In the recent Kaggle competition
Dstl Satellite Imagery Feature Detection
our
deepsense.io team won 4th place among 419 teams. We applied a modified
U-Net – an artificial neural network for image segmentation. In this
blog post we wish to present our deep learning solution and share
the lessons that we have learnt in the process with you.
Competition
The challenge was organized by the Defence Science and Technology
Laboratory (Dstl), an Executive Agency of the United Kingdom’s Ministry
of Defence on Kaggle platform. As a training set, they provided 25
high-resolution satellite images representing 1 km
2
areas. The task was to locate 10 different types of objects:
-
Buildings
-
Miscellaneous manmade structures
-
Roads
-
Tracks
-
Trees
-
Crops
-
Waterway
-
Standing water
-
Large vehicles
-
Small vehicles

Sample image from the training set with labels.
These objects were not completely disjoint –
you can find examples with vehicles on roads or trees within crops. The
distribution of classes was uneven: from very common, such as crops
(28% of the total area) and trees (10%), to much smaller such as roads
(0.8%) or vehicles (0.02%). Moreover, most images only had a subset of
classes.
Correctness of prediction was calculated using
Intersection over Union
(IoU, known also as Jaccard Index) between predictions and the ground
truth. A score of 0 meant complete mismatch, whereas 1 – complete
overlap. The score result was calculated for each class separately and
then averaged. For our solution the average IoU was 0.46, whereas for
the winning solution it was 0.49.
Preprocessing
For each image we were given three versions: grayscale, 3-band and 16-band. Details are presented in the table below:
|
Type
|
Wavebands
|
Pixel resolution
|
#channels
|
Size
|
|
grayscale
|
Panchromatic
|
0.31 m
|
1
|
3348 x 3392
|
|
3-band
|
RGB
|
0.31 m
|
3
|
3348 x 3392
|
|
16-band
|
Multispectral
|
1.24 m
|
8
|
837 x 848
|
|
Short-wave infrared
|
7.5 m
|
8
|
134 x 136
|
We resized and aligned 16-band channels to match those from 3-band
channels. Alignment was necessary to remove shifts between channels.
Finally all channels were concatenated into single 20-channels input
image.
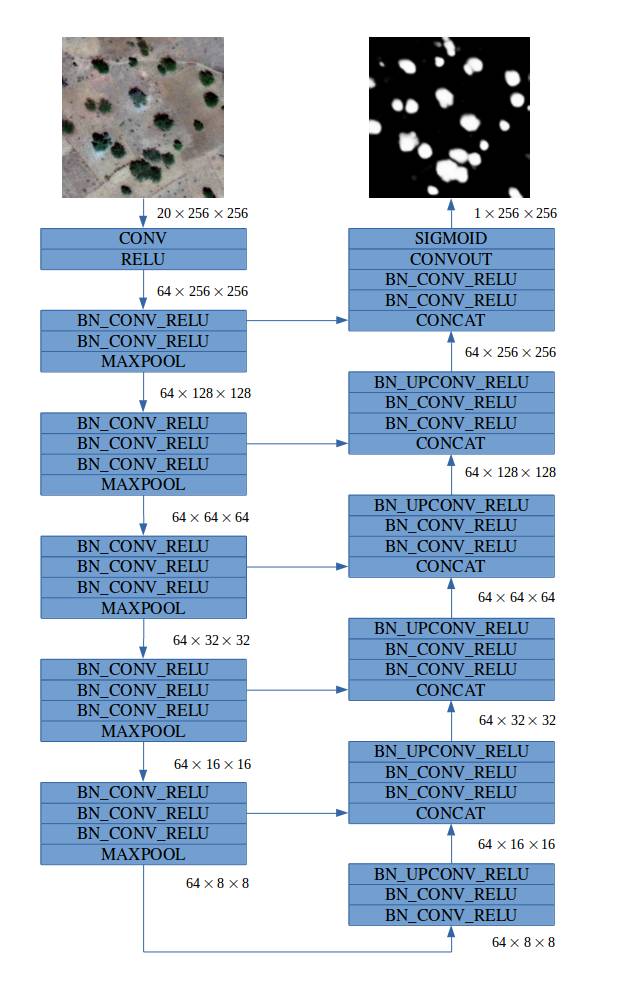
Model
Our fully convolutional model was inspired by the family of
U-Net
architectures,
where low-level feature maps are combined with higher-level ones, which
enables precise localization. This type of network architecture was
especially designed to effectively solve image segmentation problems.
U-Net was the default choice for us and other competitors. If you would
like more insights into architecture we suggest that you read the
original paper
. Our final architecture is depicted below: