

作者 hooly
本文转自36大数据,转载需授权
什么是数据分析?
数据分析是指用适当的统计分析对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。
数据分析的目的是什么?
数据分析的目的是把隐没在一大批看来杂乱无章的数据中的信息集中、萃取和提炼出来,以找出所研究对象的内在规律。
在实用中,数据分析可帮助人们作出判断,以便采取适当行动。数据分析是组织有目的地收集数据、分析数据,使之成为信息的过程。在产品的整个寿命周期,包括从市场调研到售后服务和最终处置的各个过程都需要适当运用数据分析过程,以提升有效性。
在企业里面,数据分析可以帮助我们掌握企业的运营状况,商品的出售情况,用户的特征、产品的粘性、等等。
数据分析的步骤?
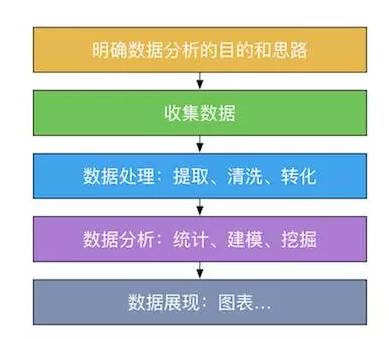
1.首先明确分析的思路和目的:
数据分析一定的带着某种业务目的的。它可能是要追踪一个新产品上线之后的用户使用情况;也可能是观察用户在某段时间的留存情况,还有可能是运营某种优惠券是否有效。
带着一定的目的,确定要从哪几个角度进行分析。然后找到能够说明目的的指标。
比如想要验证运营最近的一批优惠券是否有效。我们可以从优惠券的领取情况和优惠券的使用情况两个方面分析,而优惠券的领取情况的指标可以细化为领取率;使用情况可细化为:使用率、客单价等。
2.数据的收集:
在确定了此次数据分析的核心指标后,就要针对数据指标做数据收集。
有些企业的数据准备非常充分,数据仓库、数据集市等早早就建设好。有一些企业在数据分析上比较落后,那就需要我们自己做前期大量的数据收集工作。
比如使用一些自己公司的或者第三方的数据分析工具进行埋点,拿到日志。或者使用数据库中的现有数据,比如订单数据、基础的用户信息等等。
3.数据处理:
数据提取出来之后,要剔除脏数据(清洗),然后数据转化。在进行最基本的数据汇总、聚合之后,我们就可以拿到比较简单的字段相对丰富的数据宽表。
4.数据分析:
数据分析是用适当的分析方法及工具,对处理过的数据进行分析,提取有价值的信息,形成有效结论的过程。
一般公司所需要观察的数据大致分为如下几类:
随着数据的重要性的凸显,越来越多的公司已经认识到数据对于公司的经营是十分重要的。
所以绝大部分企业都有专门的BI部门进行初步的数据加工、分析,以周报表的形式汇总给管理层做为日常数据所需以及企业决策使用。
在这里主要介绍两个简单的数据分析模型:
AARRR模型:
Acquisition(获取)、Activation(活跃)、Retention(留存)、Revenue(收益)、Refer(传播)
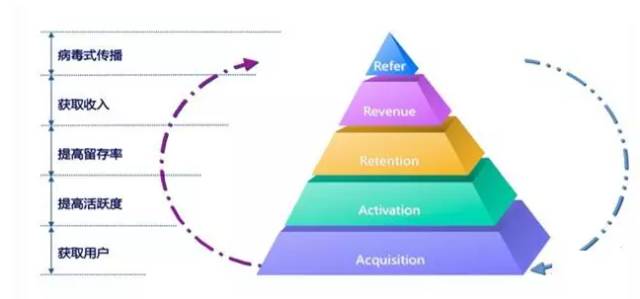
获取用户(Acquisition)
如何获取用户?线上通过网站通过SEO,SEM,app通过市场首发、ASO等方式获取。还有运营活动的H5页面,自媒体等方式。线下通过地推和传单进行获取用户。
提高活跃度(Activation)
来了用户后,通过运营价格优惠、编辑内容等方式进行提高活跃度。把内容做多,商品做多,价格做到优惠,但需要控制在成本至上的有生长空间。这样的用户是最有价值进行活跃。
产品策略上,除了提供运营模块和内容深化。进行产品会员激励机制成长体制进行活跃用户。不仅商品优惠的,VIP等标示的ICON,对于长业务流程,进行流程激励体制,产品策略更具多元化。
提高留存率(Retention)
提高活跃度的,有了忠实的用户,就开始慢慢沉淀下来了。运营上,采用内容,相互留言等社区用户共建UCG,摆脱初期的PCG模式。电商通过商品质量,O2O通过优质服务提高留存。这些都是业务层面的提高留存。
产品模式上,通过会员机制的签到和奖励的机制去提高留存。包括app推送和短信激活方式都是激活用户,提高留存的产品方式。
通过日留存率、周留存率、月留存率等指标监控应用的用户流失情况,并采取相应的手段在用户流失之前,激励这些用户继续使用应用。
获取收入(Revenue)
获取收入其实是应用运营最核心的一块。即使是免费应用,也应该有其盈利的模式。
收入来源主要有三种:付费应用、应用内付费、以及广告。付费应用在国内的接受程度很低,包括Google Play Store在中国也只推免费应用。在国内,广告是大部分开发者的收入来源,而应用内付费目前在游戏行业应用比较多。
前面所提的提高活跃度、提高留存率,对获取收入来说,是必需的基础。用户基数大了,收入才有可能上量。
自传播(Refer)
以前的运营模型到第四个层次就结束了,但是社交网络的兴起,使得运营增加了一个方面,就是基于社交网络的病毒式传播,这已经成为获取用户的一个新途径。这个方式的成本很低,而且效果有可能非常好;唯一的前提是产品自身要足够好,有很好的口碑。
从自传播到再次获取新用户,应用运营形成了一个螺旋式上升的轨道。而那些优秀的应用就很好地利用了这个轨道,不断扩大自己的用户群体。
漏斗模型:
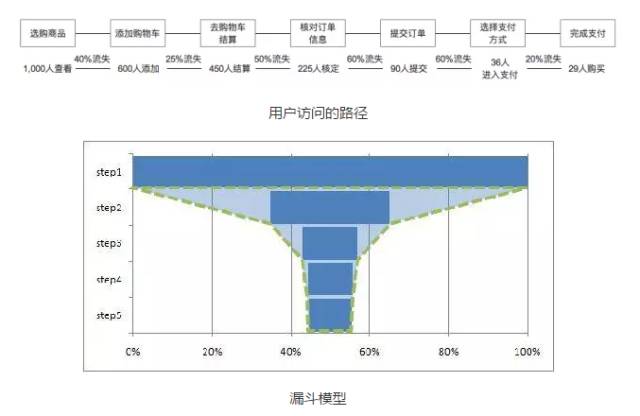
漏斗模型广泛应用于流量监控、产品目标转化等日常数据运营工作中。之所以称为漏斗,就是因为用户(或者流量)集中从某个功能点进入(这是可以根据业务需求来自行设定的),可能会通过产品本身设定的流程完成操作。
按照流程操作的用户进行各个转化层级上的监控,寻找每个层级的可优化点;对没有按照流程操作的用户绘制他们的转化路径,找到可提升用户体验,缩短路径的空间。
运用漏斗模型比较典型的案例就是电商网站的转化,用户在选购商品的时候必然会按照预先设计好的购买流程进行下单,最终完成支付。
需要注意的是:单一的漏斗模型对于分析来说没有任何意义,我们不能单从一个漏斗模型中评价网站某个关键流程中各步骤的转化率的好坏,所以必须通过趋势、比较和细分的方法对流程中各步骤的转化率进行分析:
趋势(Trend):从时间轴的变化情况进行分析,适用于对某一流程或其中某个步骤进行改进或优化的效果监控;
比较(Compare):通过比较类似产品或服务间购买或使用流程的转化率,发现某些产品或应用中存在的问题;
细分(Segment):细分来源或不同的客户类型在转化率上的表现,发现一些高质量的来源或客户,通常用于分析网站的广告或推广的效果及ROI。
5.数据展现:
数据可视化-基本的图表
数据可视化是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
图表是”数据可视化”的常用手段,其中又以基本图表——柱状图、折线图、饼图等等——最为常用。
有人觉得,基本图表太简单、太原始,不高端,不大气,因此追求更复杂的图表。但是,越简单的图表,越容易理解,而快速易懂地理解数据,不正是”数据可视化”的最重要目的和最高追求吗?
所以,请不要小看这些基本图表。因为用户最熟悉它们,所以只要是适用的场合,就应该考虑优先使用。
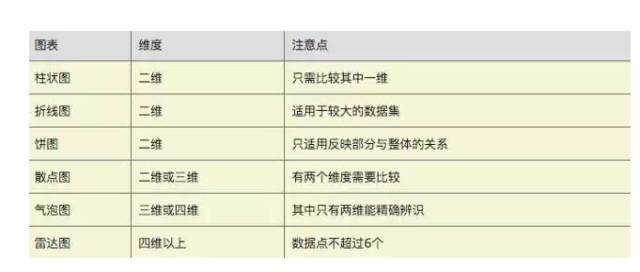
5.1柱状图(Bar Chart)
柱状图是最常见的图表,也最容易解读。
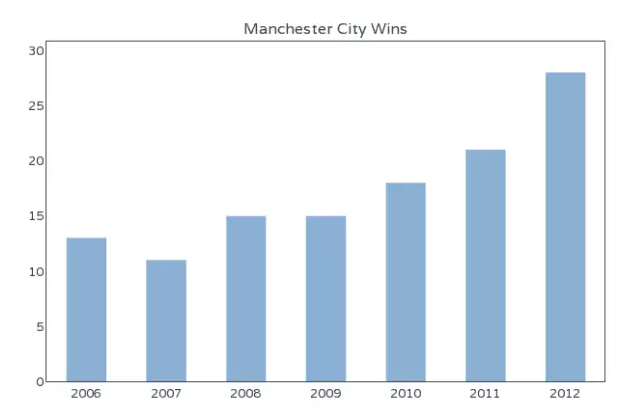
它的适用场合是二维数据集(每个数据点包括两个值x和y),但只有一个维度需要比较。年销售额就是二维数据,”年份”和”销售额”就是它的两个维度,但只需要比较”销售额”这一个维度。
柱状图利用柱子的高度,反映数据的差异。肉眼对高度差异很敏感,辨识效果非常好。柱状图的局限在于只适用中小规模的数据集。
通常来说,柱状图的X轴是时间维,用户习惯性认为存在时间趋势。如果遇到X轴不是时间维的情况,建议用颜色区分每根柱子,改变用户对时间趋势的关注。
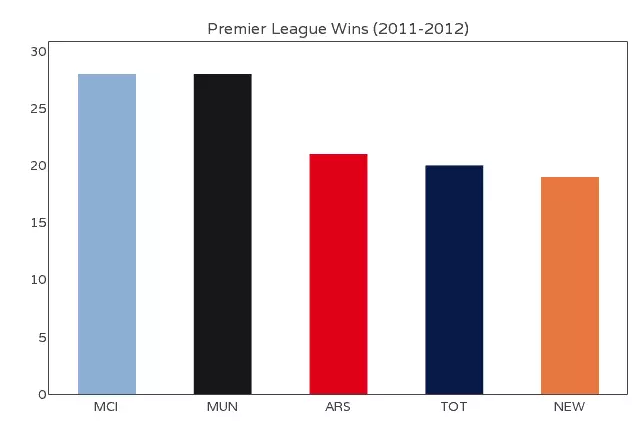
上图是英国足球联赛某个年度各队的赢球场数,X轴代表不同球队,Y轴代表赢球数。
5.2 折线图(Line Chart)数据
折线图适合二维的大数据集,尤其是那些趋势比单个数据点更重要的场合。
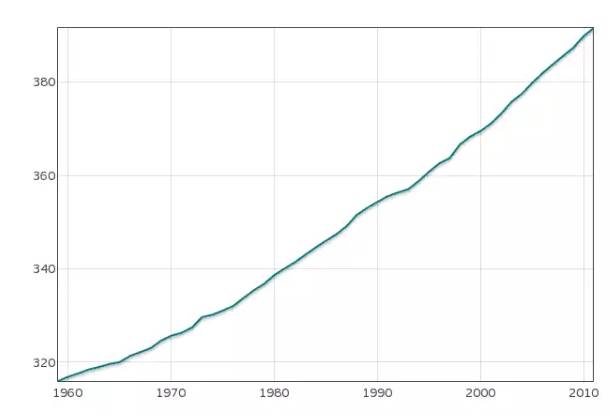
