Redis在携程内部得到了广泛的使用,根据客户端数据统计,整个携程全部Redis的读写请求在200W QPS/s,其中写请求约10W QPS/S,很多业务甚至会将Redis当成内存数据库使用。
这样,就对Redis多数据中心提出了很大的需求,一是为了提升可用性,解决数据中心DR(Disaster Recovery)问题;二是提升访问性能,每个数据中心可以读取当前数据中心的数据,无需跨机房读数据。在这样的需求下,XPipe应运而生 。
从实现的角度来说,XPipe主要需要解决三个方面的问题,一是数据复制,同时在复制的过程中保证数据的一致性;二是高可用,xpipe本身的高可用和Redis系统的高可用;三是如何在机房异常时,进行DR切换。
下文将会从这三个方面对问题进行详细阐述。最后,将会对测试结果和系统在生产环境运行情况进行说明。
为了方便描述,后面的行文中用DC代表数据中心(Data Center)。
多数据中心首先要解决的是数据复制问题,即数据如何从一个DC传输到另外一个DC,通常有如下方案:
从客户端的角度来解决问题,单个客户端双写两个DC的服务器。初看没有什么问题。但是深入看下去,如果写入一个IDC成功,另外一个IDC失败,那数据可能会不一致,为了保证一致,可能需要先写入一个队列,然后再将队列的数据发送到两个IDC。 如果队列是本地队列,那当前服务器挂掉,数据可能会丢失;如果队列是远程队列,又给整体的方案带来了很大的复杂度。
目前的应用一般都是集群部署,会有多个客户端同时操作。在多个客户端的前提下,又带来了新的问题。比如两个客户端ClientA和ClientB:
ClientA: set key value1ClientB: set key value2
由于两个客户端独立操作,到达服务器的顺序不可控,所以可能会导致两个DC的服务器对于同一个key,value不一致,如下:
Server1: set key value1; set key value2;Server2: set key value2; set key value1;
在Server1,最终值为value2,在Server2,最终值为value1。
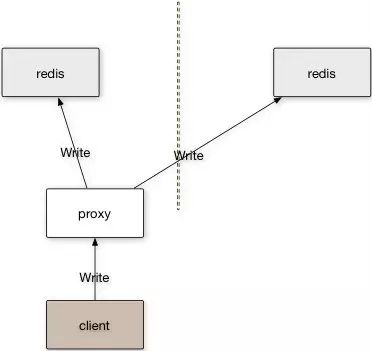
Proxy模式解决了多客户端写可能会导致数据不一致的问题。proxy类似于一个client,和单个client双写的问题类似,需要一个数据队列保数据一致性。
为了提升系统的利用率,单个proxy往往需要代理多个Redis server,如果proxy出问题,会导致大面积的系统故障。这样,就对系统的性能和可用性提出了极大的挑战,带来实现的复杂度。
此外,在特殊的情况下,仍然会可能带来数据的不一致,比如value和时间相关,或者是随机数,两个Redis服务器所在系统的不一致带来了数据的不一致。
考虑到以上情况,为了解决复制问题,我们决定采用伪slave的方案,即实现Redis协议,伪装成为Redis slave,让Redis master推送数据至伪slave。这个伪slave,我们把它称为keeper,如下图所示:
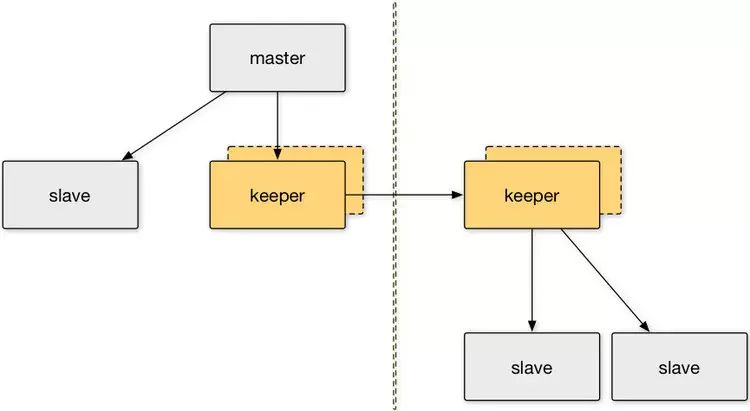
有了keeper之后,多数据中心之间的数据传输,可以通过keeper进行。keeper将Redis日志数据缓存到磁盘,这样,可以缓存大量的日志数据(Redis将数据缓存到内存ring buffer,容量有限),当数据中心之间的网络出现较长时间异常时仍然可以续传日志数据。
Redis协议不可更改,而keeper之间的数据传输协议却可以自定义。这样就可以进行压缩,以提升系统性能,节约传输成本;多个机房之间的数据传输往往需要通过公网进行,这样数据的安全性变得极为重要,keeper之间的数据传输也可以加密,提升安全性。
任何系统都可能会挂掉,如果keeper挂掉,多数据中心之间的数据传输可能会中断,为了解决这个问题,需要保证keeper的高可用。我们的方案中,keeper有主备两个节点,备节点实时从主节点复制数据,当主节点挂掉后,备节点会被提升为主节点,代替主节点进行服务。
