 「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
「论文访谈间」是由 PaperWeekly 和中国中文信息学会青工委联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。
论文作者 |
郑孙聪,王峰,包红云,郝悦星,周鹏,徐波
(中科院自动化研究所)
特约记者 | 钟世敏(西华大学)
本期论文访谈间我们将以“川普百科信息抽取”为例,来向大家介绍来自中科院自动化研究所的郑孙聪同学,王峰同学,包红云老师,郝悦星同学,周鹏同学,徐波老师的相关工作。他们的论文“Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme”发表在今年的 ACL 2017 上,并被评为 ACL 2017 杰出论文。
实体和关系的联合抽取问题作为信息抽取的关键任务,其实现方法可以简单分为两类:一类是串联抽取方法。另一类是联合抽取方法。串联抽取方法将该问题分解为两个串联的子任务,即先采用实体识别模型抽取实体,再采用关系抽取模型得到实体对之间的关系,其优势是便于单独优化实体识别任务和关系抽取任务,但缺点是它们以获取三元组的中间产物(实体或者关系类型)为目标,而实体识别的结果会进一步影响关系抽取的结果,导致误差累积。不同于串联抽取方法,联合抽取方法使用一个模型同时抽取实体及其关系,能够更好的整合实体及其关系之间的信息。但现有的联合抽取方法也存在诸多问题,比如:大部分的联合抽取模型需要人工参与构建特征;基于 end to end 的联合抽取模型,因在模型实现过程中分开抽取实体及其关系而导致信息冗余等问题。近期郑孙聪同学,王峰同学,包红云老师,郝悦星同学,周鹏同学,徐波老师在论文“Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme”中提出了一个新的模型框架来解决此类问题,并在公开数据集 NYT 上取得了很好的效果。
接下来我们先来看看该模型能够干些什么。如下图,模型的输入为一句非结构化的文本,输出为一个预定义关系类型的三元组。
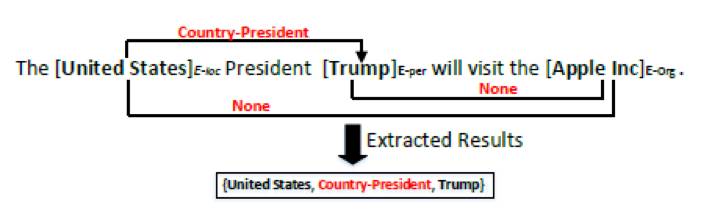
为了实现该任务,作者首先提出了一种新的标注模式,将信息抽取任务转化为序列标注任务。如下图:

标注模式将文本中的词分为两类,第一类代表与抽取结果无关的词,用标签”O”来表示。第二类代表与抽取结果相关的词,这一类词的标签由三部分组成:当前词在 entity中的位置--关系类型--entity 在关系中的角色。作者使用“BIES”(Begin,Inside,End,Single)标注,来表示当前词在 entity 中的位置。而关系类型则是从预先设定的关系类型集中获得的。entity 在关系中的角色信息,用“1”,
“
2”来表示。其中
“
1”表示,当前词属于三元组(Entity1,RelationType,Entity2)的 Entity1,同理”2”表示,当前词属于 Entity2。最后根据标注结果将同种关系类型的两个相邻顺序实体组合为一个三元组。例如:通过标注标签可知,
“
United”与
“
States”组合形成了实体
“
United States”,实体
“
United States”与实体
“
Trump”组合成了三元组 {United States, Country-President, Trump}。
当输入为文本语句的时候,如何自动实现对文本词序列的标注工作呢?接下来作者提出了一个端到端的模型来实现了该工作。模型结构如下图:
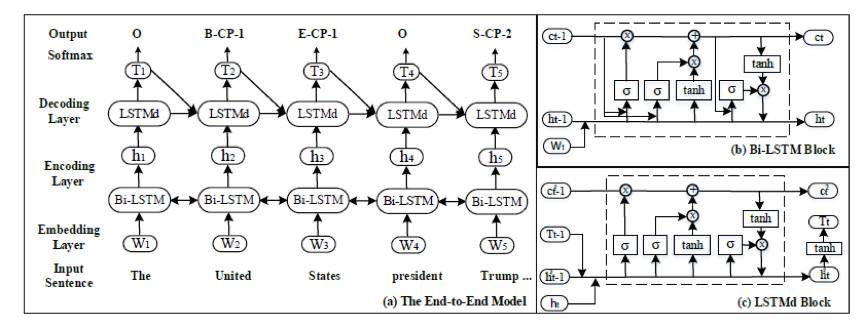
其中:
-
词嵌入层将每个词的 one-hot 表示向量转化为低维稠密的词嵌入向量(维度为 300)
-
Bi-LSTM 编码层(层数为 300)用于获得词的编码信息
-
LSTM 解码层(层数为 600)用于产生标签序列。其中加入偏移损失来增强实体标签的关联性
对话作者
关于新标注模式的适用性,作者认为本论文主要考虑一个词只属于一个三元组的情况,对于三元组重叠问题,即多个三元组都包含同一个词的情况,将在以后的工作中进行探讨。当说到关系数量增多导致标签总数大幅度增加,是否对输出层有影响的问题时,作者向我们解释到,关系数量增多会导致输出层的标签总数增加,对结果会有影响,如果训练集足够丰富本模型任然可以表现出很好的效果。
关于模型与实验,在实验部分作者将本模型(LSTM-LSTM-Bias)与经典模型(LSTM-CRF,LSTM-LSTM)进行比较,根据实验结果作者分析到,CRF 旨在最大化整个标签序列的联合概率,LSTM 能够学习序列元素之间的长距离依赖关系。由于关联标签之间可能彼此具有较长距离,所以基于 LSTM 的解码方式比 CRF 稍好。LSTM-LSTM-Bias 增加了偏置权重以增强特殊标签的作用,并削弱无效标签的影响。因此,它可以获得比常见端对端模型更好地效果。此外,由于关联实体对在文本中的位置是随机的,难以用一个固定结构的模型来增强二者之间的联系,目前想到的思路是通过设计有效地目标函数来增强实体对标签之间的关联性。此外,如何记录已经预测出来的特殊标签信息并用于辅助预测下一个关联标签,目前也没还没想到比较好的思路。
关于模型的应用场景,作者说到,从任务的应用背景回答,该模型可以用于丰富已有的知识图谱资源。如今各种智能化应用,如:自动问答、智能搜索、个性化推荐等,都需要知识图谱的支撑。为推动各领域智能化应用的发展,需要不断的去丰富和完善已有的知识图谱。不断涌现的网络文本数据中存在着大量的知识信息,基于人工整理的方式的成本太高,而且也难以跟上知识出现的步伐。因此,本文方法作为一种从非结构化文本数据中自动化地抽取实体以及他们之间关系进而形成结构化信息的技术,对丰富已有知识资源具有着十分重要的意义。
欢迎点击
「阅读原文」
查看论文:
Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme










