今天介绍一个项目案例,利用大语言模型打造上市公司财务报表智能问答系统。
在当今竞争激烈的市场环境中,企业和投资者对财务信息的获取与分析要求越来越高。
上市公司财务报表作为评估公司财务健康和未来发展的重要依据,提供了大量关键信息。
然而,传统的财务报表分析技术不成熟、依赖很多人工解读,费时且容易出现误差,痛点如下。

随着大数据技术和人工智能的快速发展,如何高效、准确地从这些海量数据中提取有价值的信息成为了一个亟待解决的问题。
智能问答系统为解决这一问题提供了创新解决方案。通过先进的自然语言处理技术,智能问答系统可以快速解读财务报表,自动回答涉及财务、市场趋势和投资策略的问题,如下图所示。

构建一个上市公司财务报表智能问答系统,需要通过如下核心步骤:
-
数据收集
:利用爬虫技术从财经网站上抓取上市公司的季度、半年、年度财报,这些财报通常以PDF格式存储。
-
数据处理
:将非结构化的PDF内容转换为结构化数据。这通常是一个难点,后面会详细展开处理和分析。
-
RAG系统搭建
:构建基于RAG(检索增强生成)的智能问答系统。首先,将处理后的数据导入向量数据库中,并利用双编码器模型进行向量化处理。然后,集成大语言模型(如GPT-4)与检索系统,通过提示工程和重排序技术优化模型的输出,以提高对财报内容的理解和回答质量。
问答系统,基于RAG实现,其流程如下图所示。

