
编者按:本文由文蔺在众成翻译平台上翻译。书接上文,昨天我们介绍了webRender出现的背景,今天用漫画来解释一下它是如何学习游戏引擎让网页渲染如丝般顺滑~
像游戏引擎一样使用 GPU
如果停止尝试猜测需要什么图层呢?如果不考虑区分绘制与合成,仅考虑每一帧绘制像素呢?
这听起来似乎很荒谬,但实际有先例可循。现代视频游戏重新绘制每个像素,并且比浏览器更可靠地保持每秒 60 帧。他们以一种意想不到的方式做到了这一点...他们只是重绘整个屏幕,无需创建那些用于最小化绘制内容的失效处理矩形和图层。
这样渲染网页不会更慢吗?
如果在 CPU 上绘制的话,的确会更慢。但 GPU 就是用来做这事的。
GPU 正是用于极端并行处理的。我在上一篇
关于 Stylo 的文章
中谈到过并行的问题。通过并行,机器可以同时执行多种操作。它可以一次完成的任务数量,取决于内核数量。
CPU 通常有 2 到 8 个内核。GPU 往往至少有几百个内核,通常有超过 1,000 个内核。
虽然这些内核的工作方式有所不同。它们不能像 CPU 内核那样完全独立地运行。相反,它们通常一起工作,在数据的不同部分执行相同指令。
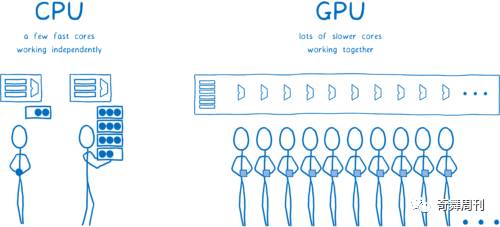
填充像素时, 我们正需要这样。每个像素可以由不同的内核填充。一次能够操作数百个像素,GPU 在像素处理方面上比 CPU 要快很多...当所有内核都在工作时确实如此。
由于内核需要同时处理相同的事情,因此 GPU 具有非常严格的步骤,它们的 API 非常受限。我们来看看这是如何工作的。
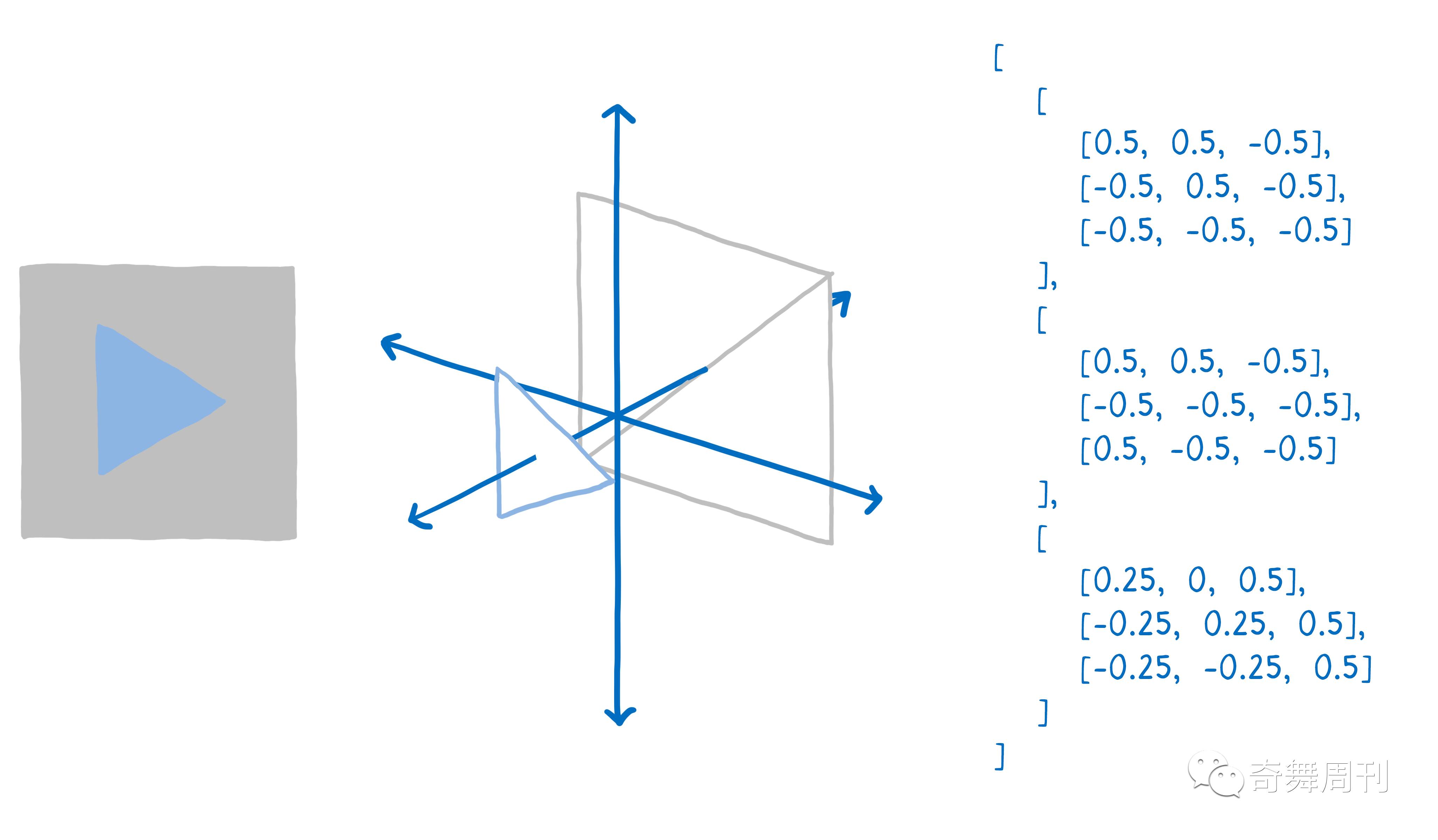
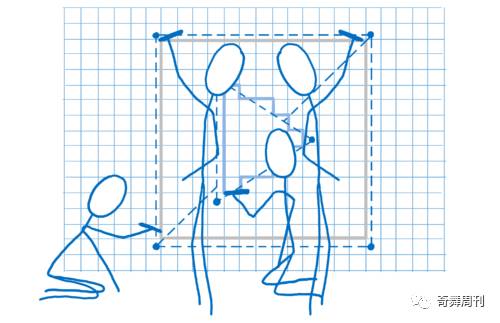
首先,你需要告诉 GPU 需要绘制什么。这意味着给它传递形状,并告知如何填充。
要达到目的,首先将绘图分解成简单形状(通常是三角形)。这些形状处于 3D 空间中,所以一些形状可以在其他形状背后。然后将三角形所有角顶点的 x、y、z 坐标组成一个数组。
然后发出一个绘图调用 —— 告诉GPU来绘制这些形状。
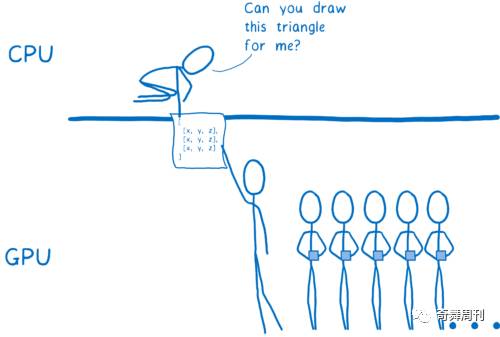
接下来由 GPU 接管。所有的内核将同时处理同一件事情。它们会:
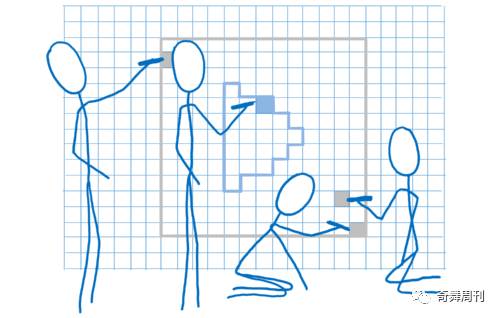
最后一步可以通过不同的方式完成。要告诉 GPU 如何处理,可以传给 GPU 一个称为像素着色器的程序。像素着色是 GPU 中可编程的几个部分之一。
一些像素着色器很简单。例如形状是单一颜色的,则着色器程序只需要为形状中的每个像素返回同一个颜色。
另外一些情况更复杂,例如有背景图像的时候,需要搞清楚图像对应于每个像素的部分。可以像艺术家缩放图像一样…在图像上放置一个网格,与每个像素相对应。这样一来,只需知道某个像素所对应的区域,然后对该区域进行颜色取样即可。这被称为纹理映射(texture mapping),因为它将图像(称为纹理)映射到像素。
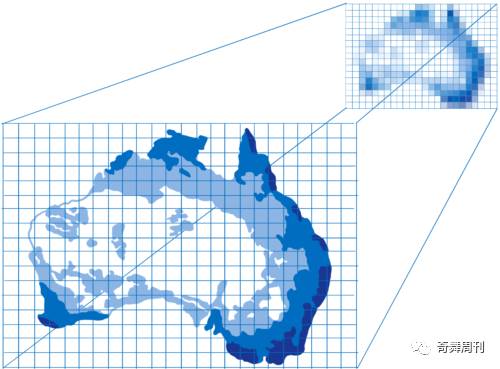
针对每个像素,GPU 会调用像素着色器程序。不同内核可以同时在不同的像素上并行工作,但是它们都需要使用相同的像素着色器程序。命令 GPU 绘制形状时,你会告诉它使用哪个像素着色器。
对几乎所有网页来说,页面的不同部分将需要使用不同的像素着色器。
在一次绘制中,着色器会作用于所有形状,所以通常需要将绘制工作分为多个组。这些称为批处理(batches)。为了尽可能利用所有内核,创建一定数量的批处理工作,每个批次包括大量形状。
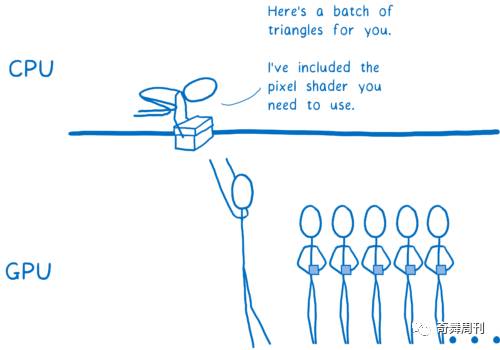
这就是 GPU 如何在数百或数千个内核上切分工作的。正是因为这种极端的并行性,我们才能想到在每一帧中渲染所有内容。即便有这样极端的并行性,要做的工作还是很多。解决起来还需要费些脑筋。该 WebRender 出场了……
WebRender 如何利用 GPU
回过头再看下浏览器渲染网页的步骤。这里将产生两个变化。
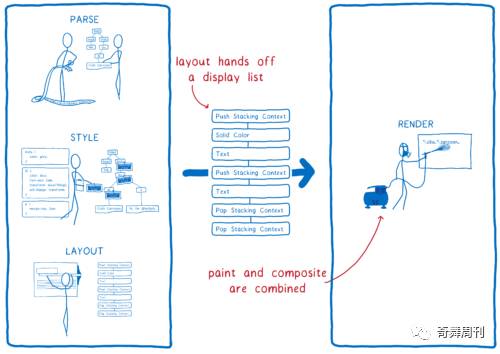
1. 绘制与合成之间不再有区别。它们都是同一步骤的一部分。GPU 根据传递给它的图形 API 命令同时执行它们。
2. 布局步骤将产生一种不同的数据结构。之前是帧树(或 Chrome 中的渲染树)。现在将产生一个显示列表(display list)。
显示列表是一组高级绘图指令。它告诉我们需要绘制什么,并不指定任何图形 API。
每当有新东西要绘制时,主线程将显示列表提供给 RenderBackend,这是在 CPU 上运行的 WebRender 代码。
RenderBackend 的工作是将这个高级绘图指令列表转换成 GPU 需要的绘图调用,这些绘图调用被分在同一批次,加快运行速度。
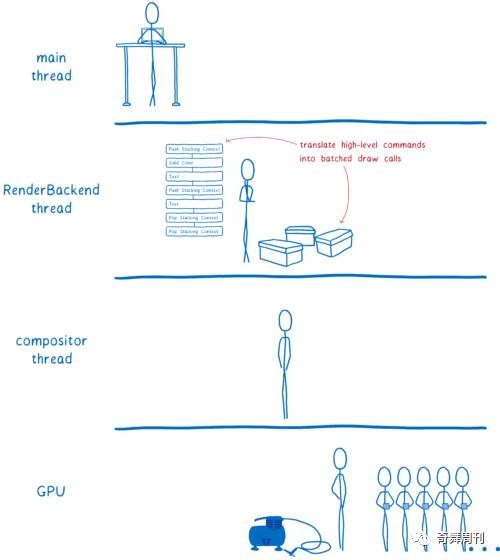
然后,RenderBackend 线程将把这些批次传递给合成器线程,合成器线程再将它们传递给 GPU。
RenderBackend 线程传递给 GPU 的绘图调用需要尽可能快运行。它为此使用了几种不同的技术。
从列表中删除任何不必要的形状(早期剔除)
节省时间的最好办法是什么都不做。
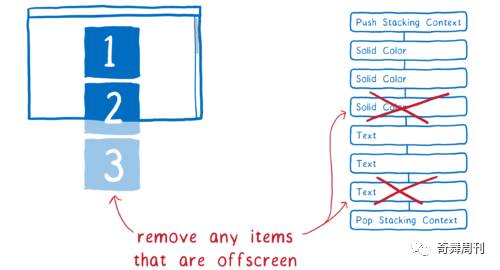
首先,RenderBackend 可以减少显示列表项目。它会识别哪些项目将真正出现在屏幕上。为此,它将查看一些东西,如每个滚动盒的滚动距离。
如果形状的某些部分在盒子内,则该形状将被包括在需要绘制的列表中。否则将被删除。这个过程叫做早期剔除。
最小化中间纹理数量(渲染任务树)
现在有了一个树状结构,其中只包含将要用到的形状。这个树被组织成此前提过的堆叠上下文。
CSS filter 和堆叠上下文等这些效果,让事情变得复杂了。假设有一个透明度为 0.5 的元素,该元素包含子元素。你可能觉得每个子元素都将是透明的……但实际上整个组才是透明的。
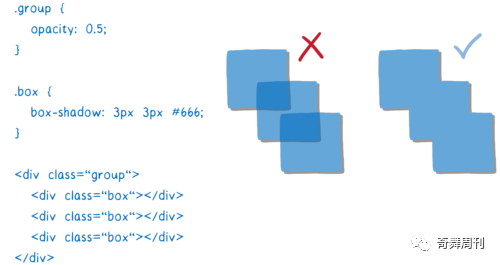
因此需要先将该组渲染为一个纹理,每个子元素都是不透明的。然后,将子元素加入到父元素中时,可以更改整个纹理的透明度。