提升的操作需要通过第三方节点进行,我们把它称之为MetaServer,主要负责keeper状态的转化以及机房内部元信息的存储。同时MetaServer也要做到高可用:每个MetaServer负责特定的Redis集群,当有MetaServer节点挂掉时,其负责的Redis集群将由其它节点接替;如果整个集群中有新的节点接入,则会自动进行一次负载均衡,将部分集群移交到此新节点。
Redis也可能会挂,Redis本身提供哨兵(Sentinel)机制保证集群的高可用。但是在Redis4.0版本之前,提升新的master后,其它节点连到此节点后都会进行全量同步,全量同步时,slave会处于不可用状态;master将会导出rdb,降低master的可用性;同时由于集群中有大量数据(RDB)传输,将会导致整体系统的不稳定。
截止当前文章书写之时,4.0仍然没有发布release版本,而且携程内部使用的Redis版本为2.8.19,如果升到4.0,版本跨度太大,基于此,我们在Redis3.0.7的版本基础上进行优化,实现了psync2.0协议,实现了增量同步。下面是Redis作者对协议的介绍。
https://gist.github.com/antirez/ae068f95c0d084891305
DR切换分为两种可能,一种是机房真的挂了或者出异常,需要进行切换,另外一种是机房仍然健康,但是由于演练、业务要求等原因仍然需要切换到另外的机房。XPipe处理机房切换的流程如下:
当然了,即使做了检查,也无法绝对保证整个迁移过程肯定能够成功,为此,我们提供回滚和重试功能。回滚功能可以回滚到初始的状态,重试功能可以在DBA人工介入的前提下,修复异常条件,继续进行切换。
根据以上分析,XPipe系统的整体架构如下所示:
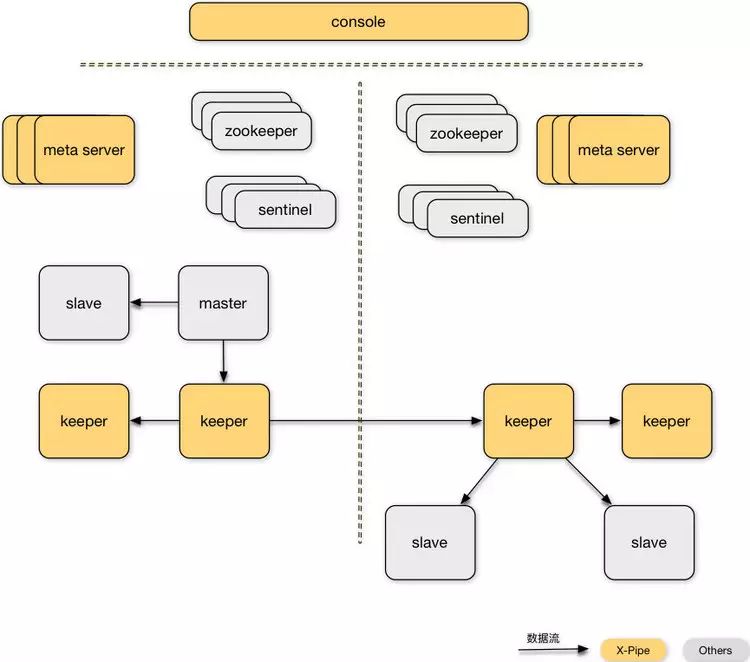
Console用来管理多机房的元信息数据,同时提供用户界面,供用户进行配置和DR切换等操作。Keeper负责缓存Redis操作日志,并对跨机房传输进行压缩、加密等处理。Meta Server管理单机房内的所有keeper状态,并对异常状态进行纠正。
我们关注的重点在于增加keeper后,平均延时的增加。测试方式如下图所示。从client发送数据至master,并且slave通过keyspace notification的方式通知到client,整个测试延时时间为t1+t2+t3。
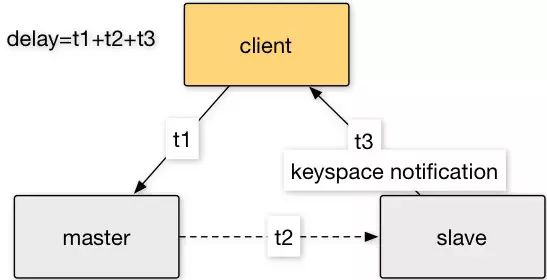
首先我们测试Redis master直接复制到slave的延时,为0.2ms。然后在master和slave之间增加一层keeper,整体延时增加0.1ms,到0.3ms。相较于多个DC之间几毫秒,几十毫秒的延时,增加一层keeper带来的延时是完全没问题的。
在携程生产环境进行了测试,生产环境两个机房之间的ping RTT约为0.61ms,经过跨数据中心的两层keeper后,测试得到的平均延时约为0.8ms,延时99.9线为2ms。
综上所述:XPipe主要解决Redis多数据中心数据同步以及DR切换问题,同时,由于XPipe增强后的Redis版本优化了psync协议,会极大的提升Redis集群的稳定性。
同时,整个系统已经开源,欢迎大家一起参与优化整个系统:
XPipe: https://github.com/ctripcorp/x-pipe
XRedis(在Redis3.0.7版本上进行增强的版本):
https://github.com/ctripcorp/redis
孟文超,携程技术中心框架研发部高级经理。2016年加入携程,目前主要负责Redis多数据中心项目XPipe。此前曾在大众点评工作,任基础架构部门通信团队负责人。
今日荐文
点击下方图片即可阅读

今年,架构师关注的技术点有何不同?从云计算、大数据、微服务、容器,到现在的人工智能,架构师应该怎么做?这里推荐一场会议,为你总结了100+国内外技术专家现阶段的架构实践,8折即将截止,点击“阅读原文”,看看对你有何启发。










