AI 科技评论按
:本文作者 qqfly,上海交通大学机器人所博士生,本科毕业于清华大学机械工程系,主要研究方向机器视觉与运动规划。本文整理自知乎回答:
机器学习中用来防止过拟合的方法有哪些?
给《机器视觉与应用》课程出大作业的时候,正好涉及到这方面内容,所以简单整理了一下(参考 Hinton 的课程)。按照之前的套路写:
是什么
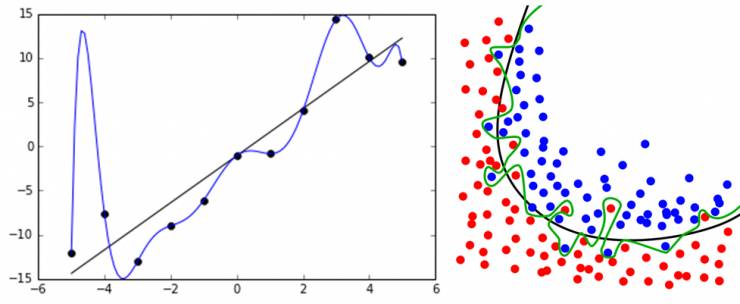
过拟合(overfitting)是指在模型参数拟合过程中的问题,由于训练数据包含
抽样误差
,训练时,复杂的模型将抽样误差也考虑在内,将抽样误差也进行了很好的拟合。
具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
为什么
为什么要解决过拟合现象?
这是因为我们拟合的模型一般是用来预测未知的结果(不在训练集内),过拟合虽然在训练集上效果好,但是在实际使用时(测试集)效果差。同时,在很多问题上,我们无法穷尽所有状态,不可能将所有情况都包含在训练集上。所以,必须要解决过拟合问题。
为什么在机器学习中比较常见?
这是因为机器学习算法为了满足尽可能复杂的任务,其模型的拟合能力一般远远高于问题复杂度,也就是说,机器学习算法有「拟合出正确规则的前提下,进一步拟合噪声」的能力。
而传统的函数拟合问题(如机器人系统辨识),一般都是通过经验、物理、数学等推导出一个含参模型,模型复杂度确定了,只需要调整个别参数即可。模型「无多余能力」拟合噪声。
怎么样
既然过拟合这么讨厌,我们应该怎么防止过拟合呢?最近深度学习比较火,我就以神经网络为例吧:
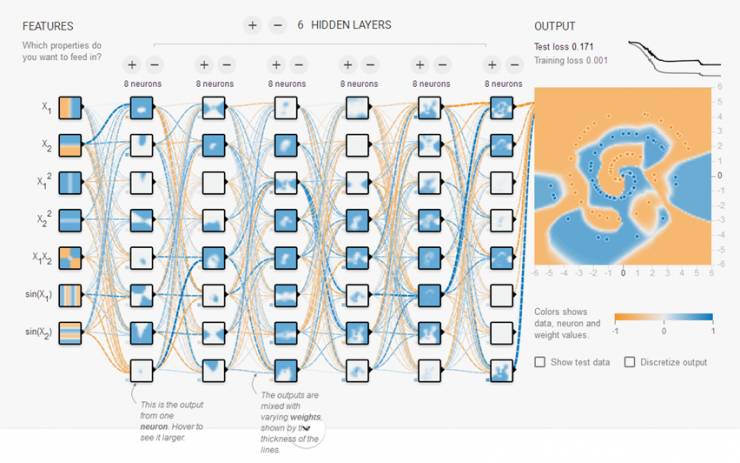
1. 获取更多数据
这是解决过拟合最有效的方法,只要给足够多的数据,让模型「看见」尽可能多的「例外情况」,它就会不断修正自己,从而得到更好的结果:
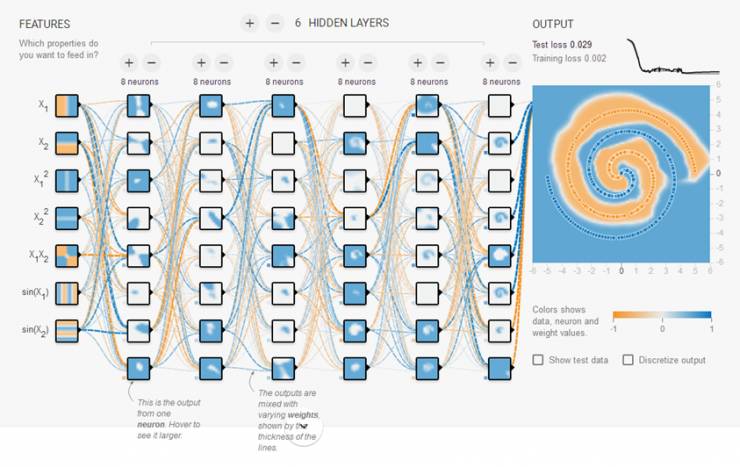
如何获取更多数据,可以有以下几个方法:
-
从数据源头获取更多数据
:这个是容易想到的,例如物体分类,我就再多拍几张照片好了;但是,在很多情况下,大幅增加数据本身就不容易;另外,我们不清楚获取多少数据才算够;
-
根据当前数据集估计数据分布参数,使用该分布产生更多数据
:这个一般不用,因为估计分布参数的过程也会代入抽样误差。
-
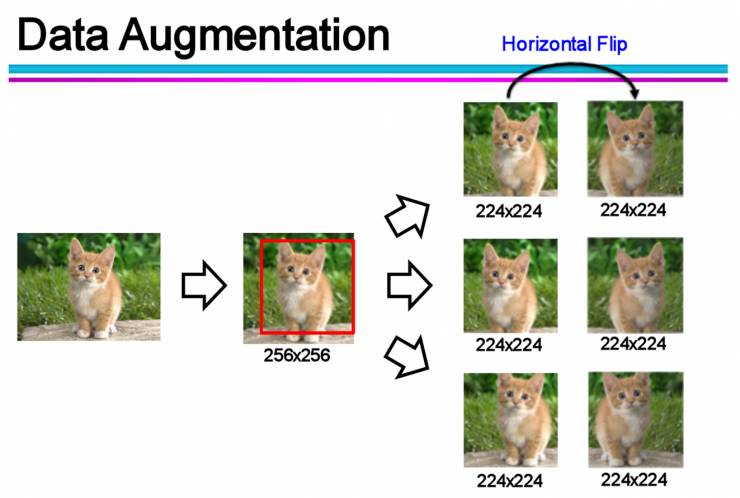
数据增强(Data Augmentation)
:通过一定规则扩充数据。如在物体分类问题里,物体在图像中的位置、姿态、尺度,整体图片明暗度等都不会影响分类结果。我们就可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充;
2. 使用合适的模型
前面说了,过拟合主要是有两个原因造成的:数据太少 + 模型太复杂。所以,我们可以通过使用合适复杂度的模型来防止过拟合问题,让其足够拟合真正的规则,同时又不至于拟合太多抽样误差。
