPU 相对其他硬件有了更多优势。

「人工智能在过去的一年里发展很快,但是我们面临的挑战仍然很多,」英伟达人工智能产品负责人 Han Vanholder 表示,「目前我们使用的服务器架构不是为人工智能任务设计的,在这种情况下,如果想完成一种语音识别服务,我们就需要(基于 CPU 的传统服务器)用到价值 10 亿美元的服务器组,而它的功率是 100MW——而这只是用于一种服务的数字。」
除了速度和效率,对于开发者而言,TensorRT 也是一种易于使用的工具。英伟达表示,很多人工智能研发团队在使用中发现,用其他的解决方案可能需要几周,几月才能实现的深度学习项目(需要修改代码、进行编译、测试),在使用 TensorRT 的情况下只需要一天的时间就可以看到结果了,由于高度集成的特性,开发者在实现自己的想法时不需要调整大量手动设置。
「这样就可以让你更加关注与产品本身相关的东西了,」黄仁勋在演讲中说道,「而不是在优化和兼容性上消耗时间。」
将 HGX-1 加速器引入中国
在 GTC 大会上,英伟达也宣布了一系列与国内相关的合作项目。其中,将搭载最新架构 Tesla V100 芯片的 HGX-1 带入中国值得注意。在上午的大会上,黄仁勋宣布,英伟达正在与华为、浪潮、联想等公司展开合作,准备共同推出基于 Tesla V100 芯片的 HGX-1 加速器。希望使用这些技术的用户,可以在近期获得有这些公司生产的 OEM 产品。
高性能计算设备(HPC)是现代科学的基础,从预测天气、发明新药到寻找新能源,大型计算系统能为我们模拟和预测世界的变化。这也是英伟达在新一代 GPU 架构推出时选择优先发布企业级计算卡的原因。在今年五月,英伟达发布全新 Volta 架构时,首先推出的就是专为 HPC 和 AI 的融合而设计的 Tesla V100 计算卡。目前,它主要整合在 HGX-1 加速器中被使用。





