5 月 27 日,机器之心主办的为期两天的全球机器智能峰会(GMIS 2017)在北京 898 创新空间顺利开幕。中国科学院自动化研究所复杂系统管理与控制国家重点实验室主任王飞跃为本次大会做了开幕式致辞,他表示:「我个人的看法是再过几年,我们 90% 的工作是人工智能提供的,就像我们今天大部分工作是机器提供的一样。我们知道人工智能会给我们提供一个更美好的未来。」大会第一天重要嘉宾「LSTM 之父」Jürgen Schmidhuber、Citadel 首席人工智能官邓力、腾讯 AI Lab 副主任俞栋、英特尔 AIPG 数据科学部主任 Yinyin Liu、GE Transportation Digital Solutions CTO Wesly Mukai 等知名人工智能专家参与峰会,并在主题演讲、圆桌论坛等互动形式下,从科学家、企业家、技术专家的视角,解读人工智能的未来发展。

下午,第四范式联合创始人、首席研究科学家陈雨强发表了主题为《机器学习模型:宽与深的大战》的演讲,他不仅探讨分享了学界中的深度模型和工业界中的宽度模型,同时还分析了这两种模型的各自特点。以下是该演讲的主要内容:
工业界需要可扩展的机器学习系统
人工智能的兴起是计算能力、机器学习以及分布式计算发展的结果。在实际的工业界之中,我们需要一个可扩展的机器学习系统(Scalable Machine Learning System),而不仅仅是一个可扩展系统(Scalable System)。

第一点,数据处理的能力随机器的增加而增加,这是传统的可扩展。第二点,智能水平和体验壁垒要随着业务、数据量的增加而同时增加。这个角度的 Scalable 是很少被提到的,但这个层面上的可扩展性才是人工智能被推崇的核心原因。
比如,过去建立竞争壁垒主要通过业务创新或是通过借助新的渠道(比方说互联网)提升效率。在这样的方式中,由于产品本身相对容易被抄袭,那么资本投入、运营与渠道是关键。但随着数据的增加与 AI 的普及,现在有了一种新的方式,就是用时间与数据创造壁垒。可以看出,由人工智能产生的竞争壁垒是不断循环迭代而得到提升、更容易拉开差距的高墙。
可扩展的机器学习系统需要高 VC 维
我们知道 VC 维理论,该理论形式化地描述了机器学习算法对复杂函数拟合的能力。在机器学习中,VC 维度越高,模型越复杂,所需要的数据量也越多。

如上图所示,因为过去的数据不大,训练损失函数在不断下降,而测试损失函数则先下降再上升。因此有小数据量的模型要避免过拟合,VC 维就不能太高。因此我们需要控制 VC 维,以让训练数据的测试损失和训练损失同时下降。
但随着如今数据量剧增,我们发现低 VC 维模型效果并不理想,但高的 VC 维模型的性能在不断上升。因此,在我们有越来越多数据时,要关心的是欠拟合而不是过拟合,要关心的是怎样提高 VC 维让模型更加聪明。
因此,如果要成功在工业界使用人工智能,VC 维是非常重要的问题。
如果我们已经有很多数据,那么提升 VC 维的方法有两条:一种是从特征提升,一种是从模型提升。我们把特征分为两类:一类特征叫宏观特征,比如描述类特征如年龄、统计类特征如整体的点击率、或整体的统计信息;另一类为微观特征,最典型的是 ID 类的特征,每个人都有特征,每个物品也有特征,人和物品组合也有特征。相应的模型也分为两类,一部分是简单模型如线性模型,另一类是复杂模型如深度学习模型。因此,我们可以引出工业界机器学习四个象限的概念。
模型 X 特征,工业界机器学习的四个象限
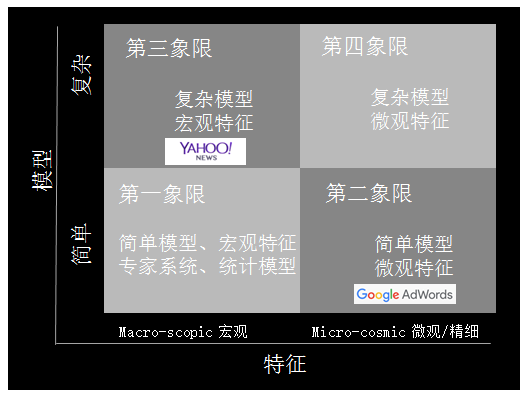
如上图所示,第一象限是简单模型加宏观特征,在现在的工业界比较难以走通,很难得到极致化的优化效果。这个象限内,要解决的问题是怎样找出特征之间的关系与各自的统计特性。
第二象限是简单模型加复杂特征,最成功的典型案例是 Google AdWords。Google AdWords 占 Google 70% 以上的收入,Google 的展示广告也是用的这样的技术,占了 Google 大概剩下的 20% 左右的收入。
第三象限是复杂模型、宏观特征典型的应用,比如 Bing ads,2013 年他们提出 BPR(Bayesian Probit Regression)来 Model 每个特征的置信度。
第四象限,复杂模型和微观特征,现在还是热门研究的领域,它最难的一点是模型的规模实在太大。这种模型可能会有极其巨量的参数。虽然数据很多,但如此多的参数还是很难还是难以获得的。所以怎么解决模型的复杂问题、正则化问题,还是目前研究的重要方向。
如何沿着模型优化?
沿着模型优化主要由学术界主导。他们主要的研究是非线性模型,总结起来有三种方法:核函数、提升方法和深度神经网络。提升方法和深度神经网络现在非常流行,提升方法最经典的是梯度提升树(GBDT),而深度神经网络也在很多行业产生了颠覆性的变化。大约十年前,核函数也是很流行的。借助核函数,支持向量机(SVM)有了异常强大的非线性能力。
对于工业界中的具体问题,基于思考或观察得到新的假设,加入新的模型、结构,以获得更多的参数,这是工业界优化这一项限的步骤。
因此,通过机器学习首先,观察数据;第二,找到规律;第三,根据规律做模型的假设;第四,对模型假设中的参数用数据进行拟合;第五,把拟合的结果用到线上,看看效果怎么样。这是模型这条路在工业界上优化的方法。
如何沿特征优化?
特征优化主要是工业界主导的。就像刚才提到的,Google 使用了上千亿的特征,百度也使用了上千亿的特征,这些特征都是从最细的角度描述数据,模型也是简单粗暴。
沿模型优化这条路的主要特点是什么?模型一定是分布式的,同时工程挑战是非常大的。针对这些难点,很多会议上都在研究如何高效并行,以及如何保证高效并行的时候快速收敛。ASP、BSP 等模型和同步、异步的算法,都是为了保证高效分布式的同时能快速收敛。
应为线性模型理论较为成熟,工业界对模型本身的优化相对没有那么多,其更主要的工作是针对具体的应用提取特征。之所以有那么多特征,是因为我们对所有观察到的微观变量都进行建模。
所以,当我们不能给出比较好的数据假设时,不知道为什么产生突变时,可以更多的依赖数据,用潜在参数建模可能性,通过数据学到该学的知识。
宽度还是深度?
那么沿着宽度走好还是沿着深度走好?其实并没有那个模型在所有情况下都更好,换一句话说机器学习没有免费的午餐(No Free-Lunch):不存在万能模型。

没有免费午餐定理,即所有的机器学习都是一个偏置,这个偏置是代表你对于数据的假设,偏置本身不会有谁比谁更好这样的概念。如果使用更多的模型假设,就需要更少的数据,但如果模型本身越不符合真实分布,风险就越大。当然我们也可以使用更少的模型假设,用数据支持模型,但你需要更多的数据支持,更好的特征刻画,然后表示出分布。总结起来对于我们工业界来说,机器学习并没有免费的午餐,一定要做出对业务合适的选择。
宽与深的大战
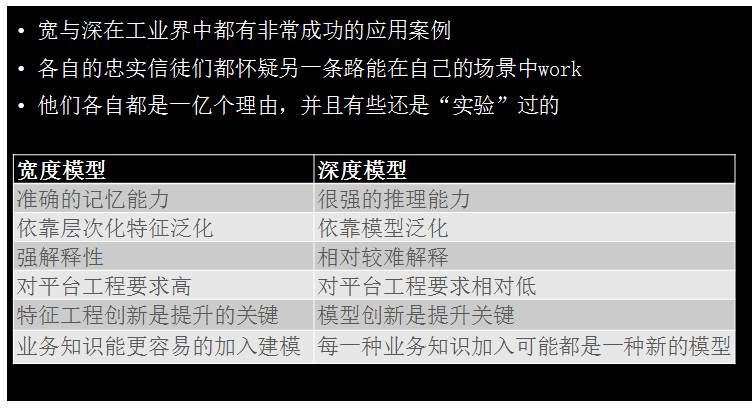
追求更高的 VC 维有两条路:一个是走宽的、离散的那条路,即 Google AdWords 的道路;也可以走深的那条路,比如深度学习。这就是深与宽的大战,因为宽与深在工业界都有非常成功的应用案例,坚信宽与深的人很长一段时间是并不互相理解的。坚信深度学习、复杂模型的人认为,宽的道路模型太简单了,20 年就把所有的理论研究透彻,没有什么更多的创新,这样的技术不可能在复杂问题上得到好的结果。坚信宽的模型的人,攻击深度模型在某些问题上从来没有真正把所有的数据都用好,从来没有发挥出数据全部的价值,没有真正的做到特别细致的个性化。的确深度模型推理做得好,但个性化、记忆方面差很多。
宽与深的模型并没有谁比谁好,这就是免费午餐定理:不同业务使用不同的模型,不同的模型有不同的特点。我们对比一下宽度模型与深度模型:宽度模型有比较准确的记忆能力,深度模型有比较强的推理能力;宽度模型可以说出你的历史,在什么情况下点过什么广告,深度模型会推理出下次你可能喜欢哪一类东西。宽度模型是依靠层次化特征进行泛化的,有很强的解释性,虽说特征很多,但是每一个预估、为什么有这样的预估、原因是什么,可以非常好的解释出来;深度模型是非常难以解释的,你很难知道为什么给出这样的预估。宽度模型对平台、对工程要求非常高,需要训练数据非常多、特征非常多;深度模型对训练数据、对整个模型要求相对较低一点,但现在也是越来越高的。还有一个非常关键的区别点,如果你是 CEO、CTO,你想建一个机器学习的系统与团队,这两条路有非常大的区别。宽度模型可以比较方便与统一的加入业务知识,所以优化宽度模型的人是懂机器学习并且偏业务的人员,把专业的知识加入建模,其中特征工程本身的创新是提升的关键;如果走深度模型,模型的创新是关键,提升模型更关键来自于做 Machine Learning 的人,他们从业务获得知识并且得到一些假设,然后把假设加入模型之中进行尝试。
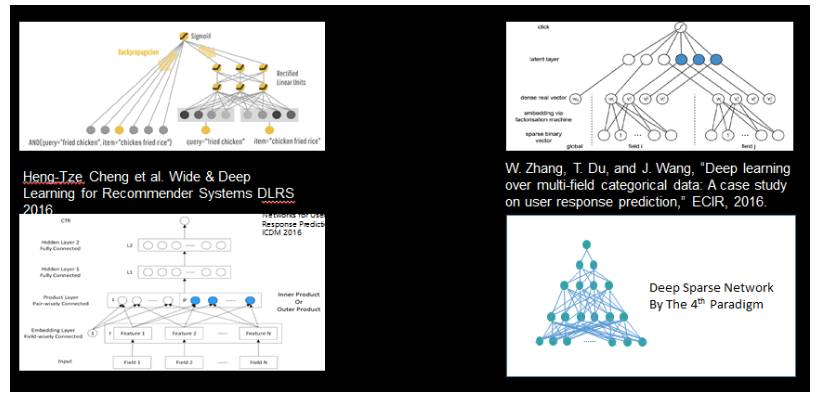
同时宽与深的结合已经逐渐成为一个研究热点,Google 在 16 年 4 月份发表的一篇论文,介绍他们的最新工作「Deep & Wide Model」。模型分为 Deep 与 Wide 两部分,好处是它既能对比较细的特征有记忆,同时也有推理的能力。我们认为将来的方向都应该朝这路走。
除此之外,近期还有不少工作在探索这个方向,总的来说这方面还是非常前沿的、非常热门的研究领域。
如何上线:从监督学习到强化学习
不管是宽模型、深模型还是兼顾宽与深的模型,其实线下做好的模型实际上是一个监督学习模型,并不能保证它线上效果好。
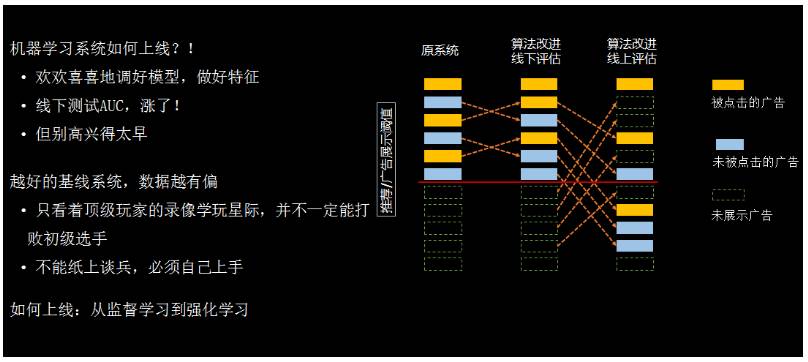
再跟大家分享一点,宽度和深度其实是两条路数、两个派系。在我们想替换的时候,就会发现深度模型很难把它替换成宽度模型,或者宽度模型很难把它替换成深度模型。因为如果我们真正把它应用于线上系统时,其实是一个强化学习问题,而不只是简单的机器学习问题。你在线上使用的时候会发现,你碰到的数据和你线下训练的数据是不一样的,你的基线模型效果越好,你的数据是越有偏差,训练出来的模型越难真正在线上产生好的效果。所以说,我们需要有很多机制让这个事情做得更好,包括更多的强化学习等方式。
最后总结一下,深度学习和宽度学习,其实并没有谁比谁一定更好,我们要针对具体的业务,选择最合适你的机器学习框架、机器学习模型来解决我们的问题。
更多有关GMIS 2017大会的内容,请点击「阅读原文」查看机器之心官网 GMIS 专题↓↓↓









