公众号格式受限,最佳体验请到我的知乎看~本文是《大语言模型推理加速技术》系列的第一篇
《大语言模型推理加速技术:计算加速篇》
《大语言模型推理加速技术:模型压缩篇》
《大语言模型推理加速技术:推理框架篇》
自从去年ChatGPT横空出世之后,业界对于大语言模型的热情也愈发高涨,随着模型规模越来越大,它们的计算需求也水涨船高,大模型部署和所需的资源量也让很多团队望而却步:毕竟可以拿社区开源的预训练模型跳过训练的过程,但是部署大模型推理是无法避开的流程。本系列旨在简单讨论几个业界生产环境可用的大模型推理技术,并分析对比几个主流的推理框架。
由于各大公司和学术团队都在“卷”大模型,大模型新技术层出不穷,本系列只能保证当前的信息有效性(2023年11月初)。另外由于本文是从工程角度出发,只会介绍工业界可落地的技术,一些前沿的学术成果可能并不包含在内,敬请谅解。
简介
Transformer和Attention
当前主流的大模型都是基于2017年谷歌团队提出的Transformer架构,其核心是注意力(Attention)机制,简单来说就是计算softmax(qk^T)*v:
def attention(q_input, k_input, v_input):
q = self.Q(q_input)
k = self.K(k_input)
v = self.V(v_input)
return softmax(q * k.transpose()) * v
其中Q,K,V是模型的三个矩阵。对当前主流的Decoder-only模型来说,推理过程分为两个阶段:
1.
context phase也叫prefill phase:需要计算整个prompt的自注意力,q_input, k_input, v_input大小都为[seq_len, emb_dim],即整个prompt的embedding,context phase只需要进行一次,生成第一个token。
2.
generation phase或decoding phase:每生成一个token就要计算一次,其中q_input为[1, emb_dim],代表当前token的embedding,k_input, v_input为[n, emb_dim]代表所有前文的embedding,这个阶段计算的是当前token和所有前文的注意力。
Attention计算占据了模型推理阶段的绝大部分资源,要了解本文介绍的优化技巧,只需要了解Attention的计算过程就足够了。由于本文更多关注工程细节,对模型的设计只是一笔带过,有兴趣的读者可自行了解完整的Transformer相关信息。
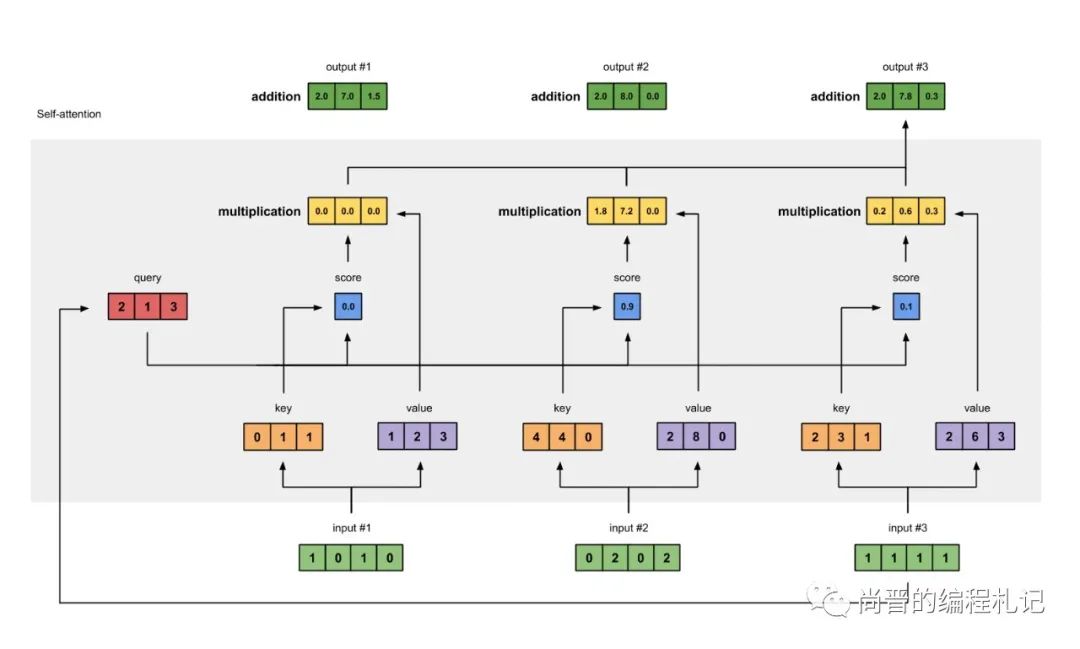
Attention计算,来自Raimi Karim的
Towards Data Science
文章
瓶颈
想知道如何优化,我们首先要知道模型的计算慢在哪里。
1.
大模型通常需要处理很长的输入和输出,由于当前token需要和前面所有的token进行attention计算,随着seq_len和n的增加,模型需要的计算的矩阵尺寸也越来越大。
2.
在生成阶段,每个token的生成都依赖前面所有的计算,只能一个一个token生成,无法并发计算。
简单来说,推理瓶颈就在于Attention的计算是一个
O(N^2)的操作且无法并发
。本文所介绍的技术都是针对以上两个瓶颈进行优化。
优化目标
加速优化一般有两个目标,一个是更低的
延迟
(Latency),一个是更高的
吞吐量
(Throughput),其中延迟是指单个请求返回的时间,而吞吐量是一定时间内处理请求的总量。这两者有时是不可兼得的。举个例子,如果我们把一个模型切分成多个小模型进行分布式计算(张量并行),我们可以把单个请求的速度提升数倍(延迟下降),但是由于有通信和聚合的成本,系统处理单个请求的资源消耗量变多了,导致系统的吞吐量也会下降。有些加速技术只会针对其中一种目标,我们后面会详细介绍。
在本系列中,推理优化技术分为两大类:
计算加速
和
模型压缩
。计算加速,通过改进算法和硬件利用率来提高效率,而不影响模型的输出质量,本质上是让模型“算得更快”。而模型压缩则是改变模型结构,减少部分计算(比如稀疏Attention)或降低计算精度(比如量化),换来更快的推理速度和更低的资源消耗,但可能会影响模型的输出质量,本质上是让模型“算得更少”。本文作为系列的第一篇,只介绍计算加速技术,我们将在下一篇文章中介绍模型压缩技术。
计算加速
任何计算的本质都是CPU/GPU执行一系列的指令,在模型结构固定的情况下,我们能做的优化无非就是以下三种:
1.
减少需要执行的指令数量,即减少不必要的或重复的运算。
2.
充分利用硬件的并发度,要么是让单条指令可以一次处理多条数据(SIMD),要么是利用CPU和GPU的多核心机制,同时执行多条指令。
3.
加速内存IO速度。利用缓存局部性加速内存读取指令的执行速度,或者减少不必要的内存读写。
前两种我们称之为
计算侧优化
,后一种我们称之为
内存IO优化