它还适合多个二维数据集的比较。
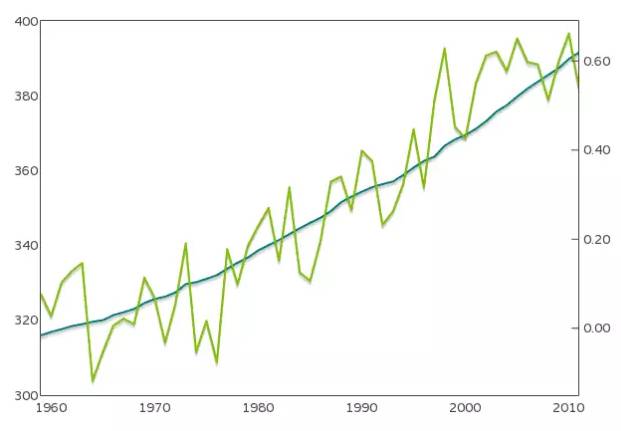
上图是两个二维数据集(大气中二氧化碳浓度,地表平均气温)的折线图。
5.3 饼图(Pie Chart)
饼图是一种应该避免使用的图表,因为肉眼对面积大小不敏感。
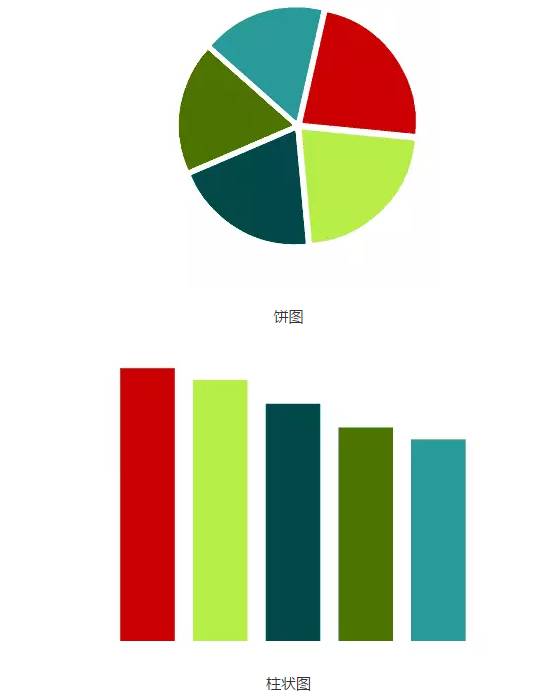
上图中,左侧饼图的五个色块的面积排序,不容易看出来。换成柱状图,就容易多了。
一般情况下,总是应该用柱状图替代饼图。但是有一个例外,就是反映某个部分占整体的比重,比如贫穷人口占总人口的百分比。
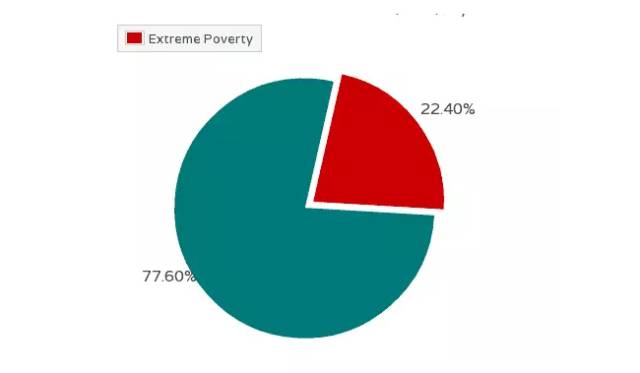
5.4 散点图(Scatter Chart)
散点图适用于三维数据集,但其中只有两维需要比较。
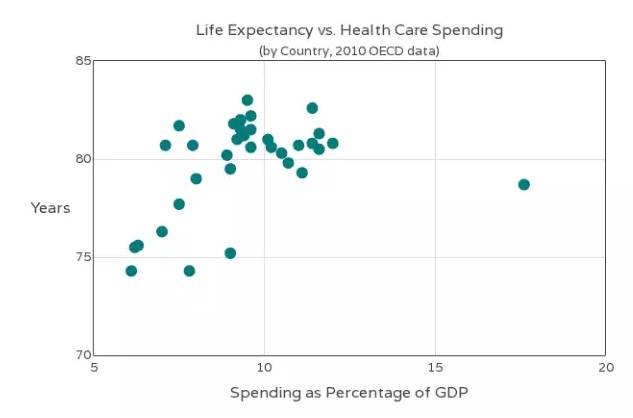
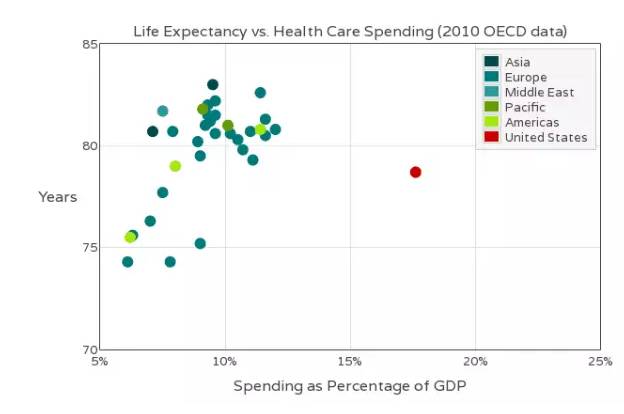
上图是各国的医疗支出与预期寿命,三个维度分别为国家、医疗支出、预期寿命,只有后两个维度需要比较。
为了识别第三维,可以为每个点加上文字标示,或者不同颜色。
5.5 气泡图(Bubble Chart)
气泡图是散点图的一种变体,通过每个点的面积大小,反映第三维。
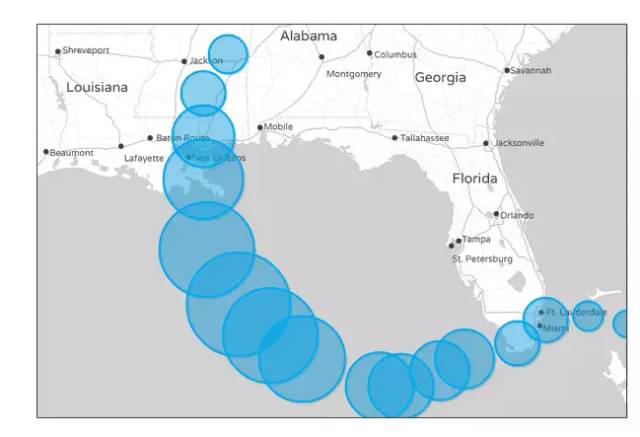
上图是卡特里娜飓风的路径,三个维度分别为经度、纬度、强度。点的面积越大,就代表强度越大。因为用户不善于判断面积大小,所以气泡图只适用不要求精确辨识第三维的场合。
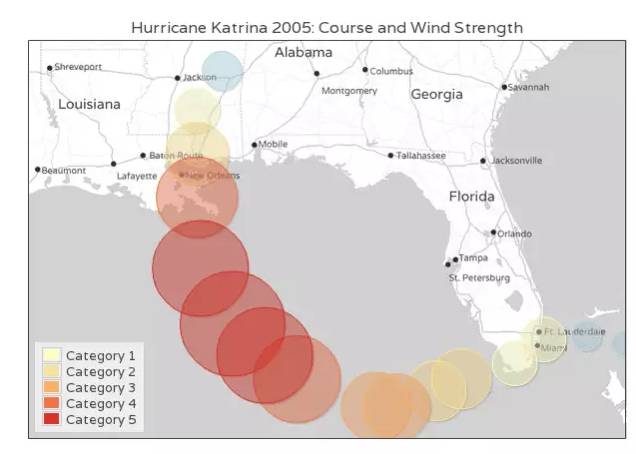
如果为气泡加上不同颜色(或文字标签),气泡图就可用来表达四维数据。比如下图就是通过颜色,表示每个点的风力等级。
5.6 雷达图(Radar Chart)
雷达图适用于多维数据(四维以上),且每个维度必须可以排序(国籍就不可以排序)。但是,它有一个局限,就是数据点最多6个,否则无法辨别,因此适用场合有限。
下面是迈阿密热火队首发的五名篮球选手的数据。除了姓名,每个数据点有五个维度,分别是得分、篮板、助攻、抢断、封盖。

画成雷达图,就是下面这样。

面积越大的数据点,就表示越重要。很显然,勒布朗·詹姆斯(红色区域)是热火队最重要的选手。
需要注意的时候,用户不熟悉雷达图,解读有困难。使用时尽量加上说明,减轻解读负担。
总结

▼
往期精彩文章回顾












