自从阿粉经历过上次的大数据杀熟事件之后,明显感觉现在的平台对于用户非常的不友好呀,只要你高频的搜索某些关键词的同时,却往往是越对比,直接就买在了最高峰,就和买股票一样,每次总感觉能抄底,殊不知买在了天台。于是阿粉想了个办法,把所有的数据扒拉下来,我自己做对比,也不去搜索了,省的平台上总是根据我的搜索内容去进行推荐。

Java如何做爬虫
大家在想到爬虫的时候,一定想说,爬虫,这东西不是学Python的人员才能做的么?我们Java能做呢?阿粉想告诉大家的是,可以,Java语言这么多年,历时这么久,怎么可能没有这些内容呢,于是阿粉就开始了学习了 Java 的爬虫道路。
Jsoup
阿粉在介绍这个类之前,肯定先得说说我们通常看到的内容是由什么组成的,现在比如说我们做开发的都知道,至少我们在电脑端访问某东,某宝的数据的时候,他们给我们反馈的数据都是通过 HTML 来进行展示的,比如说这个样子:
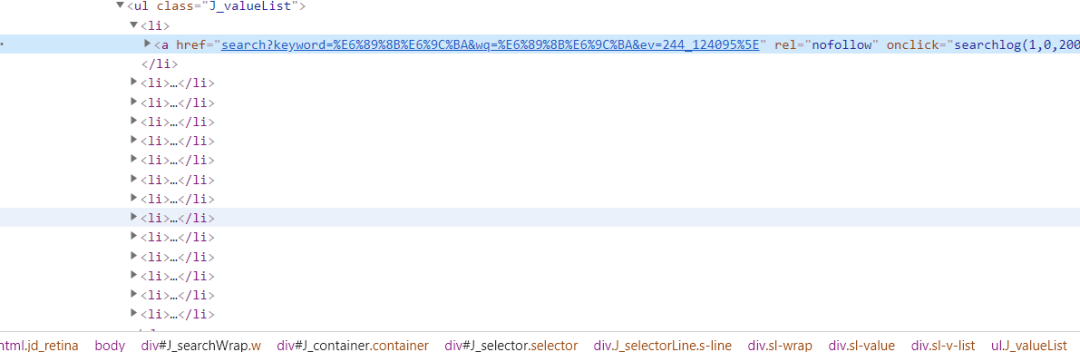
在开发的肯定都是知道,这些都是些什么意思,阿粉在这里我们就不再进行详细的介绍,说这个 HTML 到底是个啥东西了,阿粉需要介绍的是 Jsoup ,然后告诉大家怎么使用 Jsoup 这个类爬取京东的数据。
正如官方文档所给我们提示的内容,怎么去解析一段 HTML 代码 :
String html = "First parse"
+ "Parsed HTML into a doc.
";
Document doc = Jsoup.parse(html);
而这个 Document是什么呢?我们可以输出一下看一眼,顺带着看看源码解释,毕竟嘛,开发人员不看这个类是干嘛的,就不是个合格的程序员不是,
输出内容:
First parse
Parsed HTML into a doc.
其实可以看出这里,Document实际上是给我们输出了一个新的文档,而且是整理之后的,相当于为之后的分析 HTML 做了专业的准备。
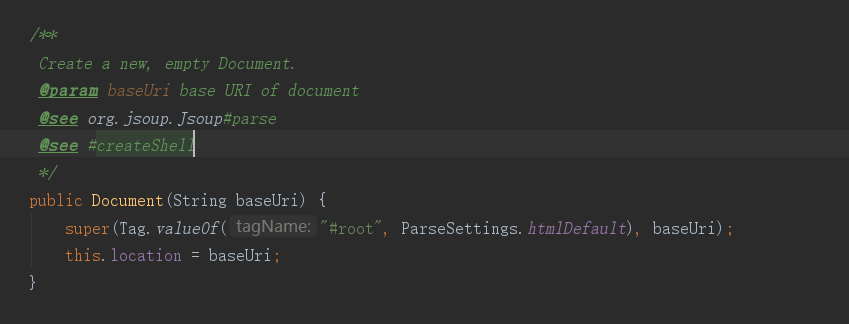
而我们在看源码的注释的时候,不难看出,Jsoup不单单是能解析我们给的这个字符串,还可以是一个URL,也可以是一个文件。
它把我们给他的 HTML 字符串转换成了一个对象,这个对象就是我们上面看到的 Document,然后我们就可以顺利成章的去使用 Document 对象里面的元素了。
上面是解析字符串,那我们看下面这个解析 URL 的存在:
public static void main(String[] args) {
try {
Document doc = Jsoup.connect("https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_f38cf584e9fb4328a3e0d2bb515e1458").get();
String title = doc.title();
System.out.println(title);
}catch (IOException e){
e.printStackTrace();
}
}
大家执行以下的话,就一定能够看到这个 title 到底是什么,而结果是这个样子的:










