今天和大家来说的这个技术很有意思,因为大家都在夜晚拍照过,拍出来的效果要不是模糊要不是曝光时间短带来噪点。
虽然现在很多手机都有夜间模式,但是你们知道真正的背后技术吗?
今天我们就来详细的说说黑暗中我们技术是怎么看世界的!
在低光照甚至黑暗条件下,我们拍出高质量的照片一直是非常有挑战性的科研问题,这主要原因是由于低光子数和低信噪比给相机成像带来了很大的困难。曝光时间过短会给图像带来噪点,而长时间曝光又容易导致图像模糊,费时费力,在现实中可行性低。
传统算法提出了各种去噪、去模糊和增强技术,但是它们的有效性在极端条件下是非常有限的,例如夜晚的视频成像。为了支持基于深度学习的低光图像处理流水线的开发,于是收集了一个大规模的夜间成像数据集,它由短曝光夜间图像以及相应的长曝光参考图像组成。使用这个数据集,开发了一个基于全卷积网络端到端训练的低光图像处理流水线。该网络直接读入原始传感器数据,然后前向输出一张高清图像。这个技术克服了传统图像处理流水线需要多模块且夜间成像效果差的不足。并且展示了新数据集颇具前景的结果,并分析了影响性能的因素,以及未来研究的机会。
噪声存在于任何成像系统中,但它使成像在低光下特别具有挑战性。高ISO可以用来增加亮度,但它也放大噪音。后处理,如缩放或直方图拉伸,可以应用,但这不能解决低信噪比,因为低光子计数。在弱光下提高信噪比的物理手段有:打开光圈、延长曝光时间和使用闪光灯。但每一种方法都有其自身的缺点。例如,增加曝光时间会导致相机抖动或物体运动造成模糊。
下图中就展示了本次提出技术的设置。这里的环境漆黑透亮:照相机的照明不足0.1 lux。曝光时间设置为1/30秒。孔径为f/5.6。在ISO 8000,这通常被认为是高,相机产生的图像本质上是黑色的,尽管高光感的全帧索尼传感器在ISO 409,600,这是远远超出大多数相机的范围,场景的内容是可以识别的,但即使是昏暗,噪音,和颜色扭曲。正如我们将要展示的,即使是最先进的去噪技术也不能消除这种噪音,也不能解决颜色偏差问题。另一种方法是使用
burst of images
,但
burst alignment
算法在极端弱光条件下可能会失败,而burst 流程不是为视频捕获而设计的(例如,由于在burst中使用了“幸运成像”)。

于是,提出了一种新的图像处理流程,通过数据驱动的方法来应对极低光摄影的挑战。具体来说,我们训练深层神经网络来学习微光原始数据的图像处理流程,包括颜色转换、去噪、降噪和图像增强。
该流水线是经过端到端的训练,以避免噪声放大和误差积累,这是传统相机处理流程在这种情况下的特点。现有的大多数处理低光图像的方法都是根据合成数据或真实的低光图像进行评估的。据我们所知,没有公开的数据集来训练和测试处理具有多种真实世界数据和真实的快速微光图像的测试技术。
因此,收集了一个新的原始图像数据集,在弱光条件下快速曝光。每个微光图像都有相应的长曝光、高质量的参考图像。在新的数据集上得到了很有希望的结果:低光图像放大了300倍,成功地降低了噪声,并进行了正确的颜色转换。最后系统地分析了流程的关键要素,并讨论了今后的研究方向。
See-in-the-Dark
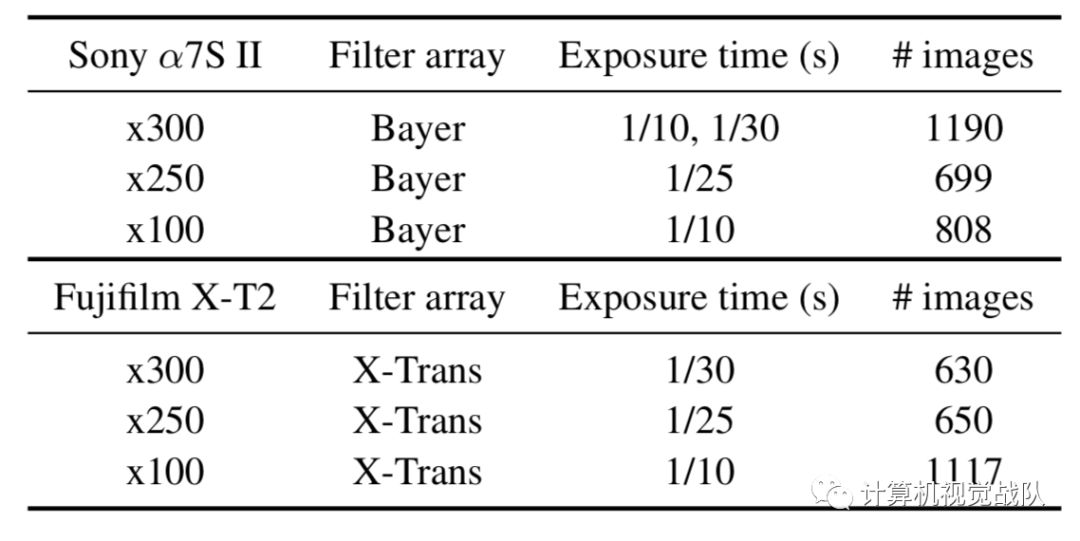
数据集包含室内和室外图像。这些户外照片通常是在夜间、月光或路灯下拍摄的。室外场景中摄像机的照度一般在0.2到5 lux之间。
室内的图像甚至更暗。他们是在封闭的房间里被捕获的,他们经常关灯,并为此目的设置了微弱的间接照明。
室内场景中摄像机的照度一般在0.03~0.3 lux之间。输入图像的曝光设置在1/30至1/10秒之间。
相应的参考(ground truth)
图像是以100至300倍的曝光时间拍摄的:即10至30秒。由于参考图像的曝光时间很长,所以数据集中的所有场景都是静态的。下表概述了数据集,且下图显示了一个参考图像的小样本。在每个条件下,大约20%的图像被随机选择以形成测试集,另有10%的图像是为验证集选择的。

关键技术(Pipeline)
传统的图像处理流程从图像传感器获取原始数据后,采用白平衡、去噪、锐化、颜色空间转换、伽马校正等一系列模块。这些模块经常被调到特定的相机上。Jiang等人[
1
]建议使用大量的局部、线性和学习(L3)滤波器来逼近现代消费映射系统中的复杂非线性流程。然而,无论是传统的流程还是L3,都不能成功地处理快速低光成像,因为它们无法处理极低的信噪比。Hasinoff等人[
2
]描述了一种用于智能手机相机的
burst
成像流程。该方法可以通过对齐和混合多幅图像产生较好的效果,但由于需要密集的对应估计,引入了一定程度的复杂性,而且由于使用幸运成像等,很难扩展到视频捕获。
[
1
]
H. Jiang, Q. Tian, J. E. Farrell, and B. A. Wandell. Learning the image processing pipeline. IEEE Transactions on Image Processing, 26(10), 2017.
[
2
]
S.W.Hasinoff,D.Sharlet,R.Geiss,A.Adams,J.T.Barron, F. Kainz, J. Chen, and M. Levoy. Burst photography for high dynamic range and low-light imaging on mobile cameras.ACM Transactions on Graphics, 35(6), 2016.

于是提出了用端到端学习来直接对低速图像进行单图像处理。具体来说,训练一个全卷积网络 (FCN) [
3
,
4
]来执行整个图像处理流程。最近的工作表明,纯FCNs可以有效地代表许多即时处理算法[
5
,
6
]。受到这项工作的启发,并研究了这种方法在前三层低光成像中的应用,不对传统的摄像机处理流程产生的正常sRGB图像进行操作,而是对原始传感器数据进行操作。
[
3
]
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Compu- tation, 1(4), 1989.
[
4
]
J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
[
5
]
Q. Chen, J. Xu, and V. Koltun. Fast image processing with fully-convolutional networks. In ICCV, 2017.
[
6
]
L. Xu, J. Ren, Q. Yan, R. Liao, and J. Jia. Deep edge-aware filters. In ICML, 2015
.
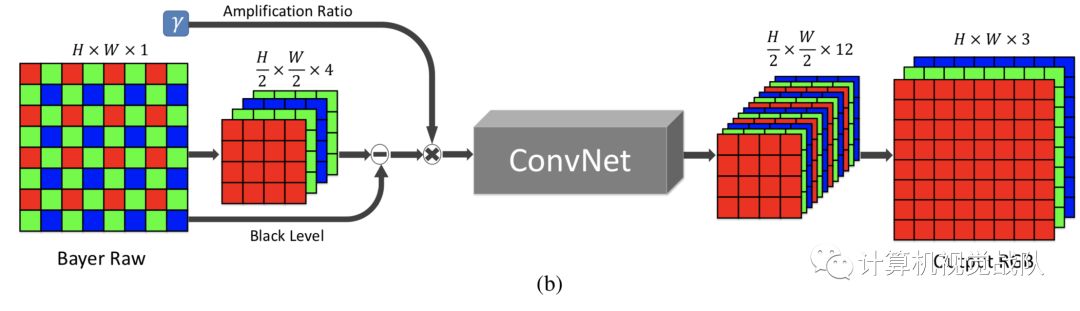
上图b中显示了所示流程的结构。对于Bayer阵列,将输入分为四个通道,相应地,在每个维数中,空间分辨率降低了2倍。对于X-Trans
数组(如图所示),原始数据被排列成6×6块;通过交换相邻的元素,将其封装成9个通道,而不是36个通道。减去black level,并按期望的放大率(例如,x100或x300)对数据进行缩放。将打包和放大的数据输入全卷积网络。输出为12通道图像,空间分辨率为一半。这个半尺寸的输出由一个子像素层处理,以恢复原来的分辨率。
缩放比决定输出的亮度。在该技术流程中,缩放比设置为Exter-Nally,并作为输入提供给流程,类似于摄像机中的ISO设置。下图显示了不同放大倍数的影响。用户可以通过设置不同的放大因子来调节输出图像的亮度。测试时,流程进行盲噪声抑制和颜色变换,网络直接在sRGB空间输出处理后的图像。

实验



下表展示了每个条件下的平均PSNR/SSIM


Discussion







