作者:吴春鹏,胡祥杰
【新智元导读】 近日, Cell 的一项研究在人脸识别领域引起轰动,研究揭示了灵长类动物人脸识别的具体神经元活动过程——对脸部的识别是由大脑中 200 多个不同神经元共同编码完成的,这一发现推翻了此前人脸由特定细胞识别的假说。本文认为,这一发现,可能会破解长久以来计算机视觉领域祖母细胞论与还原论之争。为什么计算机人脸识别会超越人类,我们找到了5个优势。

作者吴春鹏:杜克大学电子与计算机工程系在读博士生,前富士通研发中心研究员,曾在美光、LG北美实验室等公司实习。研究方向是机器学习,计算机视觉和模式识别。
6月3日,新智元报道,发表在 Cell 的一项研究揭示了人脸识别的具体神经元活动过程。对猕猴的实验表明,对脸部的识别是由大脑中 200 多个不同神经元共同编码完成的,每个神经元会对一张脸不同特征的参数组合进行相应。这一发现推翻了此前人脸由特定细胞识别的假说。
论文的摘要部分介绍说:灵长类动物以惊人的速度和可靠性识别复杂的物体,比如动物的脸。本文中,我们揭示了大脑进行面部识别的代码。猕猴实验表明,在面部结构中,面部和细胞反应之间存在着非常简单的转变。通过将动物的脸格式化为高维线性空间中的点,我们发现每个脸细胞的发射速率(firing rate)与入射面部刺激在该空间单个轴上的投影成正比,这样一来,一个脸细胞就能对空间中任何位置的脸进行集合编码。使用这个代码,我们可以精确地解码面部神经元群的反应,并预测关于动物脸的神经发射速率。此外,这一代码推翻了此前由来已久的假设,那就是脸细胞会对特定的面部特征进行编码。我们的研究表明,其他对象也可以由类似的度量坐标系统进行编码。
《纽约时报》报道称,机器学习给神经科学带来了一种悲观主义色彩,认为大脑类似黑箱,该论文则提供了反例:研究人员记录了视觉系统最高级的神经元信号,可以看到那里没有黑箱,我们完全可能揭开大脑的奥秘。
这一研究的重要意义在于,可以推翻祖母细胞假说和验证还原论的正确性,这是计算机视觉和脑科学研究中一直以来的争论。
“祖母细胞”(grandmother cell)是1969年麻省理工学院 Lettvin 教授在他的课程上提出的[1]。这种学说的核心观点认为人脑中存在一些“超级神经元”,单独一个这样的神经元就能对一些复杂的目标(如人脸)有特异性反应,而不需依靠大量神经元相互协同工作。比如,来自加州理工学院等机构的研究者在2005年发现人脑内侧颞叶的神经元会选择性注意人脸、动物、自然场景等[2]。
“祖母细胞”学说是否成立还没有最终的结论,但很有意思的一个现象是: 尽管大多数神经学家并不认可祖母细胞学说,但总有一部分人工智能相关领域的研究者试图通过自己的实验证明 “超级神经元”是有可能存在的,其中不乏业内知名学者,比如机器学习专家Andrew Ng [3]和小波分析领域专家Stephane Mallat [4]。
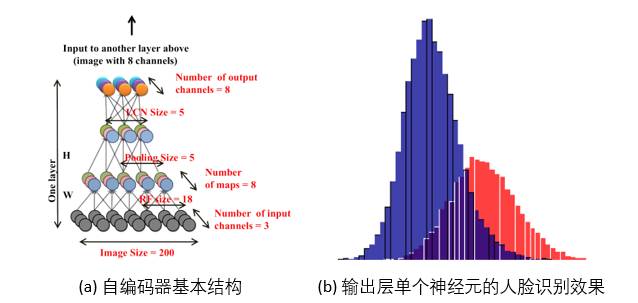
图1. 大规模无监督学习的深度自编码器及其识别效果[3].
图1(a)展示了Ng研究组提出的大规模无监督学习的深度自编码器(auto-encoder),图1(b)展示了这个自编码器输出层中的单个神经元在“人脸-非人脸”的区分能力[3]。
由于输出层单个神经元具有很好的判别效果,所以这篇文章据此认为祖母细胞是有可能存在的。不过我们应该认识到: 这些文章想强调的是模型中的某些基本单元具有与祖母细胞相同的能力, 是想强调训练算法和模型设计很合理。这些工程实验远远不足以支持生物脑中存在类似的情况。
还原论(reductionism)是个哲学概念,强调分析一个复杂事物时必须首先将其分解成相对简单的部件,然后逐一进行分析再组合。与还原论相对的是整体论(holism),强调不可割裂地分析一个整体事物的每个局部。比如,西方科学比较重视还原论,我国中医更侧重整体论。
具体到对人脑视神经机制的研究,还原论的代表是20世纪70年代开始兴起的Marr视觉理论框架[5],整体论的代表是20世纪20年代出现的Gestalt理论[6]。
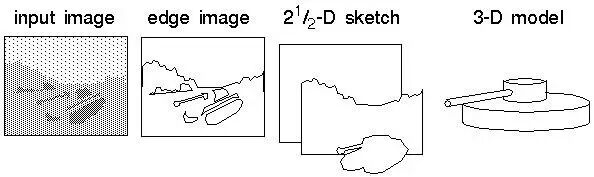
图2. Marr视觉理论的三级表象结构[9].
如图2所示,Marr理论认为视觉场景理解分为三级表象结构依次为: 图像基元,轮廓和深度,场景中物体的三维形状。也就是说,Marr理论认为局部特征加工优先于整体。Gestalt理论认为人类能从复杂场景中提取语义的关键步骤是对视觉场景形成了整体概念,整体视觉信息优先于局部信息得到加工,这也是和Marr理论的主要区别之一。尽管Gestalt理论中关于”把整体作为与局部之和不同的存在”并没有得到足够的后续理论和实验的支持,但有一些经典动物行为学实验发现确实存在大范围性质的知觉优先于局部性质 [7],这说明按照Gestalt理论去建立视觉模型有一定的合理性。计算机视觉方法[8]往往同时使用Marr和Gestalt理论,这两个理论在工程实践中可以互补。具体做法就是根据Marr理论在图像局部区域上提取最简单的边缘特征,利用统计学习方法从边缘特征中提取更高阶特征(局部轮廓和几何形状);同时根据具体Gestalt原理(collinearity, proximity, closure, continuation等)提取对应特征。
计算机做人脸识别的几个挑战是: 要能够有选择的注意重点区域而不是逐像素扫描,要能够抵抗噪声、光照和复杂背景,识别缩放、旋转和平移的人脸,自动去掉脸部遮挡和局部变形,从安全角度还要能够区分真实人脸和人脸面具。还有一个问题是很多人脸识别算法的细节是“黑箱”,物理意义不明确,很难解释。
比如对于一个基于深度神经网络的人脸识别算法,我们很多时候无法解释每个神经元对于识别结果到底有多少贡献,这就导致我们无法对识别错误进行溯源和系统性修正。特别是深度神经网络中比较靠后的卷积层模板包含很多高频噪声,这意味着网络可能学到了与人脸无关的特征,虽然准确率很高。
以上这些挑战和问题在人类观察者看来都可以很轻松地应对,原因是人脑视觉通路在长期进化中形成了功能完整并且优化的分层结构,逐层向上处理更加复杂的信息。对于人脸识别任务,这个分层结构能够从局部特征逐步学习到更大脸部区域的特征直到全脸,并过滤掉与人脸无关的信息,通过与人脑记忆等其他分区合作可以“脑补”人脸遮挡或不清晰的部分。
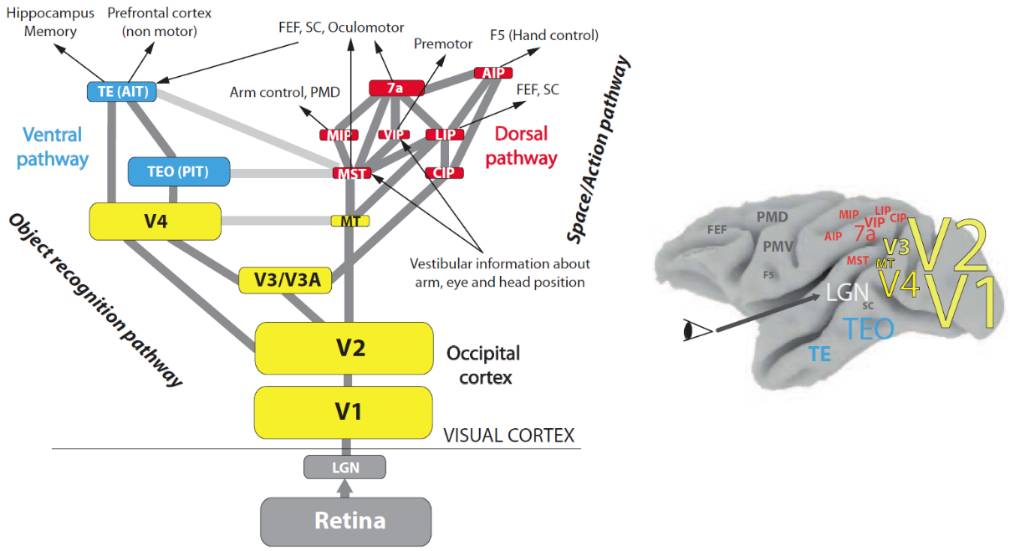
图3. 人脑视皮层中的视觉通路[10].
图3展示了人脑视皮层中的视觉通路[10],视网膜接收的信息通过侧膝体(lateral geniculate nucleus, LGN)传送给V1区。视网膜的“中央凹-周边”特性保证了选择性注意机制。V1和V2区负责初级视觉信息处理(局部边缘、简单几何形状等),处理后的信息被交给V2分区之上的两个分支: 与目标识别相关的V3、V4区(what通路),和与运动相关的MT、MST等分区(where通路)。通过这两个分支处理的信息会进一步与海马记忆区、前额叶皮层、前运动区等进行交互。
图3中各个分区的大小比例基本符合真实情况,可以看到处理基元信息的V1和V2分区面积最大,而在V2分区之上的两个分支中左侧what通路比右侧where通路的分区基本都要大一些,我们可以猜测可能是因为what通路处理的信息更多,或者因为what通路更重要,亦或是where通路的分工更精细所以其中每个分区的面积相对较小。除了所有视觉识别任务都会激活的脑区,人脸图像还会特异地激活FFA(fusiform face area)和OFA(occipital face area)等脑区。
与人脑相比,计算机做人脸识别的主要优势在于信息传递的能量转换方式、信息编码方式、海量视觉信息处理的可扩展性、计算资源和处理速度、偏置及纠正能力。人脑是一个受限的低功耗系统,并且学习过程中存在偏置,而计算机基本没有这些情况。
第一,人脑中神经兴奋在每个神经元上以电能形式传导,而在神经元之间会在神经递质(neurotransmitter, 如5-羟色胺)的帮助下由电能转化为化学能,然后在传递到下一个神经元时重新转化为电能。能量转换消耗时间,并且化学能状态的处理速度一般会低于电能,而计算机视觉没有电能和化学能的转换状态。
第二,在大脑神经元上传导的神经兴奋是电脉冲信号,而脉冲信号需要保持时序关系,这大大增加了信息编码的难度。计算机一般不采用这种脉冲信号对视觉特征进行编码。
第三,面对海量视觉时,搭建分析能力更强的分布式机器学习系统是相对容易的,而实现人脑扩展是很困难的。脑机接口可以作为实现人脑扩展的一项技术,但仍有很多难点需要得到解决。
第四,虽然神经元之间的连接强度可以在使用中得到调整,但视觉通路中的一些计算资源是有限的,比如视网膜中视杆细胞(处理亮度信息)和视锥细胞(处理彩色信息)的数量,还有图3中各个分区的大小,所以人脑视觉信息处理的速度上限是相对固定的。而计算机的各项计算资源是可以持续增长的,速度上限也是可以不断提升的。
第五,认知心理学的一个经典实验发现: 东方人区分西方人脸的能力显著低于东方人区分东方人脸的能力。这说明人类的人脸识别过程受到遗传、心理和社会环境等多因素共同影响,存在固有的偏置,会出现识别效果两极化的情况。而计算机的人脸识别过程不存在这些人类才有的偏置,即使有其他偏置也可以通过调整样本和训练方法进行快速纠正,保证对各类人脸样本的识别能力接近。
近年来基于深度学习的计算机视觉方法在图像分类等方面取得了突破性进展,但有一些关键技术点还需要进一步研究: 从图像/视频中提取更高层次的语义,基于视觉信息做复杂决策,提出功能更完善的算法。

图4. 艺术风格迁移[11]: (a) 输入图像, (b) 艺术作品, (c) 施加了艺术作品风格的输入图像.
在图像/视频理解方面,目前的研究工作越来越关注对于抽象语义的理解,比如艺术风格迁移(artistic style transfer)[11],如图4所示。从一幅图像中提取客观语义(比如图像前景和背景物体)是比较成熟的传统工作,但提取抽象语义(比如图像想表达的意图、艺术风格)仍是一项很有挑战的工作。
近年来对抗模型GAN被普遍用到图像语义理解特别是抽象概念提取和迁移这方面的论文中,因为GAN通过有监督鉴别真伪的过程,使得无监督特征表示的判别能力更强,有助于无监督模型学习抽象语义。但是用GAN是否能提取到更高层次的语义在业内还是有争议的。还有一些研究工作通过图像和文本注释进行协同学习,形成了局部图像与文字的映射,即这个模型可以把新输入的图像转换成文字,或者反过来。通过文本辅助图像语义学习就像人类的“看图说话”,也是一种很有效的解决方案。
在基于视觉信息的复杂决策方面,目前比较有意思的研究是把深度神经网络和增强学习相结合,用于学习电子游戏的动作控制。目前增强学习的使用有两种方法: 一种是像AlphaGo一样用不同的模型去学习policy和value,然后用类似Monte-Carlo tree search的搜索方法把policy和value结合到一起,再寻找最优action。还有一种方法多用于action是离散的情况(一般游戏只有上下左右四个方向),直接用一个深度神经网络实现从当前status到action选择的映射,也就是把policy的学习过程嵌入到了这个网络中。 在具体使用时,需要进一步研究的问题之一如图5所示,就是如何把表示当前状态的图像、期望以及实际执行效果等内容送入网络,为当前action的选择提供更多有效的指导。
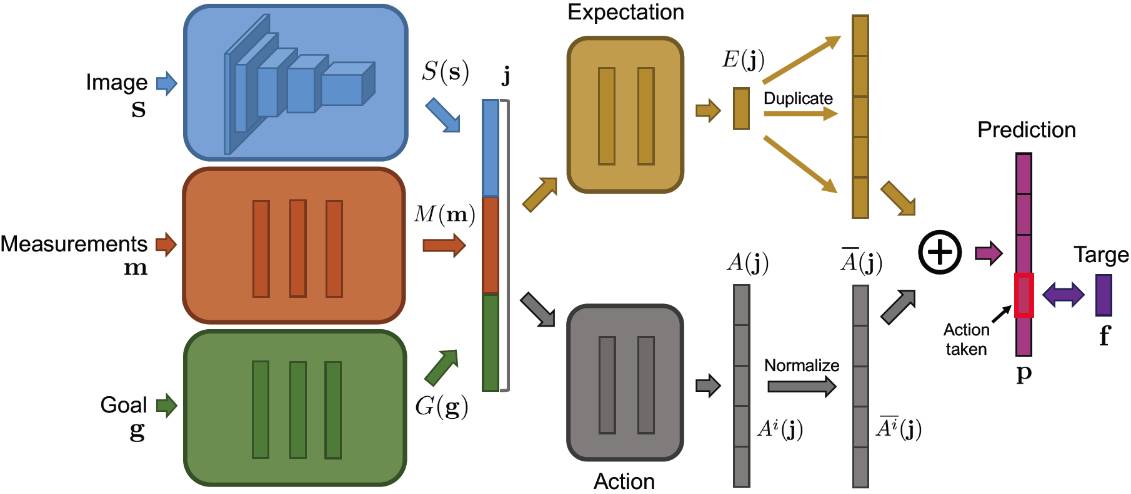
图5. 用于学习游戏中动作控制的神经网络结构[12].