下面,就通过具体代码案例来搭建
上市公司财务报表智能问答系统
。
一、数据收集
通过使用爬虫技术,用selenium库来做模拟批量下载公司的财报,具体过程如下:
第一步:引入相关的包。
from selenium import webdriverfrom selenium.webdriver.common.action_chains import ActionChainsimport timefrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import By
第二步:
写了一个用于判断可供选择的链接是年报还是年报摘要的函数。
因为研究中需要的是年报,就把后文调用函数用到的关键词定为了“摘要
”。
def check_word(sentence, word): if word in sentence: return True else: return False
第三步:接下来就是用于自动化测试的函数啦!在这里,定义了一个download_report函数,当调用函数时,输入股票代码code,函数将会执行自动测试操作并下载网页。
def download_report(code): browser = webdriver.Edge() url = 'http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/notice#sse' browser.get(url) browser.maximize_window() browser.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div[1]/div[2]/form/div[1]/div/div/input[1]').send_keys('2022-12-31') browser.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div[1]/div[2]/form/div[1]/div/div/input[2]').send_keys('2022-06-15') browser.find_element_by_xpath('//*[@id="main"]/div[2]/div[1]/div[2]/div[1]/div[2]/form/div[2]/div[3]/div/div/span/button').click() browser.find_element_by_xpath('/html/body/div[6]/div[1]/label[1]/span[1]/span').click() browser.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[1]/div[2]/div[1]/div[2]/form/div[2]/div[1]/div/div/div/div/input').send_keys(code) time.sleep(3) button_element = browser.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[1]/div[2]/div[1]/div[2]/div[1]/button') actions = ActionChains(browser) actions.move_to_element(button_element).click().perform() time.sleep(3) try: word = "摘要" browser_text = browser.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[1]/div[1]/div[2]/div/div[3]/table/tbody/tr[2]/td[3]/div/span/a').text if check_word(browser_text, word): browser.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[1]/div[1]/div[2]/div/div[3]/table/tbody/tr[1]/td[3]/div/span/a').click() window_handles = browser.window_handles latest_window_handle = window_handles[-1] browser.switch_to.window(latest_window_handle) else: browser.find_element_by_xpath('/html/body/div[2]/div/div[2]/div[1]/div[1]/div[2]/div/div[3]/table/tbody/tr[2]/td[3]/div/span/a').click() window_handles = browser.window_handles latest_window_handle = window_handles[-1] browser.switch_to.window(latest_window_handle) browser_url = browser.current_url except Exception as e: print("没有找到",code,"的对应年报") browser.quit() return if browser_url == "http://www.cninfo.com.cn/new/disclosure/detail?stockCode=688669&announcementId=1217087254&orgId=gfbj0833817&announcementTime=2023-06-17" or browser_url == "http://www.cninfo.com.cn/new/disclosure/detail?stockCode=603825&announcementId=1217085098&orgId=9900024448&announcementTime=2023-06-17": print("没有",code,"对应的公司") browser.quit() else: browser2 = webdriver.Edge() browser2.get(browser_url) browser2.find_element_by_xpath('/html/body/div[1]/div/div[1]/div[3]/div[1]/button').click() time.sleep(10) print("已成功下载",code,"公司的年报") browser.quit() browser2.quit()
第四步:调用download_report方法开始下载。
code = "600519"download_report(code)
二、数据处理
数据处理的目的是将PDF文件解析成结构化的数据,以便为后续的RAG系统做好准备。此过程包括提取和整理文本中的关键信息,如财务数据、表格和图表,从而确保数据的结构化格式能够支持高效的检索和生成操作。
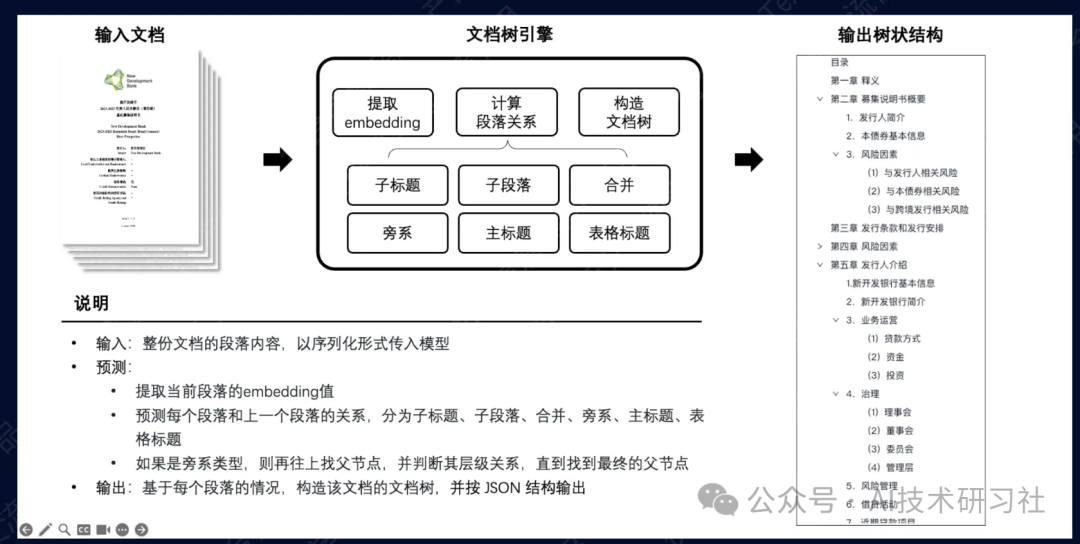
一、文档解析的准确性对RAG系统的影响
在RAG的预处理阶段,文档解析的准确性至关重要,因为任何解析上的误差都会直接影响后续的检索和生成结果,进而影响整个系统的性能。以下是文档解析不准确可能带来的具体问题及其影响:
-
信息丢失
:如果解析不准确,财务报表中的关键信息可能会丢失或被误解,这会导致模型无法正确回答用户的查询。
-
数据错误
:解析错误可能会导致财务数据的错位或误读,从而影响生成的回答的准确性和可靠性。
-
检索效率降低
:结构化数据的准确性直接影响到检索的效果。如果数据结构不一致或不准确,将会增加检索难度,降低检索效率。
-
模型性能下降
:文档解析的不准确性可能导致模型在训练和推理阶段的性能下降,使得生成的答案不够精准或有偏差。
因此,对于面向消费者的文档问答RAG系统应用产品,精准的文档解析显得尤为重要。这不仅保证了数据的完整性和准确性,还能显著提高系统的整体性能和用户体验。精准解析确保了关键信息的正确提取和结构化,进而提升了检索的效率和生成的回答的质量。
二、PDF文档解析的技术路线
对于简单的文档解析,Python提供了很多PDF解析工具,如PDFplumber、pyPDF2或简单的开源的ocr工具(如:Paddleocr)等能够对多种文件类型进行解析。下图是一个标准的文档解析流程。

然而,对于更复杂的文档解析,尤其是涉及大量图表、复杂表格或非标准格式的财务报表时,单一的开源工具可能难以满足需求。
这种情况下,选择商用的高性能工具就显得尤为重要。这些工具通常具备更强的功能、更高的准确性和更好的技术支持,能够有效处理复杂的文档结构和数据格式。
在我们的项目中,使用了一款商业文档解析服务TextIn,工作台如下图所示,上传了一份贵州茅台2023年的年报。

TextIn
解析PDF,具有以下优势:



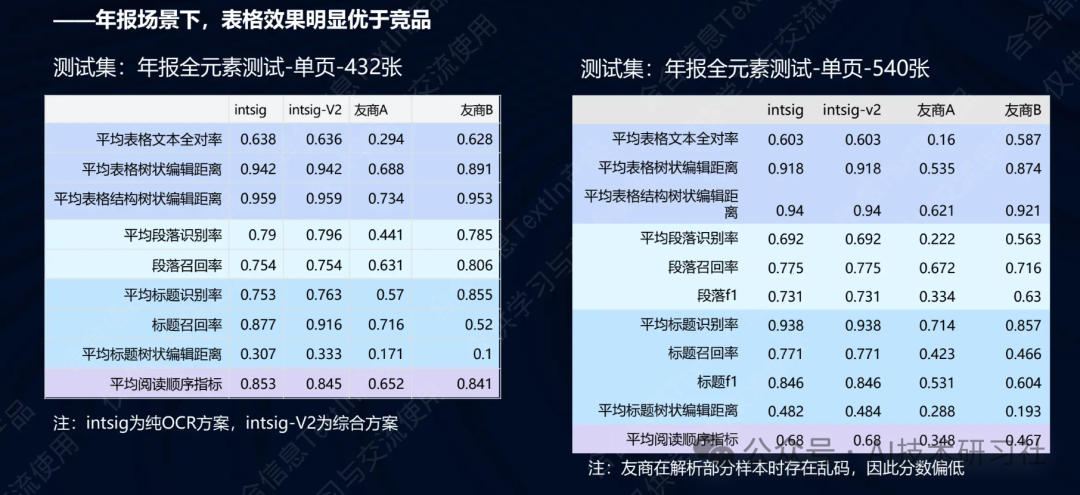
下图是我们通过测试得到的性能指标。通过对比发现,整体的速度、召回率、正确率都比较高,非常适合我们的业务场景。
此外,在批量解析PDF的场景中,TextIn还提供了各种编程语言的API接口,如下图所示。
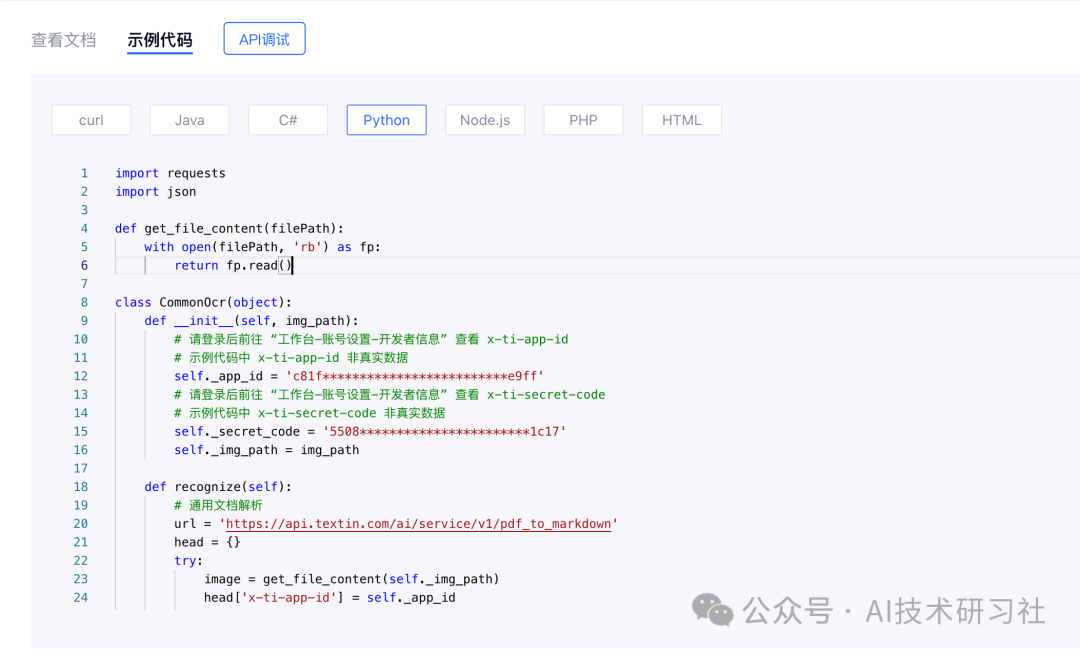
在使用API调用接口的时候,需要先获取对应的app_id 和 secret_code,获取方式,在账号管理-开发者信息中,如下图所示。

这样就可以调用TextIn的API服务将PDF的年报解析成结构化的数据。
这里我提供一个Python的调用示例,帮助你快速调用。
import requests
class CommonOcr(object): def __init__(self, img_path): self._app_id = '0c88509xxxx' self._secret_code = '3017d8ccxxxx' self._img_path = img_path
def get_file_content(self): with open(self._img_path, 'rb') as fp: return fp.read()
def recognize(self): url = 'https://api.textin.com/ai/service/v1/pdf_to_markdown'










