本文经机器之心(微信公众号:almosthuman2014)授权转载;
机器之心编译,
参与:吴攀、晏奇;
作者:Alan Morrison、Anand Rao;出自:
pwc.com;
原文链接
:
http://mp.weixin.qq.com/s/yIa1IkBrNdQlxgqfyoCIgg
;
机器学习正在进步,我们似乎正在不断接近我们心中的人工智能目标。语音识别、图像检测、机器翻译、风格迁移等技术已经在我们的实际生活中开始得到了应用,但机器学习的发展仍还在继续,甚至被认为有可能彻底改变人类文明的发展方向乃至人类自身。但你了解现在正在发生的这场变革吗?四大会计师事务所之一的普华永道(PwC)近日发布了多份解读机器学习基础的图表,其中介绍了机器学习的基本概念、原理、历史、未来趋势和一些常见的算法。为便于读者阅读,机器之心对这些图表进行了编译和拆分,分三大部分对这些内容进行了呈现,希望能帮助你进一步阅读。
一、机器学习概览

1. 什么是机器学习?
机器通过分析大量数据来进行学习。比如说,不需要通过编程来识别猫或人脸,它们可以通过使用图片来进行训练,从而归纳和识别特定的目标。
2. 机器学习和人工智能的关系
机器学习是一种重在寻找数据中的模式并使用这些模式来做出预测的研究和算法的门类。机器学习是人工智能领域的一部分,并且和知识发现与数据挖掘有所交集。
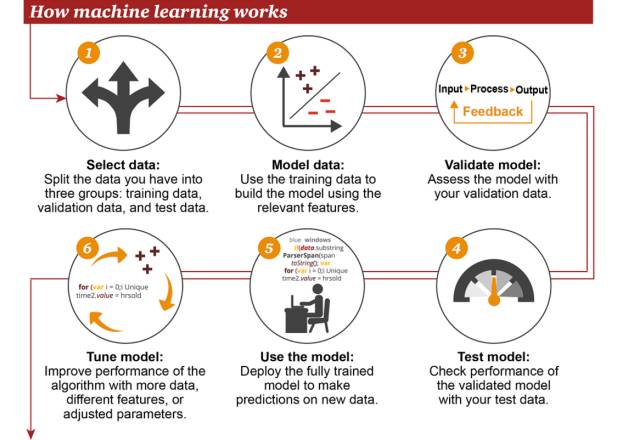
3. 机器学习的工作方式
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
②模型数据:使用训练数据来构建使用相关特征的模型
③验证模型:使用你的验证数据接入你的模型
④测试模型:使用你的测试数据检查被验证的模型的表现
⑤使用模型:使用完全训练好的模型在新数据上做预测
⑥调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能表现
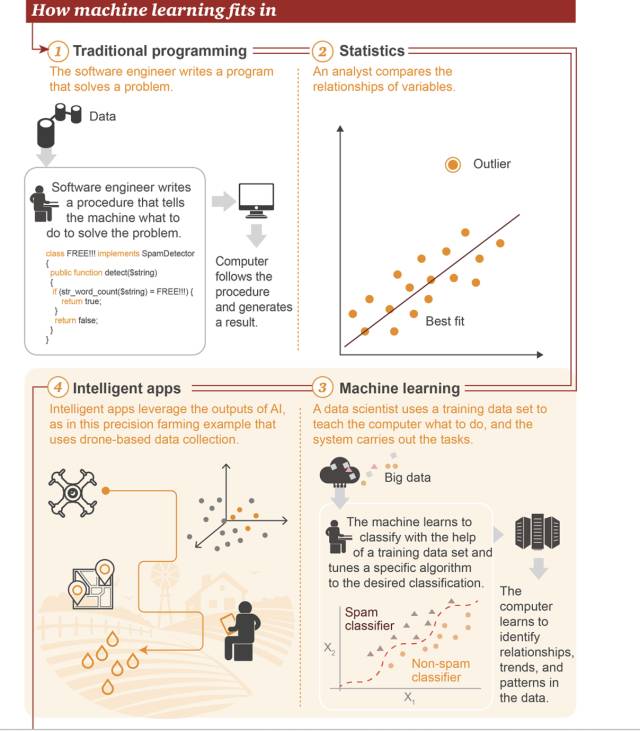
4. 机器学习所处的位置
①传统编程:软件工程师编写程序来解决问题。首先存在一些数据→为了解决一个问题,软件工程师编写一个流程来告诉机器应该怎样做→计算机遵照这一流程执行,然后得出结果
②统计学:分析师比较变量之间的关系
③机器学习:数据科学家使用训练数据集来教计算机应该怎么做,然后系统执行该任务。首先存在大数据→机器会学习使用训练数据集来进行分类,调节特定的算法来实现目标分类→该计算机可学习识别数据中的关系、趋势和模式
④智能应用:智能应用使用人工智能所得到的结果,如图是一个精准农业的应用案例示意,该应用基于无人机所收集到的数据

5. 机器学习的实际应用
机器学习有很多应用场景,这里给出了一些示例,你会怎么使用它?