。
计算侧优化
KVCache
在每一个decoding phase中,我们需要计算当前token和之前所有已生成token的attention,因此需要计算所有token的k和v向量,但是前面的token的kv值在每轮decoding中都被重复计算了,因此我们可以把它们存下来,存成两个[seq_len-1, inner_dim]的Tensor,在每轮计算中只需要计算当前token的kv值即可。
KVCache是最简单直接的优化手段,一般模型的默认实现都会自带KVCache,因此并不需要我们额外实现,以Huggingface Transformers库为例,我们只需要在配置中设置use_cache=True即可。
这里还想吐槽一下,一般我们在工程中要到的cache也都是基于hash_map这种kv map的,最开始我还以为KVCache也是基于map的复杂数据结构,没想到只是简单的两个Tensor就实现了。
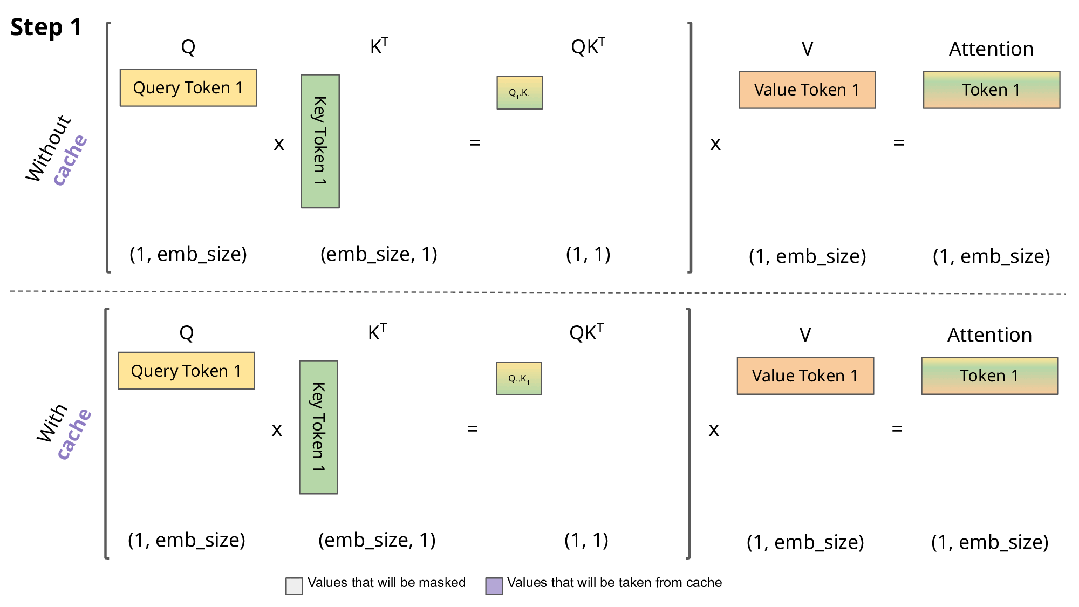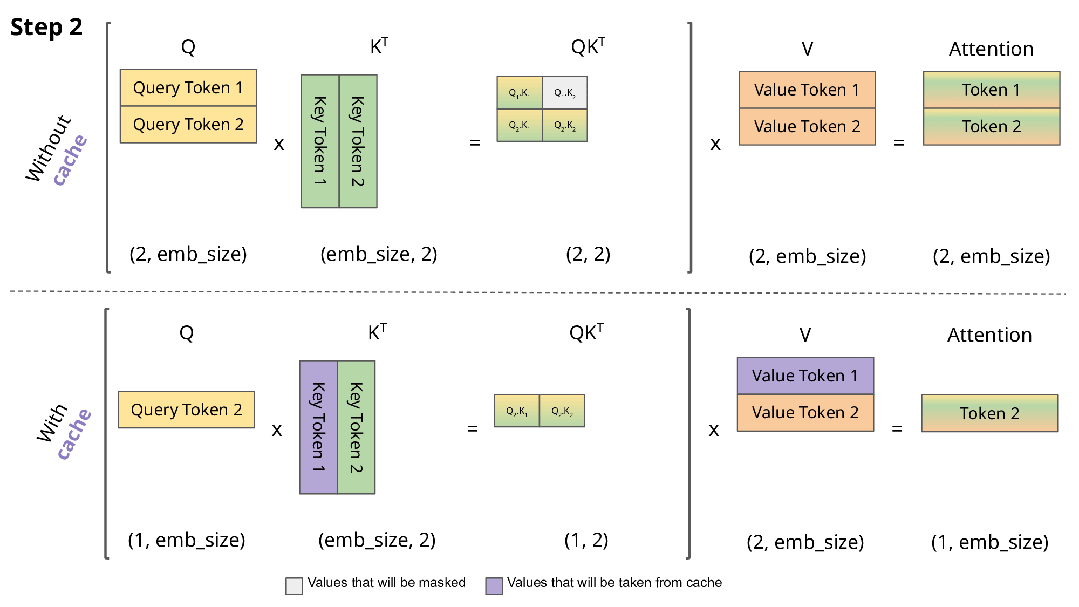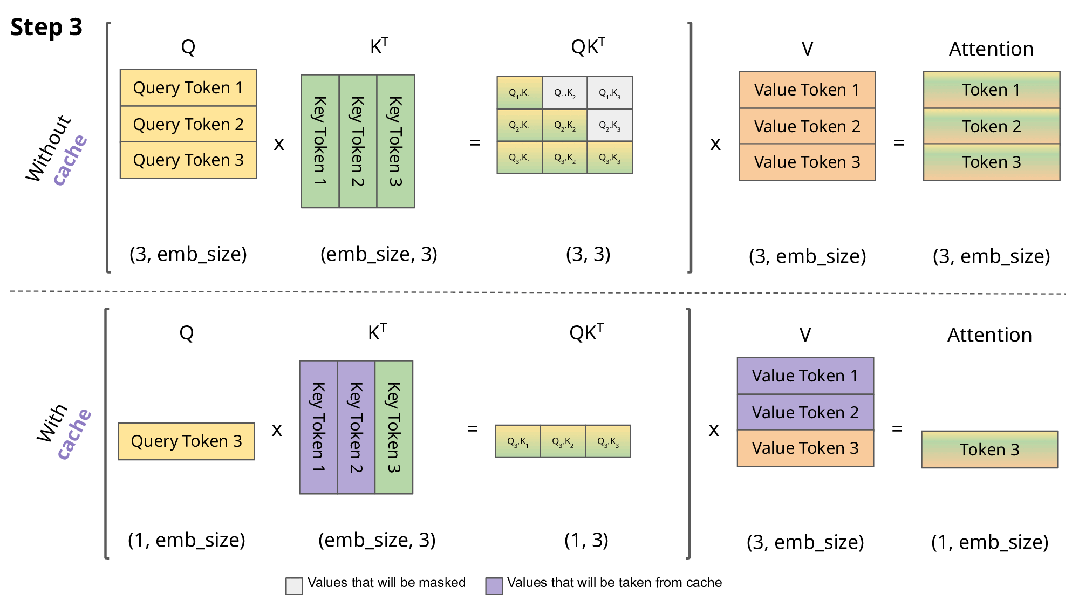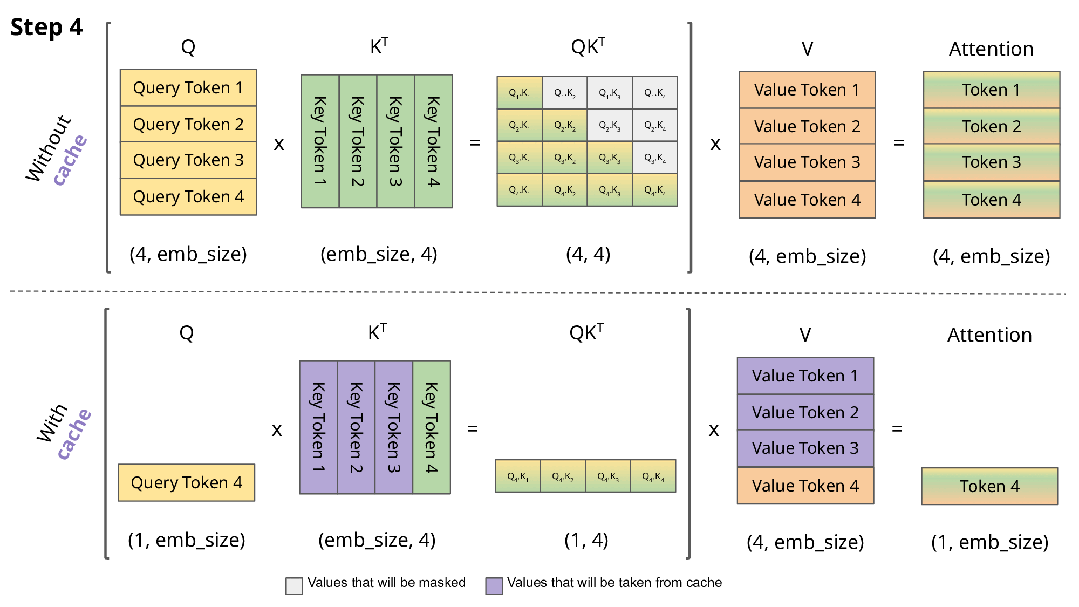
KVCache图解,来自Joao Lages的
Medium文章
Kernel优化和算子融合
在NVIDIA GPU环境上,我们通过CUDA Kernel来执行大部分运算,矩阵乘法(GEMM),激活函数,softmax等,一般老说每个操作都对应一次kernel调用。但是每次kernel调用都有一些额外开销,比如gpu和cpu之间的通信,内存拷贝等,因此我们可以将整个Attention的计算放进同一个kernel实现,省略这些开销,在kernel中也可以实现一些Attention专用的优化。比如Facebook的xformers库就为各种Attention变种提供了高效的CUDA实现。主流的推理库也基本都自带了高效的Kernel实现。
