生信草堂
将会与更多的优秀微信公众号合作,把最优秀的微信推文呈现给大家,希望可以帮助读者更多的了解生信技术,培养和提高读者的生信分析能力!
号外,号外,号外
你想和生信分析大神做好朋友么?
你想认识更多爱好生信分析的小伙伴么?
你想让自己的生信分析走上快车道么?
那就赶快加入我们的生信交流微信群吧!
正确加入我们的模式是:
添加我们的微信bioinformatics88为好友
标注“
加入生信草堂交流群
”
在群里请大家注明自己
本名,单位,研究领域
便于小编管理
生信大讲堂
微信公众平台,作为浙江大学农业与生物技术学院作物所研究生第七党支部“生信大讲堂”生物信息系列讲座的重要线上平台,结合学科特色,坚持以“四讲四有”中“讲奉献有作为”作为活动核心价值观,为广大科研工作者提供了学习生物信息学相关学科知识的资源及平台。
~戳
这里
生信大讲堂
公众号原文,请多关注哦~
R语言是面向对象的。面向对象的理论一两句话说不清楚,但对于数据至少应该了解三个:
1、R能处理的东西(包括数据)都称为object。这个英文单词的意思原本很清楚,就是物体、物件的意思,但被计算机专家们翻译成“对象”以后就很玄乎了。
2、 物(object)以类聚。一个object都应该能找到它所归属的某个类(class)。“类”是抽象的概念,一个类至少有一个特征是这类数据所共有 的。根据应用需求、目的等不同可以定义不同的类。比如做生物信息的可以定义出DNA类、RNA类,为了高效处理这类数据,定义这些类是非常必要的。所以R 里面有很多的“类”。
3、类可以继承产生儿孙类。
我们不可能也没必要去了解所有的“类”,但R语言定义的一些基本数据类得了解,而且得较详细地了解。这包括向量、因子、矩阵、列表、数据框和一些特殊值数据。
我们通常接触的数据主要是数字、字符和逻辑(真和假,是或不是)类型的。数据有一个个的,也有一串串一批批的。在R里面,最基本的数据类是向量,即一串有序数据;但vector是虚拟类,
没有父类型,它包含了在其他语言里面常说的基本数据类型如整型、字符型和逻辑型等:
> getClass("vector")
Virtual Class "vector" [package "methods"]
No Slots, prototype of class "logical"
Known Subclasses: #已知子类
Class "logical", directly
Class "numeric", directly
Class "character", directly
Class "complex", directly
Class "integer", directly
Class "raw", directly
Class "expression", directly
Class "list", directly
Class "structure", directly, with explicit coerce
Class "array", by class "structure", distance 2, with explicit coerce
Class "matrix", by class "array", distance 3, with explicit coerce
Class "signature", by class "character", distance 2
Class "className", by class "character", distance 2
Class "ObjectsWithPackage", by class "character", distance 2
Class "mts", by class "matrix", distance 4, with explicit coerce
Class "ordered", by class "factor", distance 3
Class "namedList", by class "list", distance 2
Class "listOfMethods", by class "namedList", distance 3
R语言处理数据的最基本单位是向量,而不是原子数据。所以向量又称为原子向量(atomic vector),R语言的数据单位里面它最小(也最大,没有谁是它的父母)。但由于vector是虚拟类,不管用什么方式你都不可能获得类型名称叫“vector”的对象,只能获得它的直接子类的对象。下面的x是一个矩阵,虽然我们用as.vector函数进行转换,但获得对象的类名称是integer而不是vector:
> x
> class(x)
[1] "matrix"
> class(as.vector(x))
[1] "integer"
一个向量可以是一串数字(n个数字,向量长度为n),也可以是1个数字(向量长度为1):
> x=1:40
> x
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
[25] 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
> x=1
> x
[1] 1
等于号可以用于向量赋值,但符号“
> x c(1,2,3)
> x
[1] 1 2 3
> y c("赵匡胤", "钱学森", "孙思邈")
> y
[1] "赵匡胤" "钱学森" "孙思邈"
c(
) 是R的一个函数,表示将括号里面的内容连接起来成为一个向量。R提供了一些产生特殊向量的函数,如seq(
)和rep(
),具体用法直接在R里面先输 入问号(?)和函数名去查询。vector是虚拟类,本身不指定数据的存储类型,但赋值以后就马上会有数字型(numeric)、字符型 (character)、逻辑型(logical)等实际类别,比如上面的变量x和y,用class(
)函数获得的类型分别是数值型和字符型:
> class(x)
[1] "numeric"
> class(y)
[1] "character"
一个向量只属于一种类型,如果改变了一个元素的值可能会改变该向量的类型:
> x seq(10)
> x
[1] 1 2 3 4 5 6 7 8 9 10
> class(x)
[1] "integer"
> x[2] "Adam"
> x
[1] "1" "Adam" "3" "4" "5" "6" "7" "8" "9" "10"
> class(x)
[1] "character"
向量元素的引用/提取用下标法如
x[2],R语言的下标从1开始编号(而不是0)。
R定义了一类非常特殊的数据类型:因子。比如我们的实验获得了10个数据,前5个数据来自对照样品CK,其余属于处理样品TR,R语言中可以用下面方法标识这10个数据的样品属性:
> sample rep(c("CK","TR"), each=5)
>samplefactor(sample)
>sample
[1] CK CK CK CK CK TR TR TR TR TR
Levels: CK TR
因子的种类称为水平(level)。上面的样品sample因子有两个水平:CK和TR。因子类数据很特殊:
> getClass("factor")
Class "factor" [package "methods"]
Slots:
Name: .Data levels .S3Class
Class: integer character character
Extends:
Class "integer", from data part
Class "oldClass", directly
Class "numeric", by class "integer", distance 2
Class "vector", by class "integer", distance 2
Known Subclasses: "ordered"
使用因子类数据是因为R是针对统计应用的语言。使用因子以后,数据的统计会完全不同。比如上面的两个样品10个测定数值如果是:
> value rnorm(10)
> value
[1] 1.44368380 -1.99417898 0.60279037 0.75186610 1.08372729 -0.16189030
[7] -0.05617801 1.03601538 -0.87932814 -0.32429184
求样品的平均值就可以这么做:
> tapply(value, sample, mean)
CK TR
0.37757771 -0.07713458
gl(
)函数也可以方便地产生因子:
> sample gl(2, 5, labels = c("CK", "TR"))
> sample
[1] CK CK CK CK CK TR TR TR TR TR
Levels: CK TR
矩阵的继承关系比较复杂,它和数组(array)的关系既是父亲又是儿子,还是孙子:
> getClass("matrix")
Class "matrix" [package "methods"]
No Slots, prototype of class "matrix"
Extends:
Class "array", directly
Class "structure", by class "array", distance 2
Class "vector", by class "array", distance 3, with explicit coerce
Known Subclasses:
Class "array", directly, with explicit test and coerce
Class "mts", directly
如果你愿意,也可以把矩阵称为数组,但事实上它们是不同的类。生物类数据以二维数组/矩阵居多。
向量数据可以转成矩阵,下面代码将10个元素的x转成2行5列的矩阵:
> x 1:10
> dim(x) c(2,5)
> x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> dim(x)
[1] 2 5
dim(
)是一个函数,它获取或设置数据的维度。注意x数据的行列排列顺序:先列后行。但是矩阵内数据的下标读取方式是先行后列。x[2,
1]是第2行第1列的值,x[2,
]表示第2行的所有数据,x[
,2]表示第2列的所有数据。
> x[2,1]
[1] 2
> x[2,]
[1] 2 4 6 8 10
> x[ ,2]
[1] 3 4
把1个向量转成矩阵还可以使用matrix(
)函数,参数nrow设置行数,ncol设置列数:
> matrix(1:10, nrow=2)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
几个长度相同的向量也可以合并到一个矩阵,cbind(
)函数将每个向量当成一列(按列)合并,rbind(
)按行合并:
> x 3:6
> y 4:7
> z 1:4
> cbind(x,y,z)
x y z
[1,] 3 4 1
[2,] 4 5 2
[3,] 5 6 3
[4,] 6 7 4
> rbind(x,y,z)
[,1] [,2] [,3] [,4]
x 3 4 5 6
y 4 5 6 7
z 1 2 3 4
不同向量的数据类型要相同,否则转换成矩阵后数据类型会变样。下面代码将height内的数字全都转成了字符类型,这可能不是你想要的结果:
> name c("赵匡胤", "钱学森", "孙思邈")
> height c(172, 175, 168)
> info rbind(name,height)
> info
[,1] [,2] [,3]
name "赵匡胤" "钱学森" "孙思邈"
height "172" "175" "168"
> class(info)
[1] "matrix"
身高是数值,但跟姓名混合组成矩阵后就变成字符型了(输出结果中用双引号引起来)。
矩阵元素可通过下标引用,多维矩阵可以只用一个下标,请注意info[3]获得的数据:
> info[1,]
[1] "赵匡胤" "钱学森" "孙思邈"
> info[,1]
name height
"赵匡胤" "172"
> info[3]
[1] "钱学森"
列表由向量直接派生而来,nameList是它的子类,listOfMethods是它家孙子:
> getClass("list")
Class "list" [package "methods"]
No Slots, prototype of class "list"
Extends: "vector"
Known Subclasses:
Class "namedList", from data part
Class "listOfMethods", by class "namedList", distance 2
那么列表是什么样子的呢?看这:
> gene list(agi="AT1G00010", gene.mode=c("AT1G00010.1", "AT1G00010.2", "AT1G00010.3"), expression=matrix(1:10, ncol=2))
> gene
$agi
[1] "AT1G00010"
$gene.mode
[1] "AT1G00010.1" "AT1G00010.2" "AT1G00010.3"
$expression
[,1] [,2]
[1,] 1 6
[2,] 2 7
[3,] 3 8
[4,] 4 9
[5,] 5 10
列表可以组合不同的数据类型,甚至可以是其他列表,各组成数据的类、长度、维数都可以不一样。
R 语言中,一个矩阵内的数据类型要求都要相同,这对生物类数据不大适用,因为我们的数据经常是既有数字又有字符类标记。R语言提供了另外一种更灵活的数据类 型:数据框。可以将几个不同类型但长度相同的向量用data.frame(
)函数合并到一个数据框,它的模样就像二维数组。但要注意:合并的几个向量长 度必需一致。
> name c("赵匡胤", "钱学森", "孙思邈")
> height c(172, 175, 168)
> info data.frame(name,height)
> info
name height
1 赵匡胤 172
2 钱学森 175
3 孙思邈 168
用as.data.frame(
)函数可以将二维矩阵转成数据框,但鉴于矩阵的数据类型限制,在生物类数据中用得少一些。
虽然数据框的外观和二维矩阵差不多,但它却不是从矩阵而是从列表派生来的,它是数据(.data)是列表数据,列名称(names)就是列表中各项的名称,另外还有行名称(row.names):
> getClass("data.frame")
Class "data.frame" [package "methods"]
Slots:
Name: .Data names row.names
Class: list character data.frameRowLabels
Name: .S3Class
Class: character
Extends:
Class "list", from data part
Class "oldClass", directly
Class "data.frameOrNULL", directly
Class "vector", by class "list", distance 2
数据框的每列是一个向量,称为列向量。列向量只有两种类型,要么是数字型,要么是因子型。从文件读取或其他类型数据转换成数据框的数据,如果不是数值型,会被强制转换成因子型。有时候数值型(尤其是整型)向量也会被转成因子,这点应该注意。
数据框可以用数字下标取数据,也可以用列名称下标取数据,但是两种方式所获数据的类型是不一样的,按列名称下标方式取得的数据仍然是数据框:
> info[,1]
[1] 赵匡胤 钱学森 孙思邈
Levels: 钱学森 孙思邈 赵匡胤
> class(info[,1])
[1] "factor"
> info["name"]
name
1 赵匡胤
2 钱学森
3 孙思邈
> class(info["name"])
[1] "data.frame"
为什么要注意这个区别?因为看起来像是同样的数据,在一些对类型要求很严格的操作(比如作图)中得到完全不一样的结果。数据框还有一种数据提取方式,得到因子或向量:
> class(info$name)
[1] "factor"
> class(info$height)
[1] "numeric"
为确保所有数据都能被正确识别、计算或统计等,R定义了一些特殊值数据:
NULL:空数据
NA:表示无数据
NaN:表示非数字
inf:数字除以0得到的值
判断一个object
(x)是不是属于这些类型有相应的函数:
is.null(x)
is.na(x)
is.nan(x)
is.infinite(x)
R语言的对象“类”很多,虽然我们不可能一一去详细学习,但接触到一类新数据时我们需要了解一些基本信息才能进行进一步的操作。R提供了一些非常有用的方法(函数)。
getClass(
)函数我们前面已经见过了,它的参数是表示类的字符串。
class(
)可获取一个数据对象所属的类,它的参数是对象名称。
str(
)可获取数据对象的结构组成,这很有用。
mode(
)和storage.mode(
)可获取对象的存储模式。
typeof(
)获取数据的类型或存储模式。
要了解这些函数能干什么可以在R里面查询,方法是用问号加上面的函数名就可以,如:?str
转载自http://blog.sina.com.cn/s/blog_69ffa1f90101sies.html
条形图可以说是我们最常用的数据可视化方法了,通常用于展示不同分类条件下(在x轴上)某个数值型变量的取值(y轴上)。绘制条形图时需要特别注意的一个细节是条形图的条形高度有时表示的是数据集中变量的频数,有时表示的则是变量本身。本文将会介绍这两类条形图的绘图技巧。
使用
ggplot()
函数与
geom_bar(stat="identity")
绘制条形图,我们将利用
gcookbook
包中的数据进行绘制。
#没安装包要先安装包gcookbook、ggplot2以及dplyr
library(gcookbook)#加载gcookbook以使用其包含的数据
library(ggplot2)#用于可视化library(dplyr)#用于数据处理
这里我们调用
gcookbook
里的数据集绘制条形图
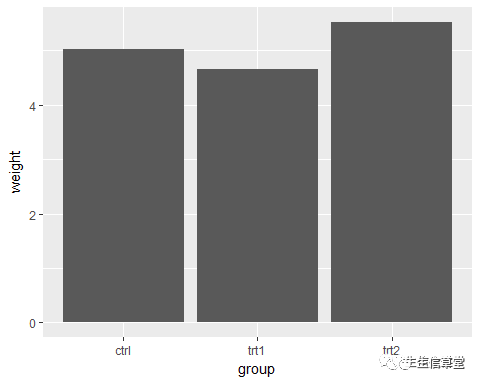
head(pg_mean)#查看数据集
## group weigh
t
## 1 ctrl 5.032
## 2 trt1 4.661
## 3 trt2 5.526
ggplot(data=pg_mean, aes(x=group, y=weight))+#将group、weight分别赋值给x、y轴 。R语言有一个coord_flip()函数可以将横向坐标转换:把x轴和y轴互换。因此如果想生成你说的条形图的话只需在代码后面加上coord_flip()就行了
geom_bar(stat = "identity")#必须将geom_bar()中的stat(统计变换)参数设置为”identity“,即对原始数据集不作任何统计变换,而该参数的默认值为'count',即观测数量。
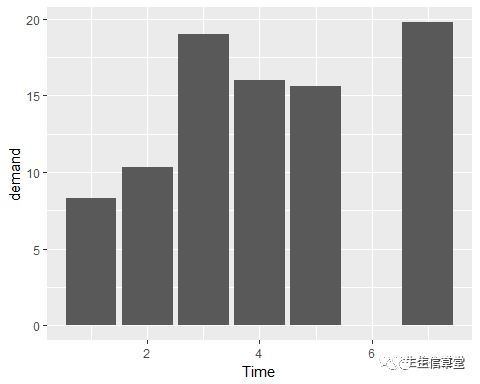
当x是连续型(数值型)变量时,条形图略有不同,需要略作调整,具体如下:
str(BOD)#查看BOD数据集可以发现Time变量是数值型
## 'data.frame': 6 obs. of 2 variables:
## $ Time : num 1 2 3 4 5 7
## $ demand: num 8.3 10.3 19 16 15.6 19.8
## - attr(*, "reference")= chr "A1.4, p. 270"
ggplot(data=BOD, aes(x=Time, y=demand))+ geom_bar(stat = "identity")#此时Time是数值型
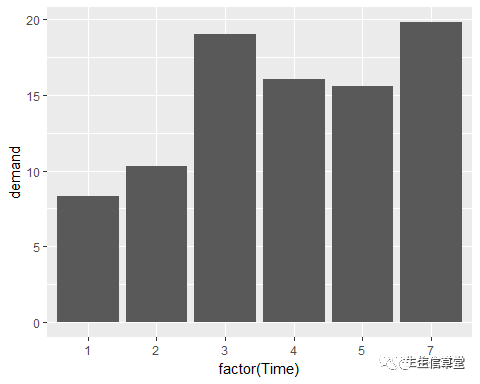
ggplot(data=BOD, aes(x=factor(Time), y=demand))+ geom_bar(stat = "identity")#将Time转换为因子型(分类/离散变量),仔细比较两图
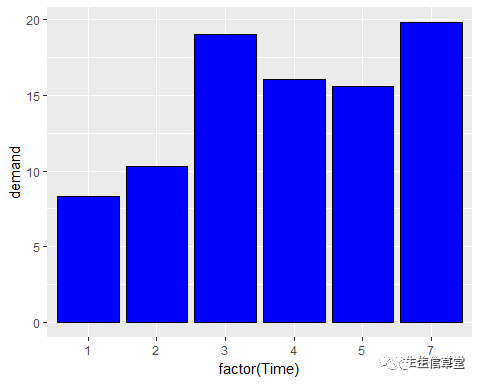
条形图颜色有两部分:填充颜色(
fill
)以及边框颜色(
color
),因此调整条形图颜色要调两部分,具体如下:
ggplot(data=BOD, aes(x=factor(Time), y=demand))+ geom_bar(stat = "identity", fill="blue", color="black")#可以自己设定喜好的颜色
方法:将分类变量映射到
fill
参数,运用
geom_bar(position="dodge")
绘制,具体如下:
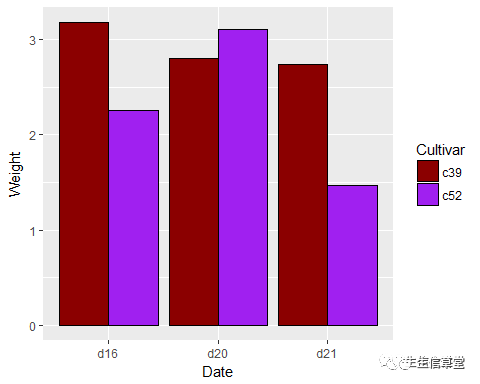
head(cabbage_exp)#查看数据,发现含有两个分类变量:Cultivar和Date以及一个连续型变量Weight
## Cultivar Date Weight sd n se
##1 c39 d16 3.18 0.9566144 10 0.30250803
##2 c39 d20 2.80 0.2788867 10 0.08819171
##3 c39 d21 2.74 0.9834181 10 0.31098410
##4 c52 d16 2.26 0.4452215 10 0.14079141
##5 c52 d20 3.11 0.7908505 10 0.25008887
##6 c52 d21 1.47 0.2110819 10 0.06674995
ggplot(data=cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar))+#分别将Date与Cultivar映射给x和fill
geom_bar(stat = "identity", position = "dodge")#position = "dodge"表示条形图分开不重叠(簇形图),默认的为stack(堆叠式),还有百分比堆叠式(fill)
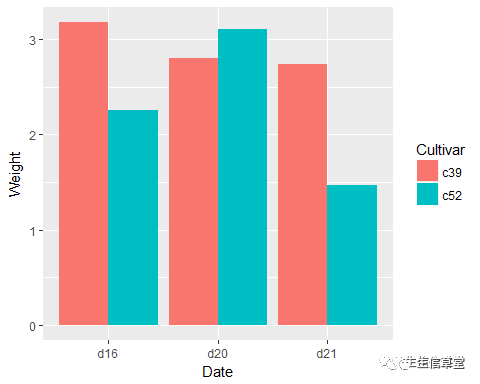
ggplot(data=cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar))+ geom_bar(stat = "identity", position = "stack")#堆叠式
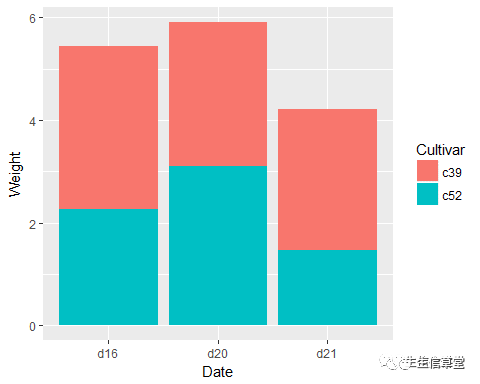
ggplot(data=cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar))+ geom_bar(stat = "identity", position = "fill")#百分比堆叠式
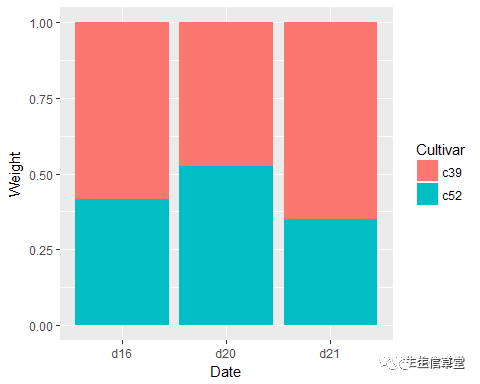
ggplot(data=cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar))+ geom_bar(stat = "identity", position = "dodge", color="black")+ scale_fill_brewer(palette = "Set1")#Set1为调色板,后期将会专门讲解Color设置
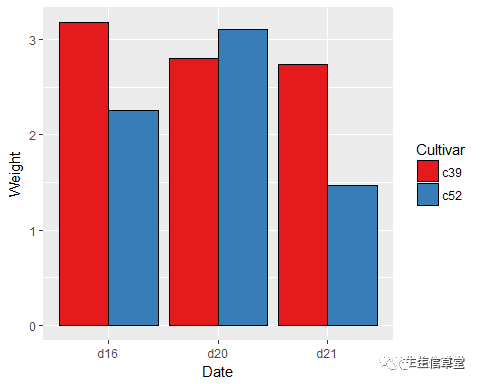
ggplot(data=
cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar))+ geom_bar(stat = "identity", position = "dodge", color="black")+ scale_fill_manual(values = c("darkred", "purple"))#自设置颜色
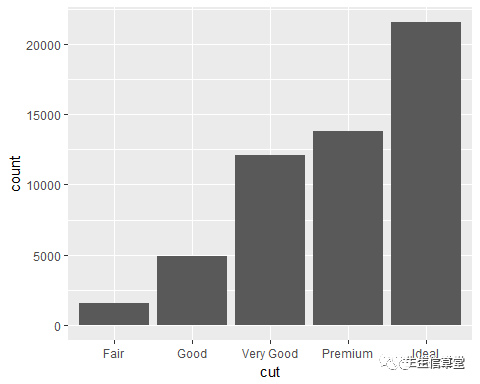
head(diamonds,n=10)#查看前10行数据
###A tibble: 10 × 10
## carat cut color clarity depth table price x y z
##
##1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
##2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
##3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
##4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
##5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
##6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
##7 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47
##8 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
##9 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
##10 0.23 Very Good H VS1 59.4 61 338 4.00 4.05 2.39
ggplot(diamonds, aes(x=cut))+#此时不要映射任何变量到y geom_bar()#等价于geom_bar(stat="bin")
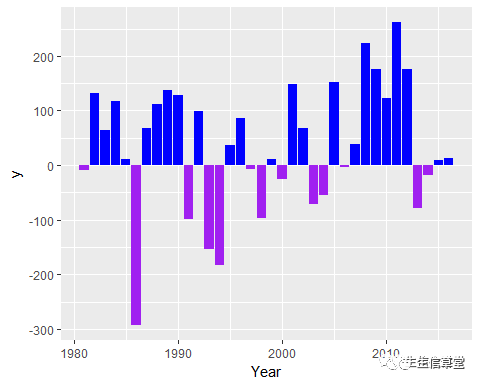
#首先先创建一下数据集
set.seed(1111)#此命令保证数据结果可以重现在任何电脑上
x 1980+1:36#赋值x
y round(100*rnorm(36))#赋值y
mydata data.frame(x=x, y=y)#创建数据集mydata
