
数据挖掘入门与实战 公众号: datadw
一、项目简介
Credit Card Fraud Detection
https://www.kaggle.com/dalpozz/creditcardfraud
是一个典型的分类问题,欺诈分类的比例比较小,直接使用分类模型容易忽略。在实际应用场景下往往是保证一定准确率的情况下尽量提高召回率。一个典型案例是汽车制造行业,一旦发生一例汽车安全故障,同批次的车辆需要全部召回,造成了巨大的经济损失。
二、数据印象
详细分析过程见在线脚本
在公众号 datadw 回复'欺诈'获取地址。
2.1. 简单数据分析
数据规模:中度规模(对于mac而言)。数据共284807条,后期算法选择需要注意复杂度。
数据特征:V1~V28是PCA的结果,而且进行了规范化,可以做一些统计上的特征学习;Amount字段和Time字段可以进行额外的统计学和bucket统计。
数据质量:无缺失值,数据规整,享受啊。
经验:时间字段最好可以处理为月份、小时和日期,直接的秒数字段往往无意义。
2.2. 探索性数据分析
三、数据预处理
数据已经十分规整了,所以先直接使用基础模型来预测下数据。

L1规划化
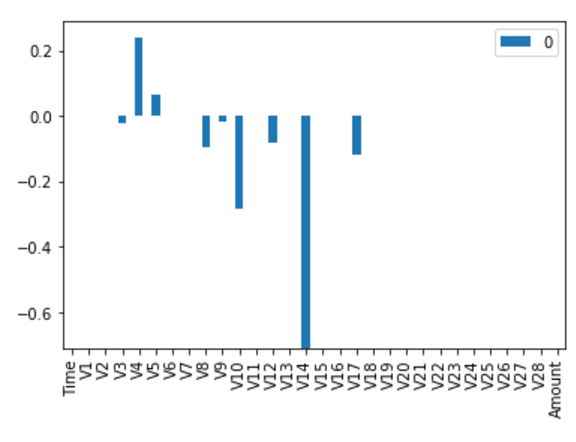
L1规范化的模型
L2规范化
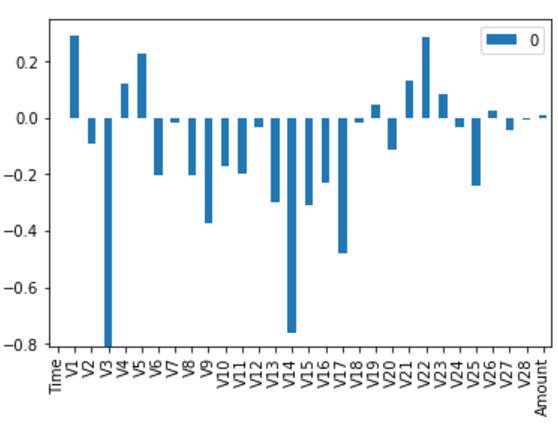
L2规范化的模型
Baseline基础模型:采用线性模型,利用L1的稀疏性,precision和recall均可以达到0.85左右,roc_auc可以达到0.79左右。
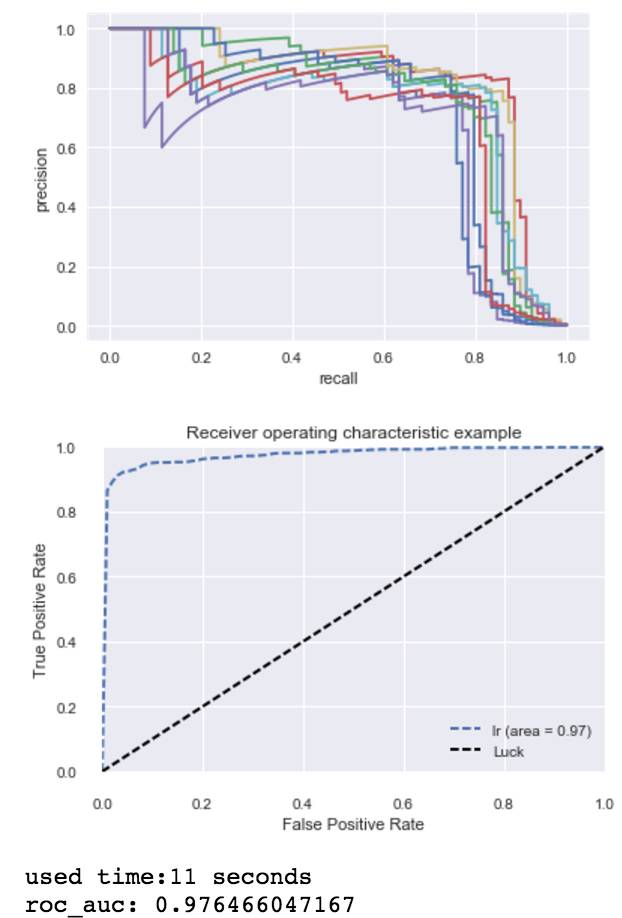
基础模型结果
由上图可见:
Baseline模型的评价metric:
收集更多的数据,不适合这个场景。
改变评价标准:
数据采样处理
- 收集等多数据:不适合这个场景。- 过采样Over-sampling:当数据集较少时,主动添加少类别的数据;
SMOT算法通过插值来实现。不适合本数据集。容易过拟合,运算时间长。- 欠采样Under-sampling:
当数据集足够大时,删除大类别的数据;集成方法`EasyEnsemble/BalanceCascade`
通过将反例放在不同学习器中使用,从全局看不会丢失重要信息。
本案例数据量中等:选用欠采样+EasyEnsemble的方式进行数据处理。
使用im-balanced生成测试数据。
http://contrib.scikit-learn.org/imbalanced-learn/auto_examples/index.html
from imblearn.ensemble import EasyEnsemblen_subsets = X.size * 2 /
(us_X.size) - 1ee = EasyEnsemble(n_subsets=n_subsets)sample_X,
sample_y = ee.fit_sample(X, y)
四、模型印象
模型:
选用easy_ensemble模型来优化。
具体实现代码见在线脚本
在公众号 datadw 回复'欺诈'获取地址。
核心adboost代码如下:

结果如下:
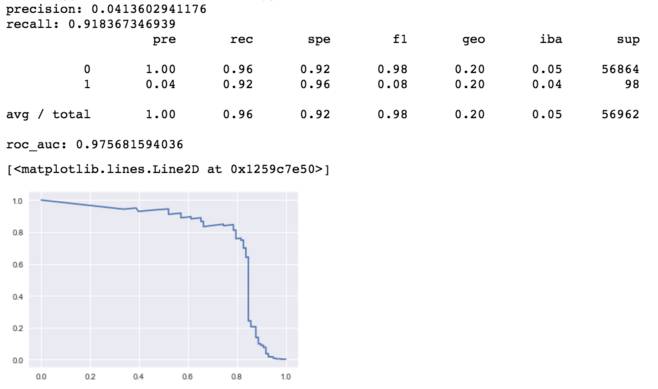
easy_ensembel
对比普通的adboost数据
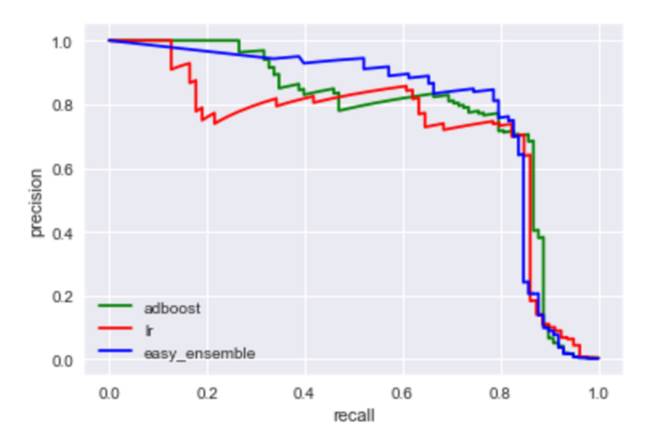
对比图
由上图可知,easy_ensemble提升了平滑度,但是AUC未有提升。
五、特征选择和特征学习
根据数据的统计特征,可以学习一些统计变量。
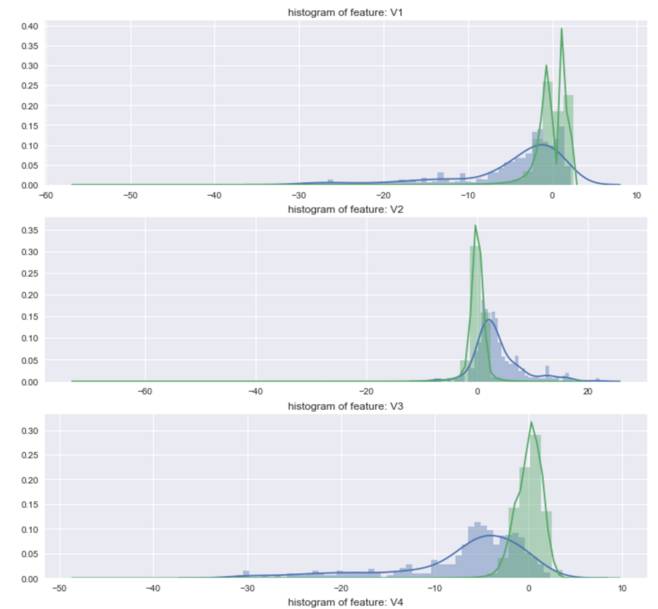
统计学习
增加如下的特征。

六、分析结果
使用SNE分析(常用于非线性可视化分析)来观看一次under_sample的结果。
https://bindog.github.io/blog/2016/06/04/from-sne-to-tsne-to-largevis/
如下图所示
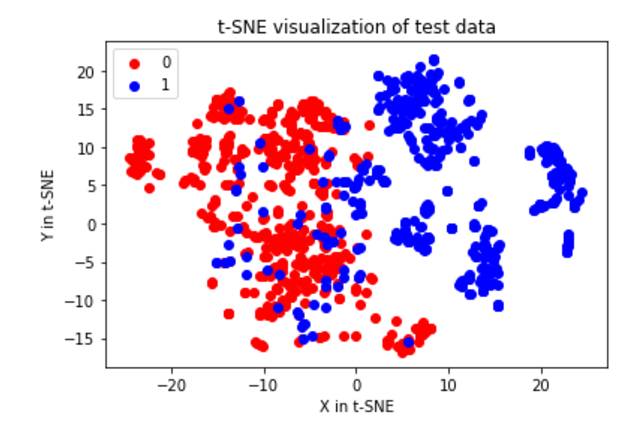
SNE图
由上图可知两种类别的数据是可以区分的,但是部分数据融合在一起,当追求recall较大时,将会误判大量数据。
七、迭代问题
可以优化的方向:
八、表述模型
根据模型的SNE图和数据性可知,数据质量是比较好的。
easy_ensemble模型本身使用了adboost和bagging,每棵tree的复杂度不高,降低了bias;通过bagging,降低了variance。最终得到了较好的P-R图和AUC值。
通过LR模型的稀疏性特征值,可以制作出一个解释性报告。
参考
GBM vs xgboost vs lightGBM
https://www.kaggle.com/nschneider/gbm-vs-xgboost-vs-lightgbm
imbalanced-learn
http://contrib.scikit-learn.org/imbalanced-learn/index.html
Exploratory Undersampling for Class-Imbalance Learning
https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/tsmcb09.pdf
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注










