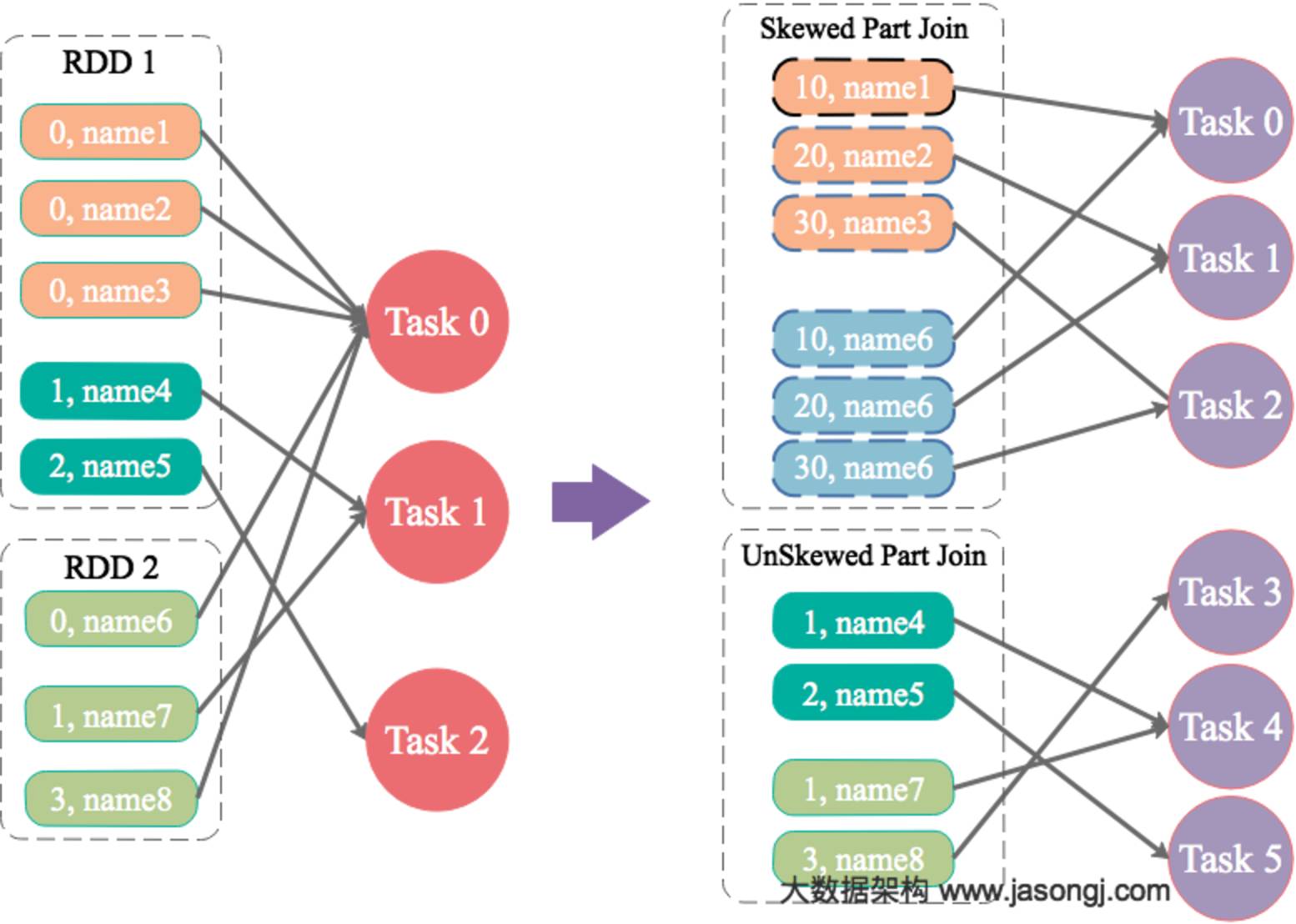
原理
为数据量特别大的Key增加随机前/后缀,使得原来Key相同的数据变为Key不相同的数据,从而使倾斜的数据集分散到不同的Task中,彻底解决数据倾斜问题。Join另一则的数据中,与倾斜Key对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常Join。
案例
通过如下SQL,将id为9亿到9.08亿共800万条数据的id转为9500048或者9500096,其它数据的id除以100取整。从而该数据集中,id为9500048和9500096的数据各400万,其它id对应的数据记录数均为100条。这些数据存于名为test的表中。
对于另外一张小表test_new,取出50万条数据,并将id(递增且唯一)除以100取整,使得所有id都对应100条数据。
INSERT OVERWRITE TABLE test
SELECT CAST(CASE WHEN id < 908000000 THEN (9500000 + (CAST (RAND() * 2 AS INT) + 1) * 48 )
ELSE CAST(id/100 AS INT) END AS STRING),
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
INSERT OVERWRITE TABLE test_new
SELECT CAST(CAST(id/100 AS INT) AS STRING),
name
FROM student_delta_external
WHERE id BETWEEN 950000000 AND 950500000;
通过如下代码(具体代码请点击“阅读原文”),读取test表对应的文件夹内的数据并转换为JavaPairRDD存于leftRDD中,同样读取test表对应的数据存于rightRDD中。通过RDD的join算子对leftRDD与rightRDD进行Join,并指定并行度为48。

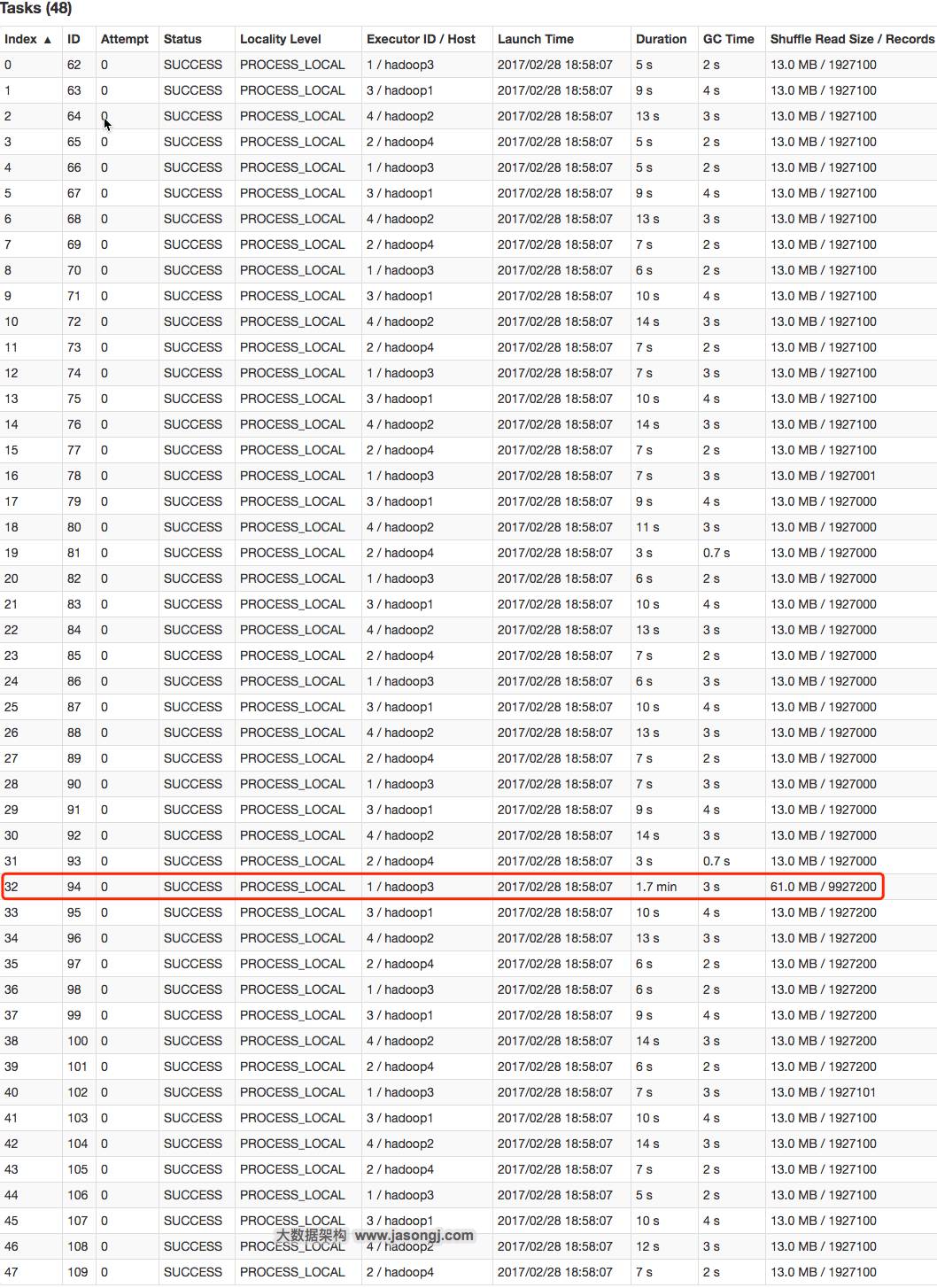
从下图可看出,整个Join耗时1分54秒,其中Join Stage耗时1.7分钟。

通过分析Join Stage的所有Task可知,在其它Task所处理记录数为192.71万的同时Task 32的处理的记录数为992.72万,故它耗时为1.7分钟,远高于其它Task的约10秒。这与上文准备数据集时,将id为9500048为9500096对应的数据量设置非常大,其它id对应的数据集非常均匀相符合。
现通过如下操作,实现倾斜Key的分散处理
-
将leftRDD中倾斜的key(即9500048与9500096)对应的数据单独过滤出来,且加上1到24的随机前缀,并将前缀与原数据用逗号分隔(以方便之后去掉前缀)形成单独的leftSkewRDD
