在本教程中,作者对现代机器学习算法进行一次简要的实战梳理。虽然类似的总结有很多,但是它们都没有真正解释清楚每个算法在实践中的好坏,而这正是本篇梳理希望完成的。因此本文力图基于实践中的经验,讨论每个算法的优缺点。而机器之心也在文末给出了这些算法的具体实现细节。
对机器学习算法进行分类不是一件容易的事情,总的来看,有如下几种方式:生成与判别、参数与非参数、监督与非监督等等。
然而,就实践经验来看,这些都不是实战过程中最有效的分类算法的方式。因为对于应用机器学习而言,开发者一般会在脑海中有一个最终目标,比如预测一个结果或是对你的观察进行分类。
因此,我们想介绍另一种对算法进行分类的路数,其基于机器学习任务来分类。
没有免费午餐定理
在机器学习中,有个定理被称为「没有免费的午餐」。简而言之,就是说没有一个算法可以完美解决所有问题,而且这对于监督学习(即对预测的建模)而言尤其如此。
举个例子,你不能说神经网络就一定任何时候都比决策树优秀,反过来也是。这其中存在很多影响因素,比如你数据集的规模和结构。

所以,当你使用一个固定的数据测试集来评估性能,挑选最适合算法时,你应该针对你的问题尝试多种不同的算法。
当然,你所使用的算法必须要适合于你试图解决的问题,这也就有了如何选择正确的机器学习任务这一问题。做个类比,如果你需要打扫你的房子,你可能会用吸尘器、扫帚或者是拖把,但是你绝不会掏出一把铲子然后开始挖地。
机器学习任务
在本次梳理中,我们将涵盖目前「三大」最常见机器学习任务:
-
回归方法
-
分类方法
-
聚类方法
说明:
1、回归方法
回归方法是一种对数值型连续随机变量进行预测和建模的监督学习算法。使用案例一般包括房价预测、股票走势或测试成绩等连续变化的案例。
回归任务的特点是标注的数据集具有数值型的目标变量。也就是说,每一个观察样本都有一个数值型的标注真值以监督算法。
1.1 线性回归(正则化)
线性回归是处理回归任务最常用的算法之一。该算法的形式十分简单,它期望使用一个超平面拟合数据集(只有两个变量的时候就是一条直线)。如果数据集中的变量存在线性关系,那么其就能拟合地非常好。
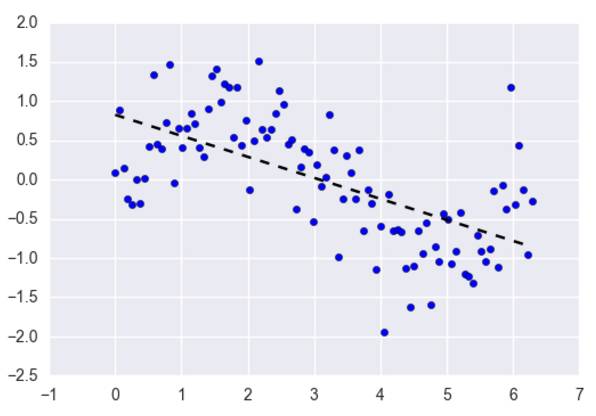
在实践中,简单的线性回归通常被使用正则化的回归方法(LASSO、Ridge 和 Elastic-Net)所代替。正则化其实就是一种对过多回归系数采取惩罚以减少过拟合风险的技术。当然,我们还得确定惩罚强度以让模型在欠拟合和过拟合之间达到平衡。
1.2 回归树(集成方法)
回归树(决策树的一种)通过将数据集重复分割为不同的分支而实现分层学习,分割的标准是最大化每一次分离的信息增益。这种分支结构让回归树很自然地学习到非线性关系。
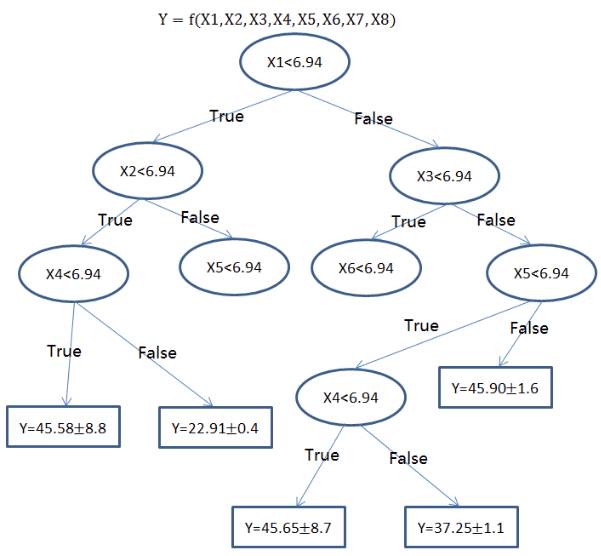
集成方法,如随机森林(RF)或梯度提升树(GBM)则组合了许多独立训练的树。这种算法的主要思想就是组合多个弱学习算法而成为一种强学习算法,不过这里并不会具体地展开。在实践中 RF 通常很容易有出色的表现,而 GBM 则更难调参,不过通常梯度提升树具有更高的性能上限。
-
随机森林 Python 实现:http://scikit-learn.org/stable/modules/ensemble.html#random-forests
-
随机森林 R 实现:https://cran.r-project.org/web/packages/randomForest/index.html
-
梯度提升树 Python 实现:http://scikit-learn.org/stable/modules/ensemble.html#classification
-
梯度提升树 R 实现:https://cran.r-project.org/web/packages/gbm/index.html
1.3 深度学习
深度学习是指能学习极其复杂模式的多层神经网络。该算法使用在输入层和输出层之间的隐藏层对数据的中间表征建模,这也是其他算法很难学到的部分。
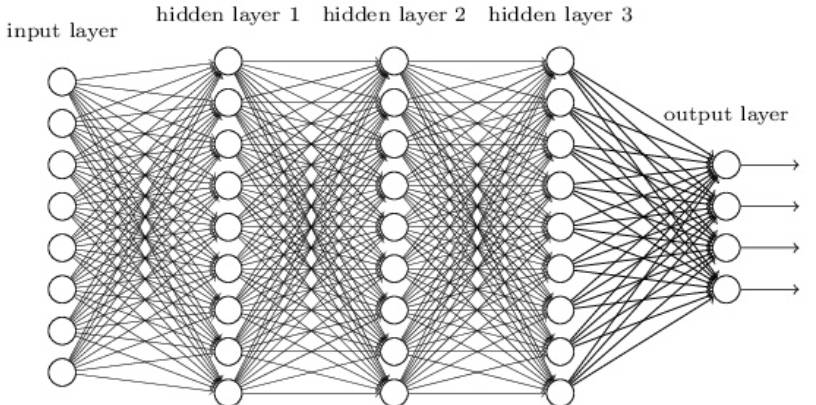
深度学习还有其他几个重要的机制,如卷积和 drop-out 等,这些机制令该算法能有效地学习到高维数据。然而深度学习相对于其他算法需要更多的数据,因为其有更大数量级的参数需要估计。
-
优点:深度学习是目前某些领域最先进的技术,如计算机视觉和语音识别等。深度神经网络在图像、音频和文本等数据上表现优异,并且该算法也很容易对新数据使用反向传播算法更新模型参数。它们的架构(即层级的数量和结构)能够适应于多种问题,并且隐藏层也减少了算法对特征工程的依赖。
-
缺点:深度学习算法通常不适合作为通用目的的算法,因为其需要大量的数据。实际上,深度学习通常在经典机器学习问题上并没有集成方法表现得好。另外,其在训练上是计算密集型的,所以这就需要更富经验的人进行调参(即设置架构和超参数)以减少训练时间。
1.4 最近邻算法
最近邻算法是「基于实例的」,这就意味着其需要保留每一个训练样本观察值。最近邻算法通过搜寻最相似的训练样本来预测新观察样本的值。
而这种算法是内存密集型,对高维数据的处理效果并不是很好,并且还需要高效的距离函数来度量和计算相似度。在实践中,基本上使用正则化的回归或树型集成方法是最好的选择。
2、分类方法
分类方法是一种对离散型随机变量建模或预测的监督学习算法。使用案例包括邮件过滤、金融欺诈和预测雇员异动等输出为类别的任务。
许多回归算法都有与其相对应的分类算法,分类算法通常适用于预测一个类别(或类别的概率)而不是连续的数值。
2.1 Logistic 回归(正则化)
Logistic 回归是与线性回归相对应的一种分类方法,且该算法的基本概念由线性回归推导而出。Logistic 回归通过 Logistic 函数(即 Sigmoid 函数)将预测映射到 0 到 1 中间,因此预测值就可以看成某个类别的概率。
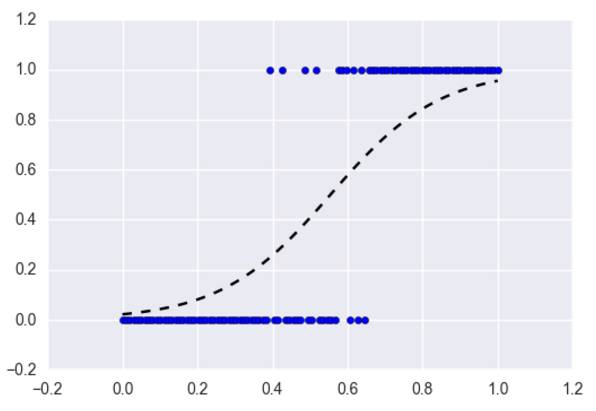
该模型仍然还是「线性」的,所以只有在数据是线性可分(即数据可被一个超平面完全分离)时,算法才能有优秀的表现。同样 Logistic 模型能惩罚模型系数而进行正则化。
2.2 分类树(集成方法)
与回归树相对应的分类算法是分类树。它们通常都是指决策树,或更严谨一点地称之为「分类回归树(CART)」,这也就是非常著名的 CART 的算法。
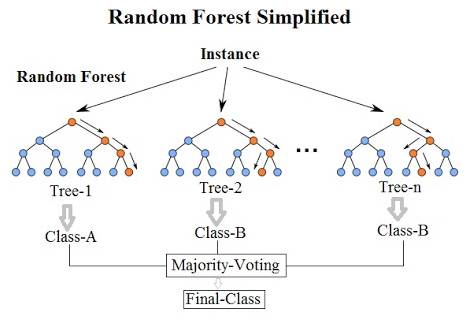
简单的随机森林
-