功能更完善的算法是指算法不能有明显缺陷。GoodFellow等人在2014年的NIPS文章指出把反向传播的梯度加到输入图像上,然后用这个修改后的图像(adversarial example)送入模型就可导致识别错误。我们以往过于关注一个模型的预测精度,而忽略了这个模型可以被敌手利用的弱点。总体来看,一个模型的各项属性之间一般是一种此消彼长的关系。一个模型的参数增多,往往可以提高预测精度,但同时也意味着敌手对模型局部做修改更不易被察觉。
计算机视觉可以分为仿生视觉派和纯粹建立在数学上的视觉派。两派之间争议的焦点之一就是: 我们是否需要去模拟人,以及我们需要在多大程度上去模拟人。多年来两派都得到了发展,并且相互之间有很大的交集。一个很有意思的例子就是卷积神经网络CNN的设计原理来自于20世纪60年的猫视网膜实验[13],但CNN提出者Yann Lecun在公开场合反复表示他更愿意叫卷积网络,不愿意加上“神经”二字,因为他认为现在的卷积神经网络已经和早期的生物学发现有很大差别了。
生物学研究与计算机视觉的关系很大程度上取决人工智能技术的发展以及我们对待人工智能的态度。
在深度学习技术出现以前,基于传统机器学习的计算机视觉技术往往不是很理想,与人们的期望有很大差别,最简单的例子就是传统方法在知名图像库ImageNet的分类效果远远没有达到实用标准。因为人的正确率在此时占据上风,所以有相当一部分研究者更愿意从人类感知和认知系统去寻找灵感来改进算法。比如根据图2的人脑视觉通路,计算机视觉研究者把重点放在了对what和where通路建模,以及这两个通路交互的建模。由此出现了一些算法采用贝叶斯图等方法模拟what和where通路来建立视觉注意模型[14],如图6。
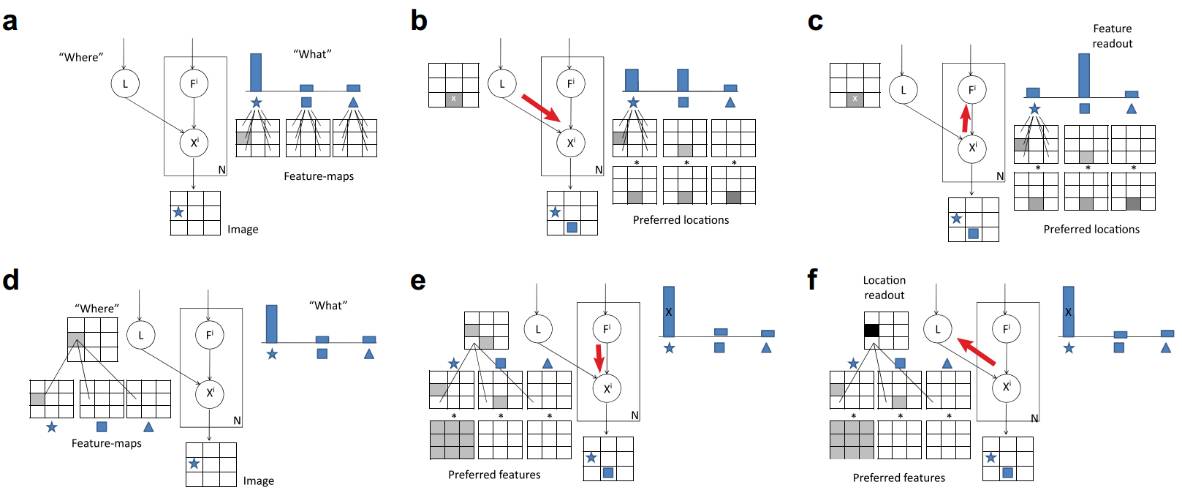
图6. 基于what和where通路的Bayesian视觉注意模型[14].
深度学习技术出现之后,情况发生了一些变化。深度神经网络在图像分类取得了惊人的效果,极大的缩短了算法和人类在一些视觉任务上的准确率差距。与此同时,以“神威·太湖之光”为代表的超级计算机在不断挑战远远高于人类的数学运算速度。这种情况下,以前被压制的声音再次浮出水面: 计算机比人算得快,在简单学习任务上已接近人,虽然在情感计算和某些复杂决策领域还暂时不如人,但我们真的还有必要去继续学习人吗?
如果不那么依赖对人的研究,而是依靠计算机的强大计算能力,是否能够衍生出比人还有效的推理技巧? AlphaGo可以为这种观点提供一些参考。AlphaGo学习过少量人类棋谱,但AlphaGo的训练更多通过自我博弈来提升棋力,自我博弈严重依赖计算能力。它走出的棋总是出乎所有人类围棋高手的意料,不按人的套路而战胜了人。当然,AlphaGo只是一个按照明确的规则和明确的棋面下围棋的简单机器,还达不到超越人的人工智能即强人工智能(artificial general intelligence, AGI)。
以现在的计算机视觉发展水平(或者人工智能发展水平),在到达强人工智能这个“奇点”之前,我们可能还是需要同时从仿生学和纯数学这两个角度去提升计算机视觉技术。因为强人工智能所需要的推理能力中还有很多基本特点我们没有搞清楚,除了人和其他生物,我们还没有更好的学习对象,特别是人所具有的联想和顿悟能力是现在计算机欠缺的。
在进一步加强对人类视觉通路(图3)研究的基础上,我们还需要探索的是人脑中长期和短期记忆是如何相互配合来完成视觉任务的,LSTM和GRU这两种RNN模型只是与记忆相关的简化建模方法。
最后,还有一个很本质的问题需要研究,就是神经元集群编码。通过电物理学手段对神经元进行刺激,我们对于单个神经元的属性已经比较了解了,但大量神经元是如何通过相互配合来完成计算任务的我们还知之甚少。我们应该看到,近年来神经网络复兴的背后有一个必不可少的推手,就是以GPU为代表的高性能计算芯片的发展。生物学、神经科学、实验心理学在未来的突破也必将再次带动计算机视觉技术的飞跃。
参考文献:
[1] H. B. Barlow. The neuron in perception. In: Gazzaniga MS, editor. The cognitive neurosciences. Cambridge (MA): MIT Press, pp. 415–34, 1995.
[2] R. Q. Quiroga, L. Reddy, G. Kreiman, C. Koch, and I. Fried. Invariant visual representation by single neurons in the human brain. Nature, vol. 435, pp. 1102-1107, 2005.
[3] Q. V. Le, M. A. Ranzato, M. Devin, K. Chen, G. S. Corrado, J. Dean and Andrew Y. Ng. Building high-level features using large scale unsupervised learning. ICML, 2012.
[4] S. Mallat. Understanding deep convolutional networks. Philosophical Transactions A, vol. 374, iss. 2065, 2016.
[5] D. Marr. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. New York: Freeman, 1982.
[6] Smith, Barry. Foundations of Gestalt Theory, Munich and Vienna: Philosophia Verlag, 1988.
[7] L. Chen, S. Zhang and M. V. Srinivasan. Global Perception in Small Brains: Topological Pattern Recognition in Honey Bees. PNAS, pp. 6884-6889, 2003.
[8] O. L. Meur, P. L. Callet, D. Barba and D. Thoreau. A coherent computational approach to model bottom-up visual attention. PAMI, vol. 28, no. 5, 2006.
[9] http://cns-alumni.bu.edu/~slehar/webstuff/pcave/marr.html
[10] N. Kruger, P. Janssen, S. Kalkan, M. Lappe, A. Leonardis, J. Piater, A. J. Rodriguez-Sanchez, and L. Wiskott. Deep hierarchies in the primate visual cortex: What can we learn for computer vision. PAMI, vol. 6, no. 1, 2007.
[11] Y. Jing, Y. Yang, Z. Feng, J. Ye and M. Song. Neural style transfer: A review. arXiv:1705.04058v1, 2017.
[12] A. Dosovitskiy and V. Koltun. Learning to act by predicting the future. ICLR, 2017.
[13] D. H. Wiesel and T. N. Hubel. Receptive fields of single neurons in the cat’s striate cortex. J. Physiol., 148:574–591, 1959.
[14] S. Chikkerur, T. Serre, C. Tan and T. Poggio. What and where: A Bayesian inference theory of attention. Vision Research, 50(22):2233-47, 2010.