(PS:如果能通过物理、数学建模,确定模型复杂度,这是最好的方法,这也就是为什么深度学习这么火的现在,我还坚持说初学者要学掌握传统的建模方法。)
对于神经网络而言,我们可以从以下四个方面来
限制网络能力
:
2.1 网络结构 Architecture
这个很好理解,减少网络的层数、神经元个数等均可以限制网络的拟合能力;
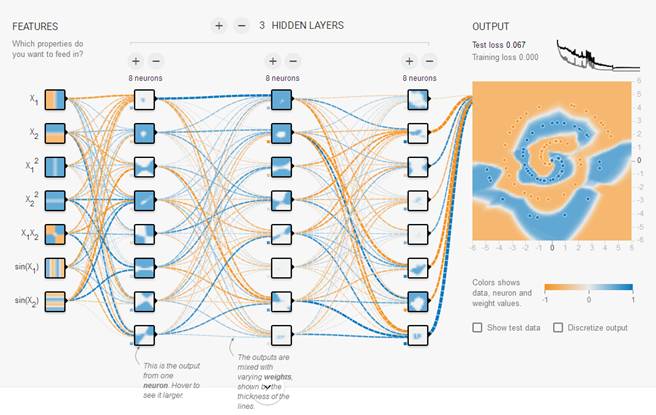
2.2 训练时间 Early stopping
对于每个神经元而言,其激活函数在不同区间的性能是不同的:
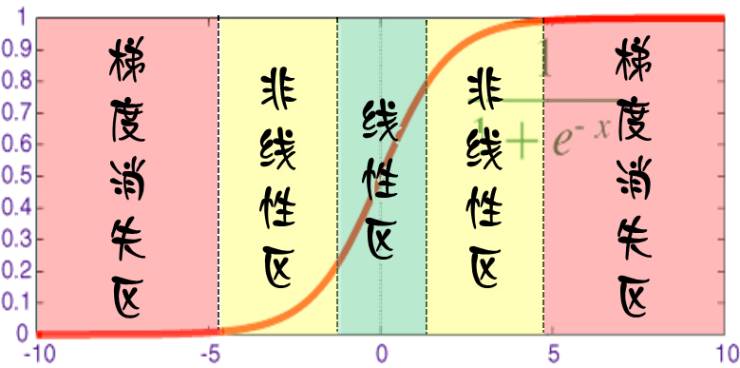
当网络权值较小时,神经元的激活函数工作在线性区,此时神经元的拟合能力较弱(类似线性神经元)。
有了上述共识之后,我们就可以解释为什么限制训练时间(early stopping)有用:因为我们在初始化网络的时候一般都是初始为较小的权值。训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。
2.3 限制权值 Weight-decay,也叫正则化(regularization)
原理同上,但是这类方法直接将权值的大小加入到 Cost 里,在训练的时候限制权值变大。以 L2 regularization 为例:
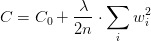
训练过程需要降低整体的 Cost,这时候,一方面能降低实际输出与样本之间的误差C
0
,也能降低权值大小。
2.4 增加噪声 Noise
给网络加噪声也有很多方法:
2.4.1 在输入中加噪声:
噪声会随着网络传播,按照权值的平方放大,并传播到输出层,对误差 Cost 产生影响。推导直接看 Hinton 的 PPT 吧:

在输入中加高斯噪声,会在输出中生成
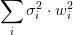 的干扰项。训练时,减小误差,同时也会对噪声产生的干扰项进行惩罚,达到减小权值的平方的目的,达到与 L2 regularization 类似的效果(对比公式)。
的干扰项。训练时,减小误差,同时也会对噪声产生的干扰项进行惩罚,达到减小权值的平方的目的,达到与 L2 regularization 类似的效果(对比公式)。
2.4.2 在权值上加噪声
在初始化网络的时候,用 0 均值的高斯分布作为初始化。Alex Graves 的手写识别 RNN 就是用了这个方法
Graves, Alex, et al. "A novel connectionist system for unconstrained handwriting recognition." IEEE transactions on pattern analysis and machine intelligence 31.5 (2009): 855-868.
- It may work better, especially in recurrent networks (Hinton)