mydata % #%>%管道操作,结合dplyr为数据处理神器
mutate(judge=ifelse(y>=0,"Yes", "No"))#创建judge变量,将y正负分类
head(mydata)#查看数据
## 1 1981 -9 No
## 2 1982 132 Yes
## 3 1983 64 Yes
## 4 1984 117 Yes
## 5 1985 12 Yes
## 6 1986 -293 No
#接下来绘制条形图
ggplot(data=mydata, aes(x=x, y=y, fill=judge))+ geom_bar(stat = "identity",position = "identity")+#这里position="identity"可以避免系统对负值绘制条形图发出警告信息
scale_fill_manual(values = c("purple", "blue"), guide=FALSE)+xlab("Year")#guide=FALSE表示不要图例,x轴标题为Year
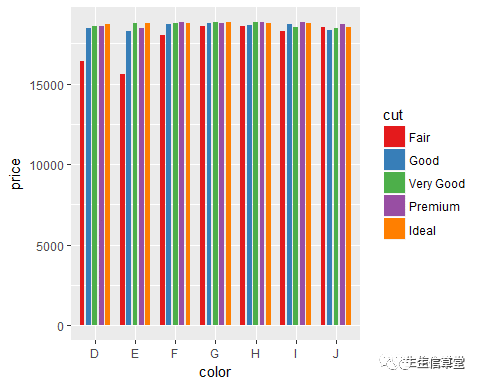
head(diamonds)
### A tibble: 6 × 10
## carat cut color clarity depth table price x y z
##
##1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
##2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
##3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
##4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
##5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
##6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
ggplot(data=diamonds, aes(x=color, y=price, fill=cut))+ geom_bar(stat = "identity", width = 0.6, position = position_dodge(0.8))+#调整条形宽度以及条形距离
scale_fill_brewer(palette = "Set1")
使用geom_text()为条形图添加标签,需要分别指定一个变量映射给x、y以及标签(label),vjust和hjust分别调整标签的竖直和水平位置。
#标签在条形图顶端下方
ggplot(data=cabbage_exp, aes(x=interaction(Date, Cultivar), y=Weight))+ geom_bar(stat = "identity")+ geom_text(aes(label=Weight), vjust=1.5, color="white")
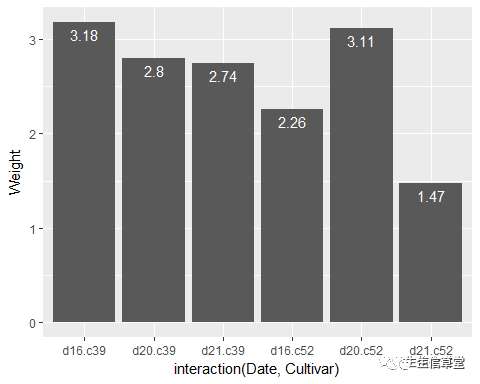
#标签在条形图顶端上方
ggplot(data=cabbage_exp, aes(x=interaction(Date, Cultivar), y=Weight))+ geom_bar(stat = "identity")+ geom_text(aes(label=Weight), vjust=-0.3, color="red")#可以通过color、size等自行调整标签属性
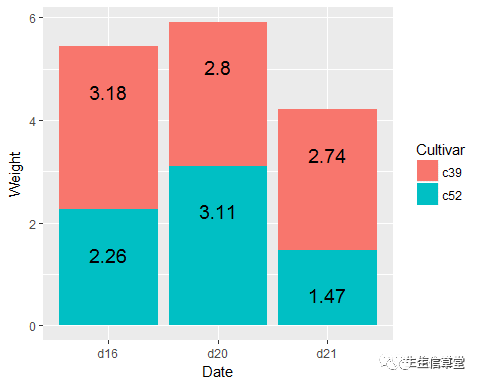
#堆叠图也一样
ggplot(data=cabbage_exp, aes(x=Date, y=Weight, fill=Cultivar))+ geom_bar(stat="identity", position = "stack")+ geom_text(aes(label=Weight), size=5, color="black", vjust=3.5, hjust=0.5, position = position_stack())#这里的position要与geom_bar()里面的保持一致,各种参数多调整才能效果最佳
 长按关注生信草堂
长按关注生信草堂





