
作者简介:

陈尔冬
链家网 技术总监
曾于新浪任职技术总监,负责私有云平台研发与运维并支撑新浪微博从零至上市高速发展的过程。后于华为任职技术专家,致力于提升华为公有云运维能力。
今年初受鸟哥邀请加入链家网,负责基础设施研发与运维工作。曾译《奔跑吧,Ansible》一书。最近几年一直致力于研究如何根据公司不同情况,打造出最适合的运维体系。
1、前言

作者先前就职于新浪,是新浪私有云的负责人。从微博初始,一直到微博上市参与了项目全过程,历次的比较大的技术改造都有参与。
作者受鸟哥邀请,加入链家做 SRE,链家是个比较特别的模式。
到链家之后发现链家既用公有云亚马逊 AWS,同时也有自己的数据中心、服务器、基础设施,可能未来链家会考虑把它逐渐做成混合云。
从私有云到公有云到混合云经历过来,作者的经验恰恰都可以覆盖,本文的思路希望给读者带来一些新的想法。
2、链家网的第三种运维
为什么叫第三种运维?链家这两年提出了一个概念:第三种中介。
其实链家很早以前就一直在探索我们怎么样利用技术来加速业务。最早是传统 IT 公司思路,现在是利用互联网,如何把互联网和房产中介相结合。
很早以前链家的老板找到 IBM 做咨询,探索到底要不要做互联网,要推翻线下的中介经纪人制度吗?
IBM 的专家们也给链家做了非常深度的咨询,最后负责做战略的这位 IBM 的专家就加入到了链家,也是我们链家网现在的 CEO。
链家在传统线下中介和完全互联网化的房产中介之间找到一个灰度,既不是传统的中介也不是完全互联网化去经纪人的互联网中介,而是一种线下的经纪人和线上的互联网产品相结合的新型中介,所以链家叫它第三种中介。
我思考自己的职业生涯,做了这么多年的运维,一直以来想要追求运维的模式和链家探寻的结果很像。我们现在会看到很多朋友们探索的理念,不管是某种运维还是 DevOps 还是 SRE。
其实我们都在谋求寻找最终的目标,到底是一个什么样的运维状态?它和我们的传统运维在某种程度上可能是相对立的。
因为我们不希望利用人工,或利用自己的责任心和劳动时间,去解决这样的问题,所以我们将这两种运维的模式暂且放在对立的两端。
我们在真实世界中存在的运维的模式实际上是第三种运维模式,是在这种完美理想化的运维模式和传统的运维模式之间的一种运维模式。现实世界既是美好的又是真实的又是残酷的,不可能完全按照你的理想复制。
我可以拿出一些我们的项目细节给大家举例,但是有的项目是不开源的,我们和大家面临的问题也很难完全一样,只能在这吹一吹,也许对大家参考价值有限。
其实我更希望去介绍我们遇到某个问题的时候,是通过什么样的思路去选择什么样的方案。根据我们的环境选择什么样的方案,也许我们选择的方案或者我们选择的技术点和大家所在的环境不一定适合。
但是我们所思考的方式,觉得应该讲一讲,大家可能会有一些收获。因为我们都是做计算机的,我们都会本能的觉得这个世界上可能就是 0 和 1,但是做了一时间工作以后,工作的种类是开发也好,运维也罢,你会发现这个世界不只是 0 和 1。
我们经常会讲上线要灰度,实际上我发现所有的事情都要灰度。我在华为的时候也有这样的经历,华为的老板有一个很著名的讲话,我们要灰度一切,要把一些的工作乃至管理都做到灰度化。
灰度一切的意思是说做事不能一刀切,要么这么干,要么那么干。在过程之中会有一个甚至多个中间状态,甚至最终落地也落在中间状态。这个工作的思路,恰恰和我对运维工作的一个理念相符。
3、聊聊新技术

首先我们聊聊虚拟化和容器,不管是虚拟化还是容器都是很专业的一个领域,可以聊得很深入。说到虚拟化和容器,大家可能会本能的想到两个很有名的开源项目,一个是 OpenStack,一个是 Docker。
3.1 面对新技术的误区
在做这些工作的时候我会听到很多声音,比如,我以前在新浪经常会出来吹牛,说新浪几乎在国内最早做云计算的公司。有些人就会觉得很夸张,会觉得 04 年就敢说在做云计算,八成就是在公司搭一堆虚拟机,连管理平台都没有。
另外一个例子,有的朋友听说链家想做混合云,问我:“你的方案是什么?是基于容器做还是基于 OpenStack?”
我还遇到这样的朋友,在他们心里,私有云如果不用 OpenStack,就是基于 VM 去自己建设,类似很多这样的例子。
不过要说让我感触最深的,还是前阵子听到有个朋友说“现在做运维,除了用 Docker 就没啥新技术了。”
这些声音代表了一类朋友,他们觉得容器就是混合云的唯一方案,觉得 OpenStack 或者虚拟化技术就是云计算的唯一方案,这些技术与产品之间是划等号的。如果要做云计算,就一定要用容器、或者虚拟化技术。
我认为这样的观点有失偏颇,所以想以容器这个技术为切入点,讲述我对新技术的理解过程。
3.2 我对容器的理解

这是一张今年秋天日本京都的一张照片。具体地点是日本京都著名地标清水寺。清水寺秋天的时候会有很多红叶,特别美。大家看清水寺舞台下面的红叶,密密麻麻的很美。但是仔细看,一大片红叶还是挺乱的。

但是我们想象拿一片红叶在手上,红叶上会有脉络。就像上图,它是很有序的,而且你拿到每一个红叶一定是有很相近的脉络。
我们可以这样理解,一片红叶就是乱中有序。但这跟容器有什么关系呢?别着急,我们按照这样的一个思考方式研究容器。

Container 本来的意思是集装箱,集装箱和刚才我讲的红叶有可以类比的。集装箱其实与红叶是相反的,序中有乱。我们看到这个码头全都是集装箱,是不是特别有规律?可能颜色不一样,但是大小都是一样的。
我们如果需要城市运输、轮船跨国运输,以及在码头将货物搬上或搬下货轮,只要匹配这个尺寸,就可以完成工作。至于它里面运的什么东西,实际搬运的真实货物都不用去考虑了。不管食品还是电器,只要把集装箱运过来了,这个东西就过来了,我理解容器就像这样,序中有乱。
3.3 容器的应用场景
什么时候你需要序中有乱?
我举一个例子,如果我所在的公司很大。然后有上百个团队去做开发,每一个团队开发的技术架构都不一样,使用的语言也不一样:有的是 JAVA,有的是 PHP,有的是 Python,有的是 C/C++。即便同样是 JAVA 语言,有的是 HTTP 协议的,有的是私有协议。
那么如果我的团队来运维这所有的系统,这个架构相当乱。需要为所有的这些系统做运维,怎么做?
开发团队很大,加起来有上万人,我就算有几百人,肯定也做不过来。这时候就适合使用容器技术,实现序中有乱。乱在你集装箱内,对我的团队来讲,这里就是上万个集装箱,每一个集装箱的尺寸是完全一样的,我做一个基础设施可以去把集装箱从这里搬到那里,就搞定了。
集装箱内的东西每个研发团队自己去搞定,这是一种工作模式。我认为容器在这个领域是非常适合的,也就是没有办法让架构从头到脚有序的时候。
但是,我们工作的场景是什么样的呢?有的公司里面是不乱的。比如我原来在新浪的时候有一段阶段新浪所有项目都是 PHP,而且都用 Apache 做 Web 服务器。我们又设立了一些规范让研发团队去遵守,整体架构完全统一的。这时候我们还要必要容器吗?
我个人觉得这是需要考虑的,为什么呢?因为如果你要引入容器,终究会增加成本。等价交换是这个世界的铁则。你用了新的技术容器,它帮你解决了序中有乱的问题,你就要管理它。
3.4 容器Tomcat
我们如果采用新技术,但只有五个人,首先我有疑问:这能搞得定吗?是否可以不用容器,为什么一定要用呢?。再则,我们的架构里其实已经有容器了。Tomcat 就是个容器,从系统层看到的都是 Tomcat,但里面是不同的 JAVA 的程序,其实也是个乱之有序的架构。
这时候有朋友会提出问题,说 Docker 是可以实现资源隔离的。Tomcat 没有这个功能,可能会资源互相影响。其实 Docker 实现资源隔离是利用了 CGroup。为什么 Docker 用了
CGroup
,我们不能用呢?最后看看一个没有 Docker 的弹性计算方案。
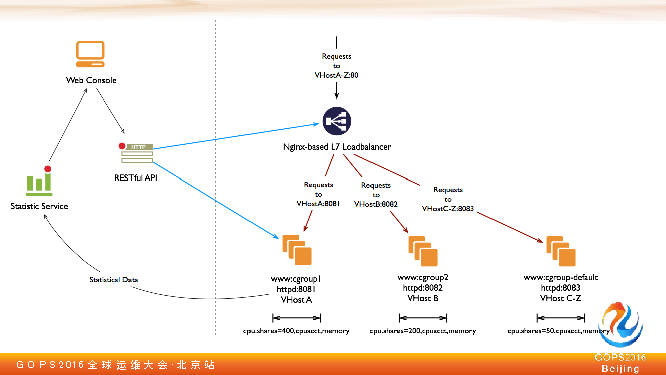
下面那三个我们可以认为跑在同一台服务器上.同一台服务器跑了多个应用实例,我们可以理解为每个 Tomcat 监听不一样的端口,我在七层负载均衡上把端口映射到不一样的端口上。
这个时候一个服务器上就有多个容器了,只不过容器是 Tomcat,不是 Docker。我们再对这多个 Tomcat 利用
CGroup
做资源隔离甚至资源统计。如果你有一套强大的管理系统,可以把这七层映射关系以及这些 Tomcat 配置文件配置起来的话,那么这套弹性计算云就完成了。
我个人理解,这套基础设施比 Docker 对于我的团队来讲更容易管理。因为我的团队这些工程师,他以前是做传统运维的,对 Tomcat 很熟,对于 Ansible、Puppet、SaltStack 这些配管工具很熟。
他们管理物理服务器非常熟悉,但让他们今天开始管容器,他需要一些时间。再加上容器项目本身成熟度问题,我认为对我团队这就是目前为止最好的方案。
4、最合适的才是最佳方案
未来 Tomcat 会不会变成容器呢?不好说。也许以后 Docker 成熟了,某些方面比我这个方案更好。现在这个时间点,我认为对于我的团队来讲它是一个更好的方案。
话又回到开篇所提及。对于您的团队是不是一定是这个方案是最好的方案呢?也许吧。
但我可以把我思考的思路以及我的理念写出来去做一个分享。在您的场景可以按我们的方式重新去思考一下,也许对您的团队来讲用 Docker 是更好的方式,也许您会探索出新的方案也未可知。
4.1 破解“被堵塞难题”
今天,大家都爱讲微服务。不管这个服务微不微,服务化已经是标配了。服务化后,整个架构中有数十个或上百个服务,每个服务做一件事,服务和服务之间的通信通过 RPC 实现。
4.2 探寻RPC堵塞的原因
服务之间 RPC 是很常见的事。如果一切都正常,那么一切都好,但如果某一个可能会被调用的资源变得慢的话,这个问题就来了。
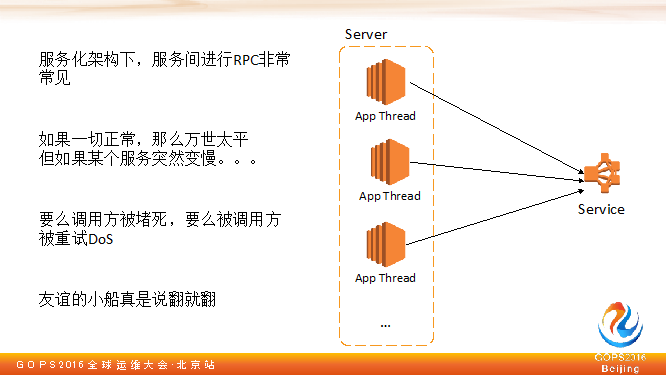
如果有一个资源被调用慢,会产生两种结果:
对于超时这类的结果,一般调用方会重试,因为我调用没成功,逻辑跑不下去了。本来执行处理就慢,已经存在问题的情况了,但调用方又重试,500 毫秒就重试一次,就把这个服务给压死了。
友谊的小船说翻就翻,不光是服务会出现这样的故障,不同服务的团队也容易打翻友谊的小船互相指责。这边说我是被你拖死的,那边说你是把我压死的,你的超时时间设计不合理。
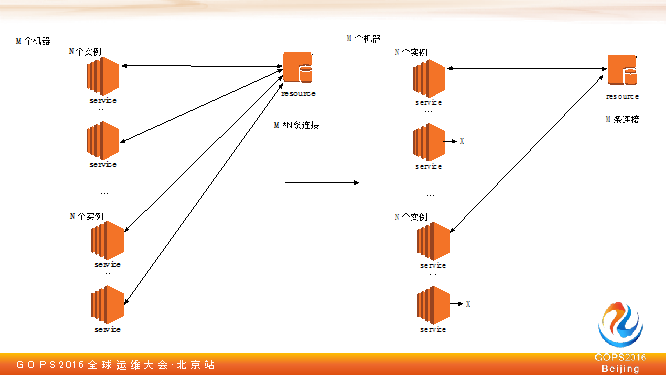
遇到这种情况怎么解决这个问题呢?回到刚才在容器技术用到的思考方式,要想去解决,我们先分析到底这个问题点在哪。
我觉得这里面有两个问题:
4.3 解决问题的思路
在这个点我们团队从系统层面角度给了一个方案,我们现在的方式是这样:当我慢了之后,M 个服务器,N 个进程,你就是 M+N 全部调到服务方了。我有 M 台机器,有 N 个进程,最后还是M个服务器去调这个服务,我肯定还是有调用,可以让它去尝试,如果慢就不要再调了。
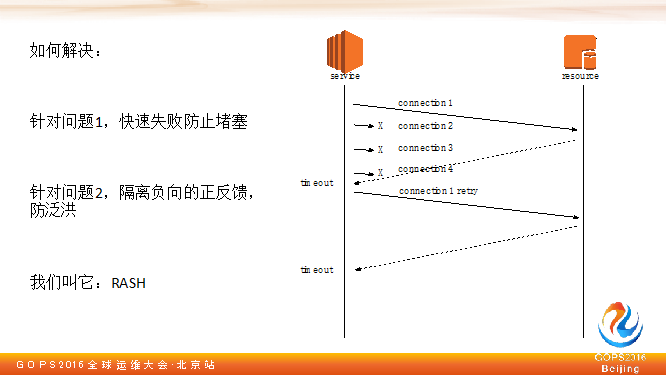
我们给的方案是这样,针对问题一,如果说我调用超时时间设得比较慢,在系统层检测到后端的延迟,在慢的时候快速失败,防止堵塞。