除了手写的Kernel外,模型编译器也可以提供类似的优化机制,编译器将模型结构转换为其中间格式然后进行一系列的优化,比如我们提到的算子融合。虽然在CUDA这种主流平台上编译器的优化效果不一定比得上专用的Kernel实现,但是多平台的通用性是编译器的一大优势,比如TVM团队的MLC-LLM和微软主导的ONNX常被用来在手机等边缘设备上运行大模型。
分布式推理
在大模型的训练和推理过程中,我们有以下几种主流的分布式并行方式:
·
数据并行(DataParallel):将模型放在多个GPU上,每个GPU都包含完整的模型,将数据集切分成多份,每个GPU负责推理一部分数据。
·
流水线并行(PipelineParallel):将模型纵向拆分,每个GPU只包含模型的一部分层,数据在一个GPU完成运算后,将输出传给下一个GPU继续计算。
·
张量并行(TensorParallel):将模型横向拆分,将模型的每一层拆分开,放到不同的GPU上,每一层的计算都需要多个GPU合作完成。
流水线并行一般是一台GPU内存无法放下整个模型的妥协之举,各层之间仍然是顺序运行的,并不能加速模型的计算。而另外两种并行则可以加速模型的推理。推理阶段的数据并行非常简单,因为不需要像训练一样聚合推理结果更新参数,因此我们只需要将模型单独部署在多个GPU上推理即可。而张量并行一般使用NVIDIA的Megatron库,模型内部结构改为使用Megatron的ColumnParallelLinear、RowParallelLinear、ParallelMLP和ParallelAttention等结构实现。
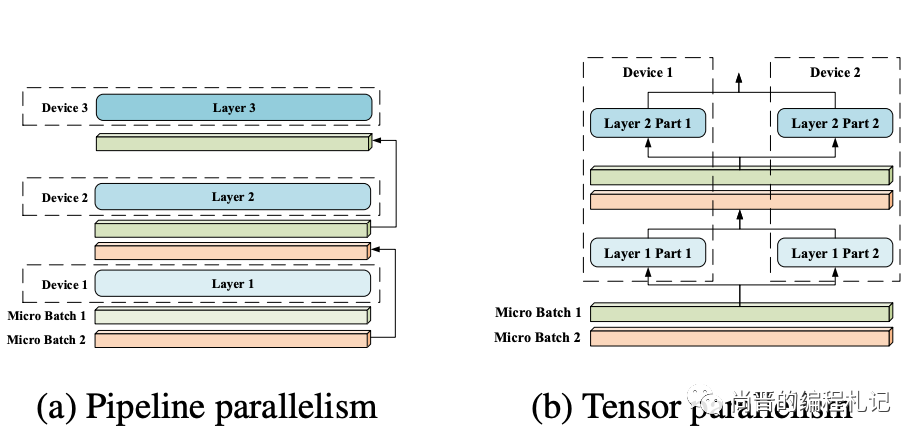
流水线并行和张量并行,来自Sequence Parallelism的
paper
内存IO优化