-
快速三维地图测绘和建模:要建造一架铁路桥,PwC 的数据科学家和领域专家将机器学习应用到了无人机收集到的数据上。这种组合实现了工作成功中的精准监控和快速反馈。
-
增强分析以降低风险:为了检测内部交易,PwC 将机器学习和其它分析技术结合了起来,从而开发了更为全面的用户概况,并且获得了对复杂可疑行为的更深度了解。
-
预测表现最佳的目标:PwC 使用机器学习和其它分析方法来评估 Melbourne Cup 赛场上不同赛马的潜力。
二、机器学习的演化

几十年来,人工智能研究者的各个「部落」一直以来都在彼此争夺主导权。现在是这些部落联合起来的时候了吗?他们也可能不得不这样做,因为合作和算法融合是实现真正通用人工智能(AGI)的唯一方式。这里给出了机器学习方法的演化之路以及未来的可能模样。
1. 五大流派
①符号主义:使用符号、规则和逻辑来表征知识和进行逻辑推理,最喜欢的算法是:规则和决策树
②贝叶斯派:获取发生的可能性来进行概率推理,最喜欢的算法是:朴素贝叶斯或马尔可夫
③联结主义:使用概率矩阵和加权神经元来动态地识别和归纳模式,最喜欢的算法是:神经网络
④进化主义:生成变化,然后为特定目标获取其中最优的,最喜欢的算法是:遗传算法
⑤Analogizer:根据约束条件来优化函数(尽可能走到更高,但同时不要离开道路),最喜欢的算法是:支持向量机
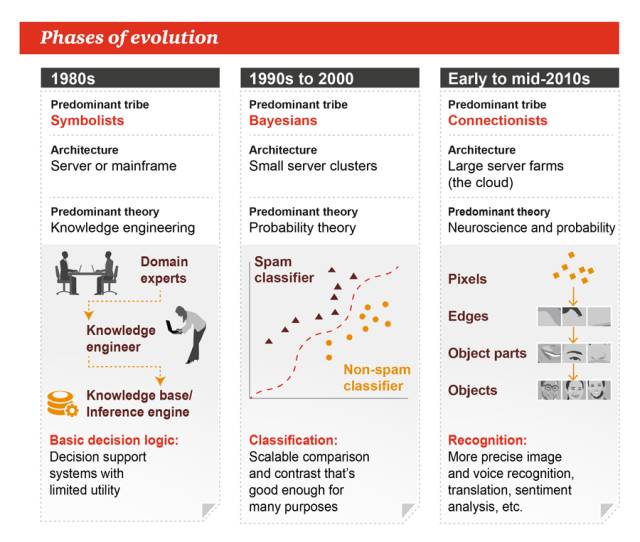
2. 演化的阶段
1980 年代
-
主导流派:符号主义
-
架构:服务器或大型机
-
主导理论:知识工程
-
基本决策逻辑:决策支持系统,实用性有限
1990 年代到 2000 年
-
主导流派:贝叶斯
-
架构:小型服务器集群
-
主导理论:概率论
-
分类:可扩展的比较或对比,对许多任务都足够好了
2010 年代早期到中期
-
主导流派:联结主义
-
架构:大型服务器农场
-
主导理论:神经科学和概率
-
识别:更加精准的图像和声音识别、翻译、情绪分析等
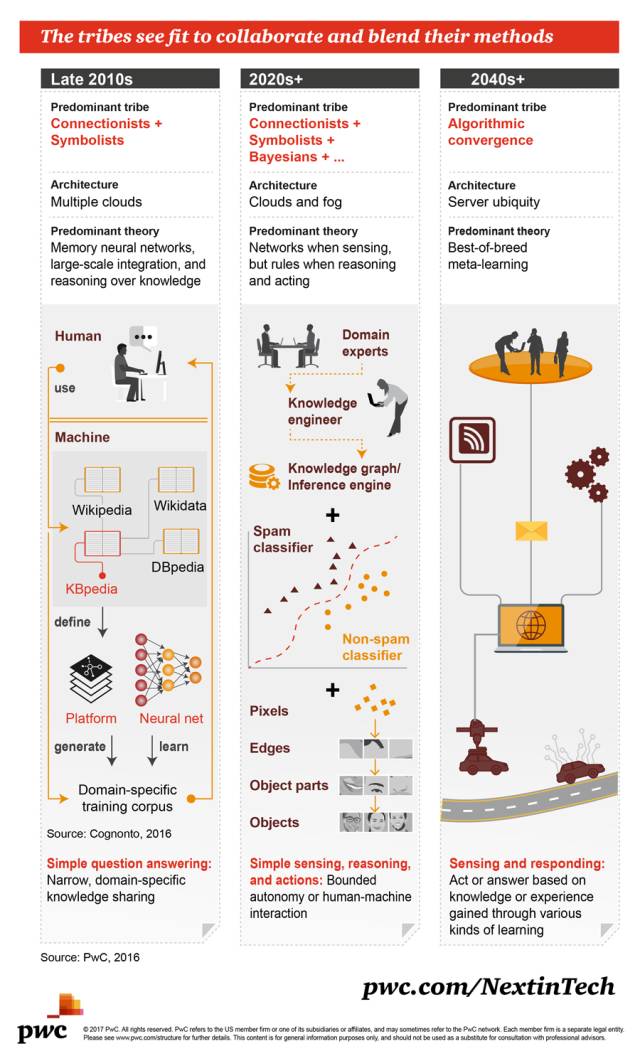
3. 这些流派有望合作,并将各自的方法融合到一起
2010 年代末期
2020 年代+
2040 年代+
三、机器学习的算法
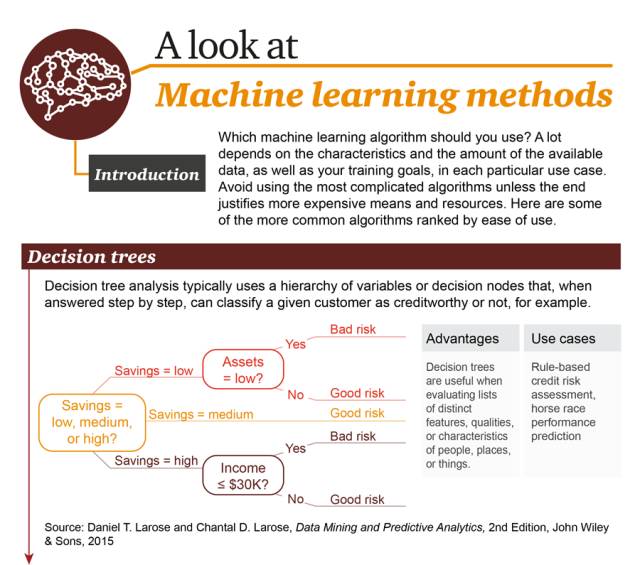
你应该使用哪种机器学习算法?这在很大程度上依赖于可用数据的性质和数量以及每一个特定用例中你的训练目标。不要使用最复杂的算法,除非其结果值得付出昂贵的开销和资源。这里给出了一些最常见的算法,按使用简单程度排序。
1. 决策树(Decision Tree):在进行逐步应答过程中,典型的决策树分析会使用分层变量或决策节点,例如,可将一个给定用户分类成信用可靠或不可靠。
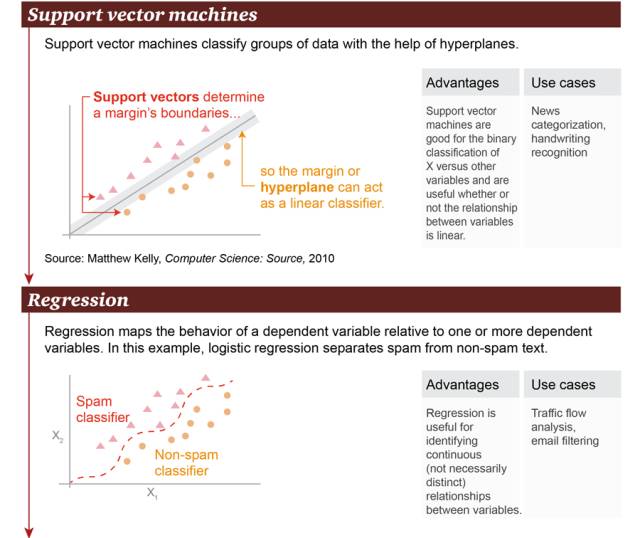
2. 支持向量机(Support Vector Machine):基于超平面(hyperplane),支持向量机可以对数据群进行分类。
3. 回归(Regression):回归可以勾画出因变量与一个或多个因变量之间的状态关系。在这个例子中,将垃圾邮件和非垃圾邮件进行了区分。











