
WWDC 2017向我们传达了这样的一个信号:苹果正在把机器学习带到移动设备上,并且希望开发者们能够轻松地加入到新的平台。
去年,苹果发布了Metal CNN和BNNS框架,用于创建基本的卷积神经网络。今年,Metal增加了很多新的特性,包括一个新的计算机视觉框架,以及Core ML——用于将机器学习模型集成到应用程序里。

在这篇文章里,我会分享并与你们一起体验iOS 11和macOS 10.13上的机器学习。
Core ML
Core ML在WWDC上引起了人们的注意,原因很简单:大多数开发者都希望能够有这样的一个框架,可以把它集成到他们的应用程序里。
Core ML的API很简单,你所要做的就是:
加载一个训练过的模型
生成预测
发布
这看起来确实很简单,不过事实就是如此,你要做的大部分工作就是加载模型和生成预测。
之前,要加载一个训练过的模型非常麻烦。而现在,加载模型只需要两个步骤。
模型包含在.mlmodel文件里,这是一种新的开放文件格式,它描述了模型的层次、输入和输出、类标签,以及一些必需的预处理步骤。它还包含了所有学习过的参数(权重和偏差)。
所有你需要的东西都包含在这个文件里。
只要把mlmodel文件放到项目里,Xcode会自动为它生成一个Swift或Objective-C包装类。
例如,如果你在项目里添加了ResNet50.mlmodel文件,你可以使用
let model = ResNet50()
来初始化这个模型,然后使用如下的代码进行预测:
let pixelBuffer: CVPixelBuffer = /* 你的图像 */
if let prediction = try?model.prediction(image: pixelBuffer) {
print(prediction.classLabel)
}
这样就可以了。你不需要写代码加载模型,或者对它的输出结果进行转换,以便在Swift里使用——Core ML和Xcode为你做掉了这些事情。
Core ML自己会决定该用CPU还是GPU来运行模型,这样可以更好地使用资源。Core ML还能将模型拆分开,部分运行在GPU(需要进行更多计算的任务)上,部分运行在CPU(消耗更多内存的任务)上。
Core ML能够使用CPU对于开发者来说是一件好事,因为这样它们就可以在iOS模拟器上运行(而Metal是不支持这样做的,所以也无法进行单元测试)。
Core ML支持哪些模型?
Core ML可以支持多种不同的模型,ResNet50只是其中一个图像分类器的例子。
这些都可以用于回归和分类。另外,你的模型可以包含典型的机器学习预处理步骤,比如one-hot编码、特征缩放和缺失值插补,等等。
苹果已经提供了一些经过训练的模型供下载,如Inception v3、ResNet50和VGG16,不过你也可以使用Core MLPython工具包将你自己的模型转换成可用的模型。
目前,你可以转换使用Keras、Caffe、scikit-learn、XGBoost和libSVM训练出来的模型。转换工具对版本是有要求的,比如Keras 1.2.2可以,但是2.0版本的不受支持。好在该工具是开源的,所以在未来无疑会支持更多的训练工具。
退一万步讲,你还可以开发自己的转化器。mlmodel文件格式是开放的,使用起来也简单(内部使用了protobuf格式,规范是由苹果发布的)。
局限
Core ML可以让你的模型快速地在你的应用里运行起来。不过,这个简单的API也有一些局限性。
它只支持有监管的机器学习模型,不支持无监管的学习算法或增强型学习。
不能在设备上进行训练。你需要使用离线工具进行训练,然后把训练过的模型转换成Core ML格式。
如果Core ML不支持某种层次类型,那么你就不能使用它。目前为止,使用自己的计算内核是无法对Core ML进行扩展的。TensorFlow可以用于构建一般性的计算图,而mlmodel文件并不像它那么灵活。