在做性能优化时,我们除了要考虑单纯计算的速度,也要考虑内存访问的速度。一方面,和CPU缓存一样,GPU也有类似L1、L2这样的分级缓存(SRAM和HBM),级数越低的缓存大小越小,访问速度越快,因此我们在优化模型推理时也要考虑内存访问的局部性(Cache Locality)。另一方面,KVCache随着batch size和seq len的增加而扩张,在推理过程中会占据超过30%的内存,可能会出现因为内存不够用而限制最大并发度的问题。在并发度较高或者输入输出长度较大时,内存访问反而可能成为计算的瓶颈,而非CPU/GPU的计算量。
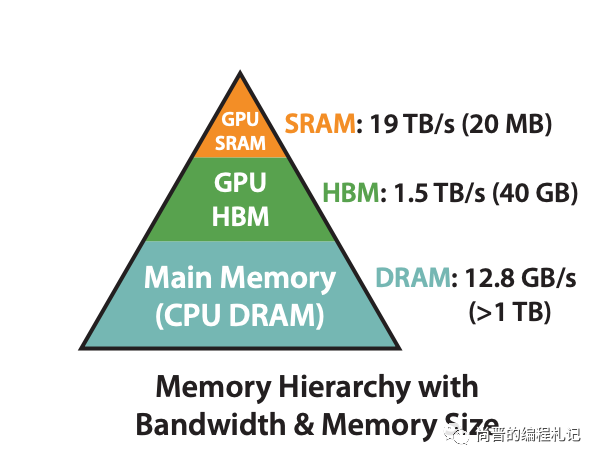
GPU的分级缓存,来自Flash Attention的paper
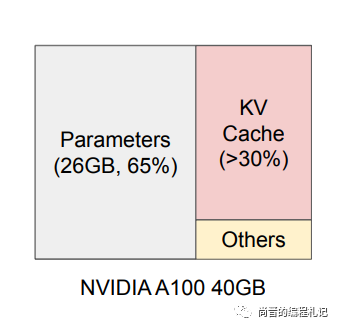
推理时的内存占用,来自vllm的paper
Flash Attention
在进行Attention计算时,QKV都是非常大的矩阵,直接进行矩阵乘法运算是非常缓存不友好的。因此我们可以考虑对矩阵进行分块乘法,每次只计算一个小的block,保证block可以放进SRAM而非HBM中。实际上这是一个很经典的思路,大部分的矩阵乘法kernel也是这样实现的。
而FlashAttention则更进一步,我们观察到Attention计算分为三步:
1.
从HBM读取QK,计算S = QK^T,将S写回HBM
2.
从HBM读出S,计算P = softmax(S),将P写回HBM
3.
从HBM读出P和V,计算O=PV,将O写回HBM
我们需要在整个计算过程中HBM读三次写三次,有没有办法只读写一次呢?如果Attention只是简单的矩阵乘法,可以通过分块计算的方法避免写回HBM,但是由于softmax的存在,我们无法直接这样做。因为softmax需要计算矩阵中每一行元素的最大值,所以我们必须等待所有分块遍历完成后才能计算下一步。
FlashAttention巧妙地利用了类似于动态规划的技巧,实现了online softmax,可以在一个循环中计算出一个分块的最终结果。FlashAttention算法在遍历过程中需要不断地对中间结果进行重新计算,但是得益于整个过程不需要读HBM,在增大了计算量的情况下仍然可以提升运算速度。
关于Flash Attention的完整介绍和数学推导,我推荐华盛顿大学的这个