-
将rightRDD中倾斜key对应的数据抽取出来,并通过flatMap操作将该数据集中每条数据均转换为24条数据(每条分别加上1到24的随机前缀),形成单独的rightSkewRDD
-
将leftSkewRDD与rightSkewRDD进行Join,并将并行度设置为48,且在Join过程中将随机前缀去掉,得到倾斜数据集的Join结果skewedJoinRDD
-
将leftRDD中不包含倾斜Key的数据抽取出来作为单独的leftUnSkewRDD
-
对leftUnSkewRDD与原始的rightRDD进行Join,并行度也设置为48,得到Join结果unskewedJoinRDD
-
通过union算子将skewedJoinRDD与unskewedJoinRDD进行合并,从而得到完整的Join结果集
具体实现代码如下。(具体代码请点击“阅读原文”)

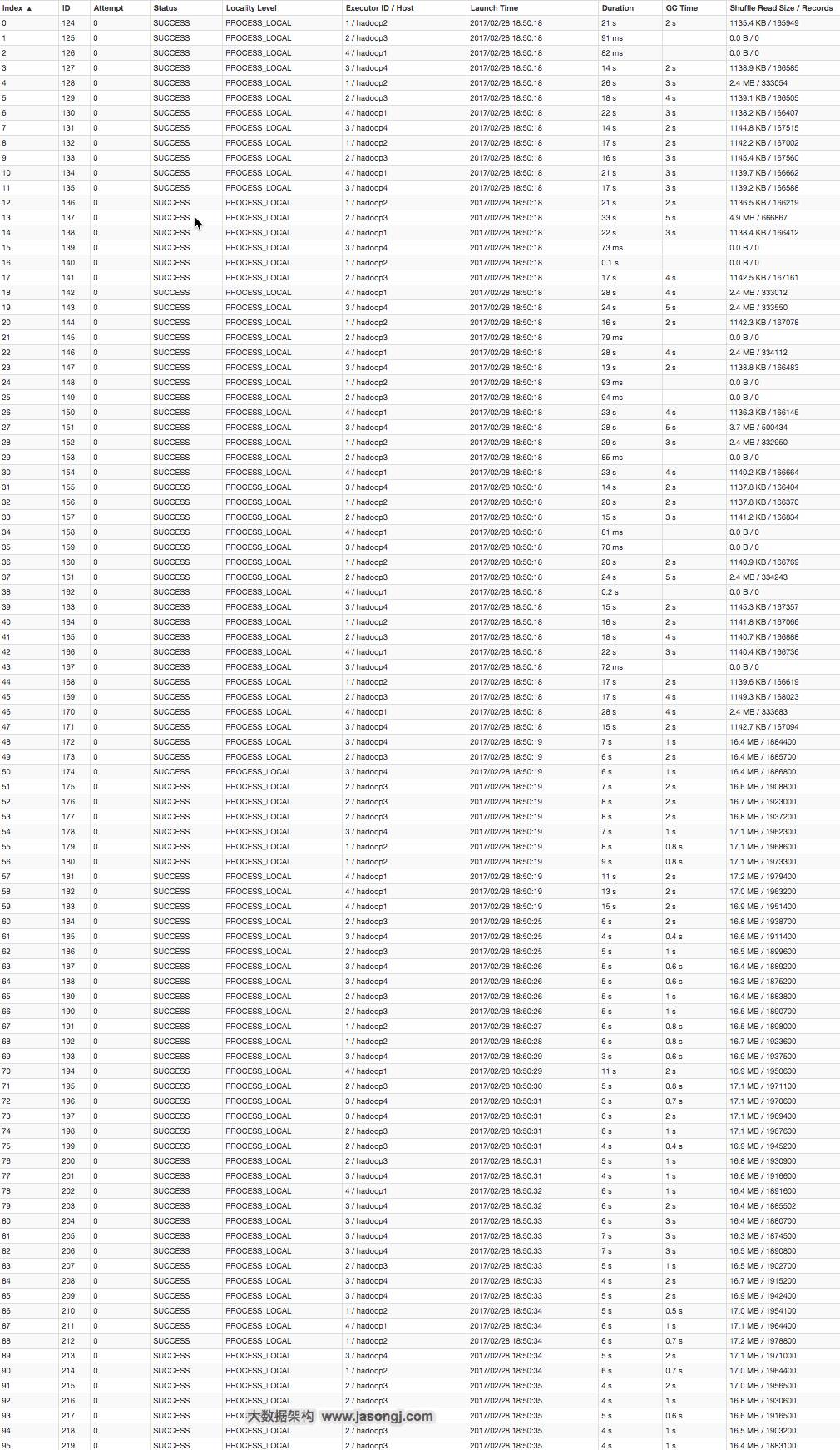
从下图可看出,整个Join耗时58秒,其中Join Stage耗时33秒。

通过分析Join Stage的所有Task可知
-
由于Join分倾斜数据集Join和非倾斜数据集Join,而各Join的并行度均为48,故总的并行度为96
-
由于提交任务时,设置的Executor个数为4,每个Executor的core数为12,故可用Core数为48,所以前48个Task同时启动(其Launch时间相同),后48个Task的启动时间各不相同(等待前面的Task结束才开始)
-
由于倾斜Key被加上随机前缀,原本相同的Key变为不同的Key,被分散到不同的Task处理,故在所有Task中,未发现所处理数据集明显高于其它Task的情况
实际上,由于倾斜Key与非倾斜Key的操作完全独立,可并行进行。而本实验受限于可用总核数为48,可同时运行的总Task数为48,故而该方案只是将总耗时减少一半(效率提升一倍)。如果资源充足,可并发执行Task数增多,该方案的优势将更为明显。在实际项目中,该方案往往可提升数倍至10倍的效率。
总结
适用场景
两张表都比较大,无法使用Map则Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
解决方案
将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join并去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
优势
相对于Map则Join,更能适应大数据集的Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
劣势