Core ML转换工具只支持一部分指定版本的训练工具。如果你在TensorFlow里训练模型,就无法使用这个工具,必须自己编写转换脚本。所以,如果你使用TensorFlow模型处理一些mlmodel不支持的任务,那么就不能把它用在Core ML里。
你无法查看神经网络中间层生成的结果,只能获得最后层生成的预测。
下载模型更新可能会有问题,不过我也不能百分之百肯定。如果你要经常重新训练模型,而且不希望老是在更新模型之后重新发布应用,那么Core ML可能不适合你。
Core ML把选择在CPU上运行还是在GPU上运行的细节隐藏了起来,你要相信它能够为你的应用作出正确的选择。如果你需要让Core ML运行在GPU上,是无法强制它这么做的。
如果你可以接收这些限制,那么Core ML对于你来说会是一个正确的选择。
如果你需要有更多的控制权,那么你需要使用Metal Performance Shader或Accelerate框架自己去实现了。
当然,真正起决定性作用的不是Core ML,而是你的模型。如果你没有合适的模型,Core ML什么也做不了。而设计和训练是机器学习最难的部分……
一个简单的示例应用
我使用Core ML来演示一个简单的应用。示例代码可以在GitHub上找到。
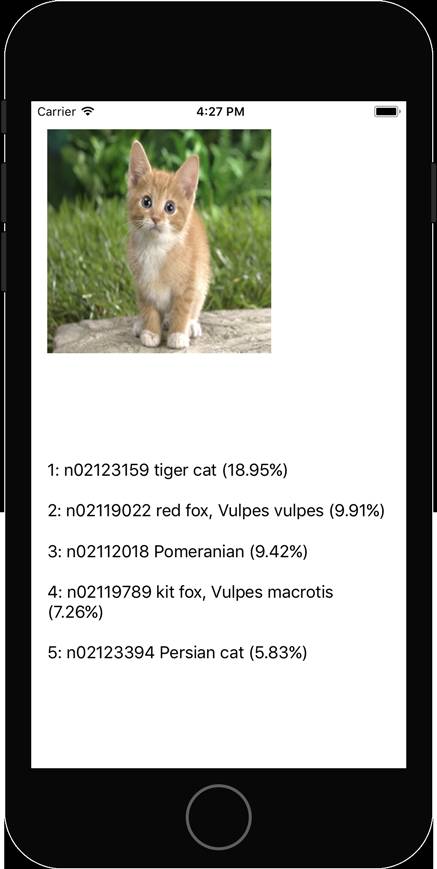
这个示例使用MobileNet来识别一张小猫的照片。
这个模型最初是用Caffe训练的。我花了一些时间才学会如何把它转换成mlmodel文件,不过在获得转换文件后,剩下的事情就很简单了(GitHub仓库里包含了转换脚本)。
这个应用很简单——输出一张静态图片的前5个预测——不过它告诉我们使用Core ML是一件多么简单的事情。你所需要的不过几行代码而已。
不过,我想知道这个过程都发生了什么。我发现,mlmodel文件被编译到一个叫作mlmodelc的目录,并被打包到应用里。这个目录包含了一些不同的文件,有些是二进制文件,有些是JSON文件。你因此可以知道Core ML在应用打包之前是如何组织模型文件的。
MobileNet模型使用了Batch Normalization层,我发现它们也出现在被转化过的mlmodel文件里。不过,在编译过的mlmodelc文件里,这些层被移除了。也就是说Core ML对模型进行了优化。
模型似乎可以进一步优化,因为mlmodelc仍然包含了非严格必需的伸缩层。
当然,目前的iOS版本是beta 1,Core ML在后续还会进一步改进的。也就是说,在将你的模型用在Core ML上之前,对它们进行优化是值得的——比如打包Batch Normalization层——不过你要做好权衡。
你还需要检查其他一些事情:你的模型是否可以运行相同的CPU和GPU上。Core ML会决定让你的模型运行在CPU上(使用Accelerate)或GPU上(使用Metal)。这两种实现的工作原理是不一样的,所以你要分别对它们进行测试!
MobileNet使用了一种叫作“depthwise”的卷积层。初始模型是用Caffe训练的,Caffe通过让普通卷积的groups属性与输出频道数量相等来达到支持depthwise卷积的目的。MobileNet.mlmodel做了同样的事情。这在iOS模拟器上可以正常运行,但在真实设备上会崩溃。
因为模拟器使用了Accelerate框架,而设备使用的是Metal Performance Shaders。Metal编码数据的方式导致了MPSCNNConvolution内核方面的一些限制,你因此无法让groups属性与输出频道数量相等。
我向苹果提交了一个bug,只是想告诉他们:模型可以在模拟器上运行并不代表它也能在设备上运行。所以要确保做好测试工作!
Vision
接下来要讨论新的Vision框架。
你或许从它的名字就可以看出,Vision用于处理计算机视觉任务。你之前可能用过OpenCV,不过现在iOS有了自己的API。

Vision可以用于:
使用Core Image和AVFoundation也能完成这些任务,不过现在这些任务可以在同一个API框架内完成。
如果你的应用需要完成这些任务,你不需要再自己去实现了,也不需要再使用第三方的库,只需要Vision就够了。当然,你也可以结合使用Core Image框架,这样可以处理更多的任务。
你还可以使用Vision来驱动Core ML,也就是说使用计算机视觉技术作为神经网络的预处理步骤。例如,你可以使用Vision检测一个人脸部的位置和大小,然后针对这个位置剪辑视频,并针对这个位置运行神经网络。
事实上,在使用Core ML处理图片或视频时,先用Vision进行预处理是很有必要的。如果只用Core ML,你需要确保输入的图片符合模型格式,而结合使用Vision,可以改变图片的大小等等。它可以为你节省很多时间。
在Core ML中使用Vision看起来是这样的:
//Core ML 模型
let modelCoreML = ResNet50()
//将Core ML与Vision关联起来
VNCoreMLModel(for: modelCoreML.model)
let classificationRequest = VNCoreMLRequest(model: visionModel) {
request, error in
if let observations = request.results as?[VNClassificationObservation] {
//处理预测
}
}
let handler = VNImageRequestHandler(cgImage: yourImage)
try? handler.perform([classificationRequest])
要注意,VNImageRequestHandler接收一个请求对像数组作为参数,你可以将多个Vision任务链接在一起:
try? handler.perform([faceDetectionRequest, classificationRequest])
Vision让计算机视觉任务变得更加容易,更有趣的是,你可以将这些任务的输出放进Core ML的模型里。
Metal Performance Shaders
我想讨论的最后一个话题是Metal,苹果的GPU API。
我今年的很多工作涉及到使用Metal Performance Shaders(MPS)构建神经网络,并进行性能优化。iOS 10只为卷积网络提供了一些基本的支持,所以经常要自己实现一些功能来填充这些空白。
iOS 11在这方面做出了很多改进,更让人惊喜的是,它提供了用于创建图形的API。

MPS的主要变更包括:
循环神经网络。我们现在可以创建RNN、LSTM、GRU和MGU层。它们可以应用在MPSImage对象序列和MPSMatrix对象序列上。其他MPS层只处理图像,所以当你要处理文本或其他非图像数据时就不是很方便。
更多的数据类型。之前的权重为32位的浮点数,而现在可以支持16位的浮点数和8位整数,甚至是二进制。卷积和完全连接的层可以使用二进制权重和二进制输入数据。
更多的层。我们之前要设法应付固定卷积以及max池化和average池化,不过在iOS 11里,MPS支持膨胀卷积、次像素卷积、转置卷积、超采样和重取样、L2-norm池化、膨胀max池化,以及一些新的激活函数。MPS并不具备所有的Keras和Caffe层类型,不过它们之间的差距正在逐步缩小。
更方便。MPSImage的用法有点奇怪,因为Metal按照切片来组织数据。不过现在,MPSImage提供了用于读取和写入数据的方法,这样就不会经常打断你的思路了。
MPSCNNConvolutionDescriptor也提供了一个便利的方法,你可以在层上设置 batch normalization参数。
性能改进。内核的速度更快了。
图形API。这是我最关心的重大好消息。手动创建层和图形非常繁琐,而现在你可以描述一个图,就像在Keras里那样。MPS会自动确定图像的大小、如何进行填充、如何设置偏移量,等等。通过后台的层熔化,可以对图进行优化。
MPS内核现在似乎都可以通过NSSecureCoding进行序列化,也就是说,你可以把图保存到文件里,以后还能从文件中恢复。图的推理只要调用一个方法就可以了。尽管还不如Core ML那么简单,但已经比之前少做很多工作了。
结论:Metal Performance Shaders在iOS 11中变得更加强大,不过大部分开发者还是要关注Core ML(底层使用了MPS)。
是不是都是好消息?
苹果为开发者带来了这些新工具算得上是利好消息,不过苹果的API总是带有一些问题:
这意味着苹果的API总是落在其他工具后面。如果Keras增加了新的层类型,那么在苹果更新他们的框架和操作系统之前,你是无法在Core ML里使用它们的。
如果有些API无法按照你的预期工作,你也无法修改它们——你只能想一些临时解决方案,或者等待下一个操作系统版本的发布。
作者 Matthijs Hollemans ,译者 薛命灯

媒体合作请联系:
邮箱:[email protected]










