(点击上方公众号,可快速关注)
来源:lyg945
链接:my.oschina.net/liuyonggang/blog/790950
redis主从复制过程
当配置好slave后,slave与master建立连接,然后发送sync命令。无论是第一次连接还是重新连接,master都会启动一个后台进程,将 数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存。后台进程完成写文件后,master就发送文件给slave,slave将 文件保存到硬盘上,再加载到内存中,接着master就会把缓存的命令转发给slave,后续master将收到的写命令发送给slave。
如果master同时收到多个slave发来的同步连接命令,master只会启动一个进程来写数据库镜像,然后发送给所有的slave。master同步数据时是非阻塞式的,可以接收用户的读写请求。然而在slave端是阻塞模式的,slave在同步master数据时,并不能够响应客户端的查询。
可以在master禁用数据持久化,只需要注释掉master 配置文件中的所有save配置,然后只在slave上配置数据持久化
拥有主从服务器的好处(从服务器是只读的,可以一主多从)
1. 主服务器进行读写时,会转移到从读,减轻服务器压力
2. 热备份 主从都可以设置密码,也可以密码不一致
进入/usr/data/redis/slave
创建 master slave1 slave2
1.复制redis.conf到3个目录,修改端口 1000,2000,3000
2.修改pid路径,日志路径
pidfile /usr/data/redis/slave/master/redis.pid
logfile /usr/data/redis/slave/master/redis.log
ps -ef | grep redis
root 19000 1 0 08:27 ? 00:00:00 redis-server 192.168.1.1:1000
root 19012 1 0 08:27 ? 00:00:00 redis-server 192.168.1.1:2000
root 19016 1 0 08:27 ? 00:00:00 redis-server 192.168.1.1:3000
连接客户端
[root@iZ23pv5rps8Z ~]# redis-cli -h 192.168.1.1 -p 3000
查看权限
192.168.1.1:3000> info
3台服务器都是 # Replication role:master
设置从服务器方式
1.命令方式
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.1.1,port=2000,state=online,offset=113,lag=0
slave1:ip=192.168.1.1,port=3000,state=online,offset=113,lag=0
master_repl_offset:113
# Replication
role:slave
master_host:192.168.1.1
master_port:1000
master_link_status:up
服务器停止,主从就不起作用
2.配置文件
# slaveof
slaveof 192.168.1.1 1000
服务器停止,主从依然起作用
主从同步,2者密码可以不一致
192.168.1.1:1000> set lyg945 liuyonggang
192.168.1.1:1000> get lyg945
"liuyonggang"
192.168.1.1:2000> get lyg945
"liuyonggang"
192.168.1.1:3000> get lyg945
"liuyonggang"
Redis的主从架构,如果master发现故障了,还得手动将slave切换成master继续服务,手动的方式容易造成失误,导致数据丢失,那Redis有没有一种机制可以在master和slave进行监控,并在master发送故障的时候,能自动将slave切换成master呢?有的,那就是哨兵。
哨兵的作用:
1、监控redis进行状态,包括master和slave
2、当master down机,能自动将slave切换成master
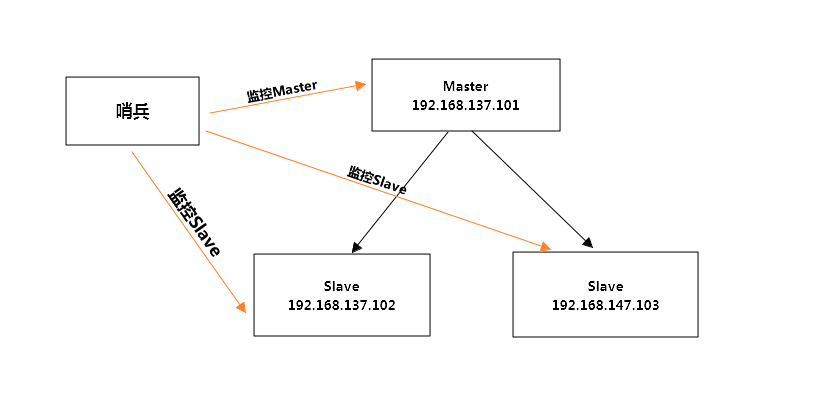
下面配置哨兵监控redis进程,假如我们已经配置好了Master和Slave,具体详细配置参
手动切换master
master SLAVEOF NO ONE
slave SLAVEOF 192.168.1.1 3000
创建哨兵
touch sentinel.conf 内容如下
sentinel monitor 主机名 主机ip 主机端口 票数n 票数多余n的从机作为主机
sentinel monitor mymaster 192.168.1.1 1000 1
启动哨兵
redis-sentinel sentinel.conf

20526:X 20 Nov 13:24:29.243 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
20526:X 20 Nov 13:24:29.303 # Sentinel ID is 5d351f7edc80148f60036a6c0c2e74510ece4221
20526:X 20 Nov 13:24:29.303 # +monitor master mymaster 192.168.1.1 1000 quorum 1
20526:X 20 Nov 13:24:29.304 * +slave slave 192.168.1.1:2000 192.168.1.1 2000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:24:29.317 * +slave slave 192.168.1.1:3000 192.168.1.1 3000 @ mymaster 192.168.1.1 1000
将3000 kill掉
redis-cli -h 192.168.1.1 -p 3000
Could not connect to Redis at 192.168.1.1:3000: Connection refused
Could not connect to Redis at 192.168.1.1:3000: Connection refused
192.168.1.1:1000> set zhangsan 1
192.168.1.1:1000> get zhangsan
"1"
192.168.1.1:2000> get zhangsan
"1"
3000重启
192.168.1.1:3000> get zhangsan
"1"
2.将master(1000) kill掉
redis-cli -h 192.168.1.1 -p 1000
Could not connect to Redis at 192.168.1.1:1000: Connection refused
查看哨兵后台打印信息
20526:X 20 Nov 13:27:40.550 # +sdown master mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.550 # +odown master mymaster 192.168.1.1 1000 #quorum 1/1
20526:X 20 Nov 13:27:40.550 # +new-epoch 1
20526:X 20 Nov 13:27:40.550 # +try-failover master mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.559 # +vote-for-leader 5d351f7edc80148f60036a6c0c2e74510ece4221 1
20526:X 20 Nov 13:27:40.559 # +elected-leader master mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.559 # +failover-state-select-slave master mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.612 # +selected-slave slave 192.168.1.1:2000 192.168.1.1 2000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.612 * +failover-state-send-slaveof-noone slave 192.168.1.1:2000 192.168.1.1 2000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.688 * +failover-state-wait-promotion slave 192.168.1.1:2000 192.168.1.1 2000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.766 # +promoted-slave slave 192.168.1.1:2000 192.168.1.1 2000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.766 # +failover-state-reconf-slaves master mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:40.818 * +slave-reconf-sent slave 192.168.1.1:3000 192.168.1.1 3000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:41.813 * +slave-reconf-inprog slave 192.168.1.1:3000 192.168.1.1 3000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:41.813 * +slave-reconf-done slave 192.168.1.1:3000 192.168.1.1 3000 @ mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:41.896 # +failover-end master mymaster 192.168.1.1 1000
20526:X 20 Nov 13:27:41.896 # +switch-master mymaster 192.168.1.1 1000 192.168.1.1 2000
20526:X 20 Nov 13:27:41.896 * +slave slave 192.168.1.1:3000 192.168.1.1 3000 @ mymaster 192.168.1.1 2000
20526:X 20 Nov 13:27:41.896 * +slave slave 192.168.1.1:1000 192.168.1.1 1000 @ mymaster 192.168.1.1 2000
20526:X 20 Nov 13:28:11.907 # +sdown slave 192.168.1.1:1000 192.168.1.1 1000 @ mymaster 192.168.1.1 2000
192.168.1.1:2000> info 变成了主
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.1.1,port=3000,state=online,offset=1625,lag=0
192.168.1.1:2000> set aa 11
OK
192.168.1.1:2000> get aa
“11”
192.168.1.1:3000> info 还是从
# Replication
role:slave
master_host:192.168.1.1
master_port:2000
master_link_status:up
192.168.1.1:3000> get aa
“11”
重启1000原来的master服务器
查看哨兵
20526:X 20 Nov 13:42:51.554 # -sdown slave 192.168.1.1:1000 192.168.1.1 1000 @ mymaster 192.168.1.1 2000
20526:X 20 Nov 13:43:01.604 * +convert-to-slave slave 192.168.1.1:1000 192.168.1.1 1000 @ mymaster 192.168.1.1 2000
192.168.1.1:1000> info 变成从
# Replication
role:slave
master_host:192.168.1.1
master_port:2000
master_link_status:up
192.168.1.1:1000> get aa
“11”
Redis-sentinel高可用
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现master宕机后能进行自动切换。
它的主要功能有以下几点
不时地监控redis是否按照预期良好地运行;
如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端);
能够进行自动切换。当一个master节点不可用时,能够选举出master的多个slave(如果有超过一个slave的话)中的一个来作为新的master,其它的slave节点会将它所追随的master的地址改为被提升为master的slave的新地址。
需要注意的是,配置文件在sentinel运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的master会被修改为另外一个slave。这样,之后sentinel如果重启时,就可以根据这个配置来恢复其之前所监控的redis集群的状态。
sentinel monitor mymaster 192.168.1.1 1000 1
sentinel down-after-milliseconds mymaster 60000
#sentinel can-failover mymaster yes
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
当sentinel集群式,解决这个问题的方法就变得很简单,只需要多个sentinel互相沟通来确认某个master是否真的死了,这个2代表,当集群中有2个sentinel认为master死了时,才能真正认为该master已经不可用了。
down-after-milliseconds
sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒。
can-failover
no 表示当前sentinel是一个观察者,只参与投票不参与实施failover
全局中至少有一个是yes
parallel-syncs
当新master产生时,同时进行“slaveof”到新master并进行“SYNC”的slave个数
默认为1,建议保持默认值
在salve执行salveof与同步时,将会终止客户端请求
failover-timeout
failover过期时间,当failover开始后,在此时间内仍然没有触发任何failover操作
当前sentinel将会认为此次failoer失败
关注「数据库开发」
看更多精选数据库技术文章
↓↓↓











