
一直以来,谷歌都被冠以最为成功的互联网公司的美名,但在这些绝佳的赞誉背后,殊不知是何等庞大的服务器网络在小心翼翼地支撑着这个科技巨头每一天的稳定运行。
但为了适应在智能时代的游戏规则,谷歌也不得不做出改变,停止在服务器规模上的无限扩张,转移到开发机器学习专用处理器TPU的轨道上来。
据悉,谷歌目前共在全球四大洲建有15个仓库般大小的数据中心,这在以前是不敢想象的。六年前,谷歌开始为安卓操作系统添加语音识别功能之后,原来相对充裕的计算能力突然间显得捉襟见肘,根据当时谷歌工程师的推算——如果世界上每一台安卓手机每天都使用3分钟的语音搜索功能,那么谷歌的数据中心的规模就起码要翻倍。
更为“雪上加霜”的是,当时谷歌也刚刚开始利用深度神经网络来加速语音识别的研发,在这一过程中,研究人员通过调用复杂的算法和数学模型来对大量的数据进行分析,并以此解决特定的复杂任务。
可喜的是,随着技术的成熟,语音识别的错误率下降了25%,谷歌当即就决定要迅速将之进行商业应用,但这无疑又加重了对硬件设备的要求。
但在这种双重压力下,谷歌并没有直接将数据中心的规模简单的加倍,深思熟虑之后,他们找到了一种更为高效稳妥的解决方案——开发专属的机器学习处理器“张量处理单元”(Tensor Processing Unit, TPU)。
这款处理器的开发者之一的 Norm Jouppi 评价说:“这确信无疑可以显著提高工作的效率。”
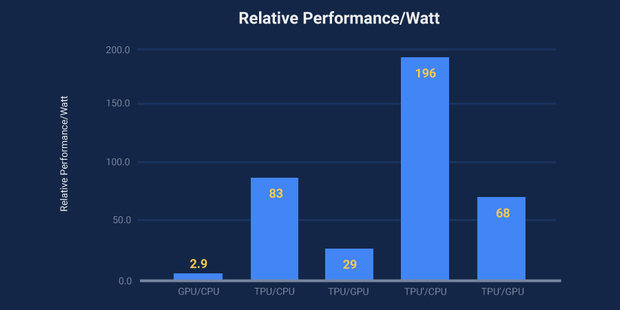
TPU同传统处理器在能耗效率上的表现对比
事实也的确如此,在TOPS / Watt(每瓦特性能)功耗效率测试中,TPU的性能要优于常规的处理器 30 到 80 倍;而同传统的GPU/ CPU的计算组合相比 ,TPU的处理速度也要快上15 到 30 倍;最为关键的是,由于TPU的运用,就连深度神经网络所需要的代码数量也大幅的减少,仅需要100到1500行代码就可以顺畅运行。
在 2016 年 5 月份,谷歌首次证实了“TPU”的存在,但并没有披露相关的技术细节,外界只知道在谷歌街景、AlphaGo等应用中用到了TPU。谷歌自己就称,在AlphaGo战胜李世石的比赛中,AlphaGo能够做出更快更准的判断,大部分功劳要归于TPU。

搭载TPU的电路板
今天,谷歌首次发表论文深度剖析了TPU的详细架构及相关技术细节,并将TPU在性能和效率上的表现与Haswell CPU和Nvidia Tesla K80 GPU做了详尽的比较,也向外界揭开了这款处理器的神秘面纱。
论文链接:https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view
论文的作者Jouppi表示,在谷歌决定开发定制的ASIC(专用集成电路,即日后的TPU)之前,该硬件团队曾寄希望于用FPGA(现场可编程门阵列)实现廉价、高效、高性能的推理系统。
人们最初想到利用FPGA,主要在于看重其灵活性,但是相比于ASIC,其受到可编程性和一些其它因素的限制,导致最终这些设备在性能和功耗上的表现与人们的预期有很大差距。

该论文作者之一Norm Jouppi
TPU 像 CPU 和 GPU 一样,可以进行编程操作。它的设计也不仅仅是针对某种神经网络模型,而是能够在多种神经网络(CNN、LSTM,以及大型全连接网络模型等)中执行CISC(复杂指令计算机)的指令。所不同的是,它将矩阵而不是矢量和标量作为原语。
原语是机器指令的延伸,往往是为了完成某些特定的功能而编制的一段系统程序。
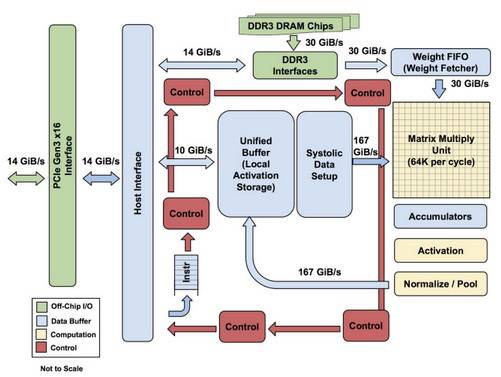
TPU整体框架,但不包括外接DDR3内存。左侧是主机接口,指令序列从主机发出(没有循环)。这些指令用于激活控制逻辑,控制逻辑可以基于指令(由于指令从主机传到芯片存在延迟,因此指令数量受到了限制)并反复运行该指令
不过,这并不意味着TPU有多复杂,它看起来更像雷达的信号处理引擎,而不是标准X86架构。此外“它与浮点单元协处理器更为神似,而跟GPU不太一样,”Jouppi表示,尽管TPU有较多矩阵乘法单元,它却没有任何储存程序,它仅仅执行主机下发的指令。
由于需要向矩阵乘法单元供给大量数据(通量在64000的数量级上),TPU上的动态随机存取存储器(DRAM)是作为一个独立单元并行运行的。Jouppi 说眼下还不知道TPU的扩展上限在哪里,只要你使用任何带有主机软件的加速器,就一定会有瓶颈。
很难解释它们是如何进行捆绑工作,也不太清楚哪里会是天花板在哪里,但鉴于在支持大规模运行推理芯片方面对既稳定又低成本的硬件的需求,我们可以想象它应该不是那种外部的RDMA/NVlink方式,或任何其他类似的方式。
TPU有两个存储器,一个外部DRAM用来存储模型内参数。进来的数据会被载入到矩阵乘法单元顶层,同时激活数据(或者说“神经元”的输出数据)还可以从左侧载入。数据以脉动阵列形式进入矩阵单元进而生成矩阵乘法运算,每周期内可以执行64000次这样的累计。
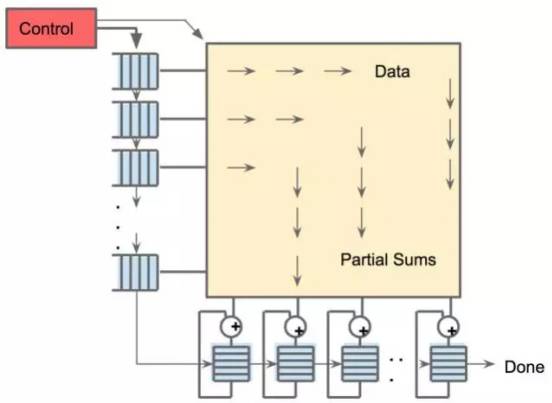
TPU中的收缩数据流引擎,它是256×256阵列
也许,你很容易想到,谷歌本可以采用一些新技术来为TPU加速。一个显而易见的选项就是使用高频宽存储器(HBM)或混合内存立方体(HMC)。然而,像谷歌这种巨大的业务规模导致的一大问题就是如何保持分布式硬件的稳定运行。
“如果你在新加坡用你的手机做了一次语音搜索,那么搜索就需要在当地数据中心执行,它必须是分布式的,因此,我们需要低成本、低功率的硬件。为了运行推理芯片去采用HBM也许有一点太极端,但是用于训练神经网络就是另一回事儿了。”
虽然谷歌已经完成了对TPU全方位的测试,开始底气十足地叫板CPU和GPU,但鉴于机器学习客户群中的大部分(不过Facebook是个引人注目的异类)都用CPU来处理推理,与英特尔Haswell Xeon E5 v3处理器相比较才无疑是最合适的。
而且,这个对比证明了在推理工作的多个层面上,TPU都甩出Xeon芯片十条街。这也正解释了,为什么本可以舒舒服服在自己的大型X86服务器群上继续运行机器学习推理的谷歌,还要花大力气特意开发TPU芯片了。
在谷歌的测试中,一个运行速度为2.3GHz并搭载64位浮点数学单元的十八核Haswell Xeon E5-2699 v3处理器能够处理每秒1.3T操作(1.3 TOPS)并实现51GB每秒的存储带宽。Haswell芯片的功率为145w,整个系统(存储空间256GB)高速运转时功率达455w。