随机森林 Python 实现:http://scikit-learn.org/stable/modules/ensemble.html#regression
-
随机森林 R 实现:https://cran.r-project.org/web/packages/randomForest/index.html
-
梯度提升树 Python 实现:http://scikit-learn.org/stable/modules/ensemble.html#classification
-
梯度提升树 R 实现:https://cran.r-project.org/web/packages/gbm/index.html
2.3 深度学习
深度学习同样很容易适应于分类问题。实际上,深度学习应用地更多的是分类任务,如图像分类等。
2.4 支持向量机
支持向量机(SVM)可以使用一个称之为核函数的技巧扩展到非线性分类问题,而该算法本质上就是计算两个称之为支持向量的观测数据之间的距离。SVM 算法寻找的决策边界即最大化其与样本间隔的边界,因此支持向量机又称为大间距分类器。
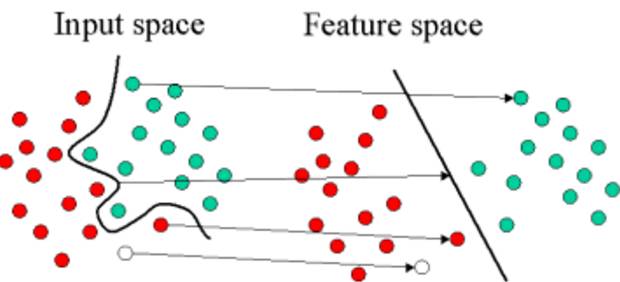
支持向量机中的核函数采用非线性变换,将非线性问题变换为线性问题
例如,SVM 使用线性核函数就能得到类似于 logistic 回归的结果,只不过支持向量机因为最大化了间隔而更具鲁棒性。因此,在实践中,SVM 最大的优点就是可以使用非线性核函数对非线性决策边界建模。
2.5 朴素贝叶斯
朴素贝叶斯(NB)是一种基于贝叶斯定理和特征条件独立假设的分类方法。本质上朴素贝叶斯模型就是一个概率表,其通过训练数据更新这张表中的概率。为了预测一个新的观察值,朴素贝叶斯算法就是根据样本的特征值在概率表中寻找最大概率的那个类别。
之所以称之为「朴素」,是因为该算法的核心就是特征条件独立性假设(每一个特征之间相互独立),而这一假设在现实世界中基本是不现实的。
3、聚类
聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。使用案例包括细分客户、新闻聚类、文章推荐等。
因为聚类是一种无监督学习(即数据没有标注),并且通常使用数据可视化评价结果。如果存在「正确的回答」(即在训练集中存在预标注的集群),那么分类算法可能更加合适。
3.1 K 均值聚类
K 均值聚类是一种通用目的的算法,聚类的度量基于样本点之间的几何距离(即在坐标平面中的距离)。集群是围绕在聚类中心的族群,而集群呈现出类球状并具有相似的大小。聚类算法是我们推荐给初学者的算法,因为该算法不仅十分简单,而且还足够灵活以面对大多数问题都能给出合理的结果。
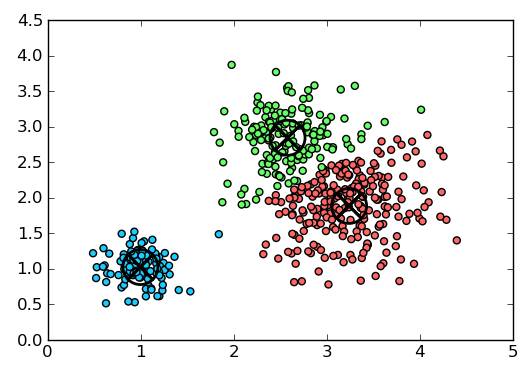
3.2 Affinity Propagation 聚类
AP 聚类算法是一种相对较新的聚类算法,该聚类算法基于两个样本点之间的图形距离(graph distances)确定集群。采用该聚类方法的集群拥有更小和不相等的大小。
3.3 层次聚类(Hierarchical / Agglomerative)
层次聚类是一系列基于以下概念的聚类算法:
-
最开始由一个数据点作为一个集群










