

作者 张俊红
本文为 CDA 志愿者张俊红原创作品,转载需授权
01|背景介绍:
前两篇推文里面涉及的目标爬取对象都比较简单,要么是普通的静态网页图片,要么是有规律的url参数,通过遍历参数就可以爬取不同的页面内容。还有一种目标爬取对象不属于上面任何一种。
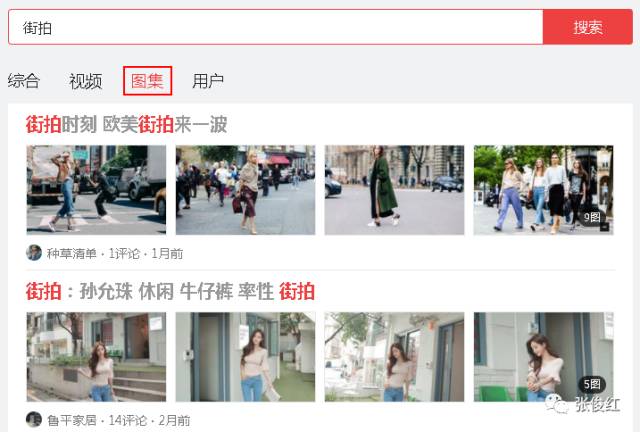
我们要爬取每个图集里面的每张图片,就是下图这样子。

我们先想一下如果是人为的去保存每个图集里面的每张照片,我们会怎么做?
应该是先找到图集的合集,然后点进去每个图集,再然后对该图集里面的每张图片点击保存到本地,依次对每一个图集执行相同的操作。
如果用程序去实现也需要经历相同的步骤,只不过不用人为去点击每一个图集,人为的去保存每一张图片。
所以接下来我们就先去找找到每个图集(即每个图集对应的url),但是我们在进行元素审查的时候并未发现每个图集的url,这是为什么呢?这是因为该网页是通过AJAX形式进行加载的,那么什么是AJAX呢,这就是我们今天要介绍的第三种目标爬取对象。
02|AJAX介绍:
1、什么是AJAX
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。
传统的网页(不使用 AJAX)如果需要更新内容,必需重载整个网页面。
AJAX 不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。
2、AJAX是怎么工作的

先创建一个XMLHttpRequest对象,然后发送HttpRequest请求给服务器,服务器加载这个请求然后生成一个response给浏览器,浏览器使用JavaScript加载浏览器传回来的数据,然后进行页面更新。
3、AJAX实例
使用 AJAX 修改该文本内容

下图为点击按钮以后出现的结果:

实例解析:
分割线之前是一个script,在script里面定义一个函数,即AJAX执行的脚本。
分割线之后的部分是 AJAX 应用程序,包含一个 div 和一个按钮。div 部分用于显示来自服务器的信息。当按钮被点击时,它负责调用script里面名为 loadXMLDoc() 的函数,即执行脚本程序。这里说明JavaScript里面的AJAX脚本是需要用一个动作去驱动的。
03|开始爬取数据:
1、爬取目标确立
要爬取今日头条街拍里面每个图集里面的每张图片。
2、分析目标网页
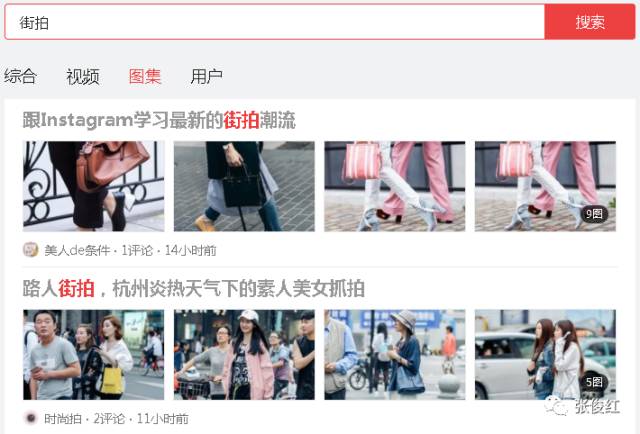
在背景介绍里面我们已经讲过,要想爬取每个图集里面的每张图片,我们需要先点进去每个图集(即先获取每个图集的url),或者是所有图集的所有照片都在一个页面,然后依次保存每张照片即可。
但是在进行元素审查(Elements)的时候,并没有我们想要的每个图集的url,也没有我们想要的所有图集的所有图片的url。(只有每个图片对应图片的缩略图的url)
所以我们猜想每个图集的url应该是采用AJAX请求的,当我们点击每个图集时,会触发JavaScript运行AJAX脚本加载该图集里面的每张图片。所以我们去查看一下XHR(AJAX对象)里面是否包含每个图集对应的url,发现果真在XHR中。
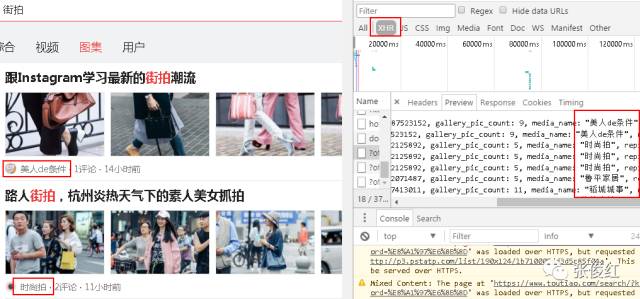
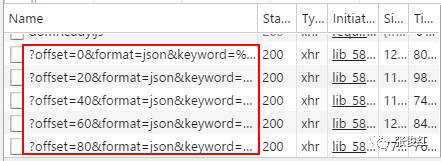
我们在下拉页面的时候发现XHR对象里面不停滴有新的对象出现,点击去以后发现也有图集对应的url,说明整个页面的图集url包含在不同的offset中。
3、爬取流程确立
先向浏览器发送请求,获取回应,并在XHR中遍历获取每个offset中包含的图集的url的集合,然后遍历解析每个图集的url,在获得每个图集url的解析的内容中获取每张图片,然后保存图片,整个爬虫完成。
4、开始编写程序
#导入相关库
import json
from urllib.parse
import urlencode
import requests
from bs4 import BeautifulSoup
import refrom json.decoder
import JSONDecodeError
#创建两个空list
article_url=[]
finally_image=[]
#用来生成offset
for offset in range(0,200,20):
data = {
'autoload': 'true',
'count': 20,
'cur_tab': 3,
'format': 'json',
'keyword': "街拍",
'offset': offset,#可变参数
}
params = urlencode(data)#urlencode将字典形式转换成url请求参数(字符串形式)
base = 'http://www.toutiao.com/search_content/'
url = base + '?' + params#解析offset
response=requests.get(url)
text=response.text
data = json.loads(text)#将字符串解码成字典形式
#取出每一个offset对应的图集url的集合
for item in data['data']:#获取字典data中keys为“data”对应的值
article_url.append(item['article_url'])
#依次取出每一个图集对应的url并进行解析
for url1 in article_url:
response1 = requests.get(url1)
html=response1.text
soup = BeautifulSoup(html, 'lxml')
images_pattern = re.compile('var gallery = (.*?);', re.S)
result = re.search(images_pattern, html)
data = json.loads(result.group(1))
sub_images = data['sub_images']
images = [item.get('url') for item in sub_images]#创建一个列表,for循环之前的符号是要生成的列表元素
#依次取出该图集里面的每一章图片对应的url,并将其放入list中
for image in images:
finally_image.append(image)
finally_image

推荐阅读
听说你最擅长“拖”,你“拖”得过Excel吗?
数据科学优质课程推荐#2:统计入门课程篇
歌手外科和猴姑,大数据告诉你白百何出轨后谁最惨
想学习数据科学?我们整理了一份优质编程入门课程清单
数据科学家在美国仍然是最热门工作的3大原因
一个优秀数据分析师的准则
Python 实现一个火车票查询的工具
干货 | 携程实时用户行为系统实践
数据分析证明最靠谱的电影评分网站不是 IMDB, 也不是烂番茄,而是...
那些年,写 Python 犯过的错误
我用6.5万条公开数据分析了一下人民眼中的人民的名义
如何获得你的第一份数据科学领域的工作?
北京空气质量数据可视化
几个提高工作效率的Python内置小工具
Python 自然语言处理《釜山行》人物关系
函数 | 这8组Excel函数,帮您解决工作中80%的难题
国外公司是如何挖掘社交媒体数据的?
大数据舆情情感分析,如何提取情感并使用什么样的工具?(贴情感标签)
【干货】Pandas速查手册中文
四步搭建企业服务数据分析体系
【干货】找不到适合自己的编程书?我自己动手写了一个热门编程书搜索网站(附PDF书单)