相比之下,TPU采用 8 位整数数学单元,可读取256GB的主机存储,外加32GB的本地存储。它能够实现34GB每秒的存储带宽,处理能力达92TOPS——推理运算通量比Haswell多出71倍,而搭载TPU的服务器功耗为384w。
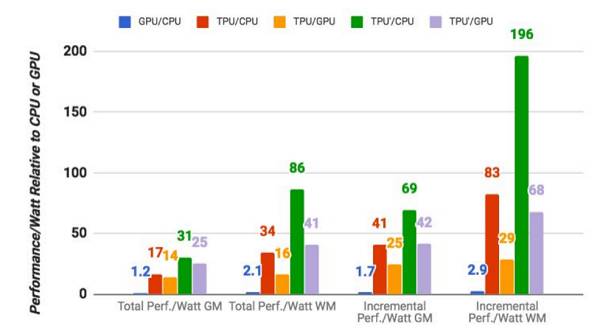
TPU与CPU和GPU的性能对比,GM 和 WM 分别代表几何学图形与加权平均值
此外,谷歌还测试了 CPU、GPU 和 TPU 在 7 微秒内处理不同批量大小的推理工作时的每秒推理通量:
当 Haswell CPU 处理批量大小为 16 的小批量工作,并在约 7 微秒内处理完99%的情况下,它可以实现每秒 5482 次推理(5482 IPS),为最高通量(13194 IPS,批量大小64)的42%。这里最高通量的实现条件为反应速度不受限制、且前 99%的处理任务允许拖到 21.3 微秒。
与之相比,TPU能够以 7 微秒的极限速度做 200 批量大小的推理,在运行推理基准测试时实现 225000 IPS,这个速度为其巅峰表现的 80%,这里巅峰表现的实现条件为 250 批量大小,以及完成前 99%处理任务的反应速度为 10 微秒。
谷歌测试的是版本相对较早的Haswell Xeon。如果用Broadwell Xeon E5 v4处理器的话,架构变化可以为内核的每时钟周期指令数(IPC)带来5%的提高;如果用今夏即将发布的Skylake Xeon E5 v5处理器,IPC或许会上升 9-10%。如果把内核数从Haswell的 18 提升到Skylake的 28,Xeon的推理总通量或许能提升80%,但这还是远远追不上与TPU的差距。
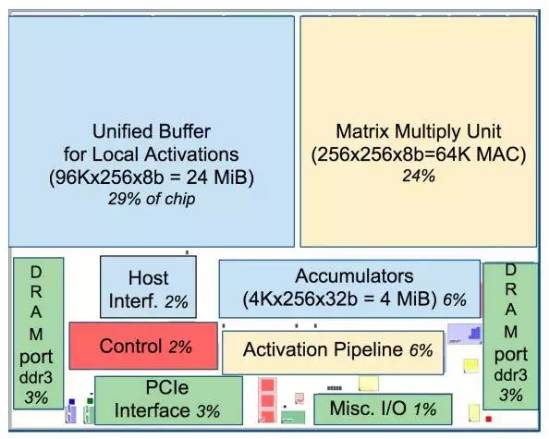
TPU 中各功能占比布局。蓝色的数据缓存占37%;黄色的计算占30%;绿色的I/O 占10%;红色的控制只有 2%。而在传统的CPU 或 GPU 中的控制部分则要大很多且不易设计
需要强调的是,这是推理芯片,所以我们看到的与 GPU 的对比结果并不能一概而论。GPU和CPU协同运算在谷歌的模型训练上依旧表现优秀。对于CPU制造商来说(好吧,其实就是英特尔),真正的挑战在于提供性能优越的推理芯片,并且在成本和能效上至少要接近定制类 ASIC 产品。
无论如何,Jouppi 表示:“我们完成了一次很匆忙的芯片开发,但干得非常漂亮。我们发布第一批硅芯片的时候,没有漏洞修复也没有掩码变化。我们一边招募团队一边开发芯片,然后再去雇佣RTL人员,再跑去找设计鉴定测试人员。这真是个令人兴奋的过程”。

本论文的另一位作者也是计算领域的另一位大师、RAID磁盘保护的发明者以及RISC之父——David Patterson(如上图)。不得承认,这的确是一个超一流的团队。
MIT Technology Review 中国唯一版权合作方,任何机构及个人未经许可,不得擅自转载及翻译。
分享至朋友圈才是义举

一个魔性的科幻号,据说他们都关注了