课件
,里面非常直观地解释了Flash Attention背后的想法和推导过程。用户可以通过使用Flash Attention的库调用它的kernel,PyTorch官方也对Flash Attention提供了官方支持。
Flash Decoding
由于Flash Attention优化的是大矩阵乘法,矩阵越大优化效果应当越好。但是在在线推理的场景中,输入的batch size为1,Q矩阵实际上是一个向量而非矩阵,在这种场景下,Flash Attention无法充分地利用GPU的并发能力。而Flash Decoding通过以seq_len为维度并发,即将K和V分成多个部分,并发地与Q相乘而解决了这个问题。
与Flash Attention适合离线训练和批量推理不同,Flash Decoding在在线单次推理且上下文长度较长时效果更好。用户可以通过FlashAttention库或者xFormers的attention kernel来使用Flash Decoding。

Flash decoding示例
Continuous Batching
在批量推理过程中我们一般使用固定的Batch Size,将多个请求Batch起来一起推理。在分配KVCache时,我们需要分配两个shape为[batch_size, seq_len, inner_dim]的tensor,但是不同的请求可能有不同输入和输出长度,而且我们无法预知最终的输出长度,无法固定seq_len,因此我们通常分配[batch_size, max_seq_len, inner_dim]这样的shape,保证所有请求的cache都放得下。
但是这样的分配策略有两个问题:
1.
不是每个请求都可以达到max_seq_len,因此KVCache中很多的内存都被浪费掉了
2.
即使一些请求输出长度很短,它们仍然需要等待输出较长的请求结束后才能返回
这种固定的Batch策略叫做静态Batching(Static Batching),为了解决这个问题,
Orca










