问题导读
1.什么是Kubernetes?
2.在Kubernetes集群尝试新功能,该如何实现?
3.观看群集上创建的Spark资源,该如何操作?
在开始之前我们需要知道
什么是Kubernetes
Kubernetes(通常写成“k8s”)是最开始由google设计开发最后贡献给Cloud Native Computing Foundation的开源容器集群管理项目。它的设计目标是在主机集群之间提供一个能够自动化部署、可拓展、应用容器可运营的平台。Kubernetes通常结合docker容器工具工作,并且整合多个运行着docker容器的主机集群。
介绍
开源社区在过去一年中一直致力于为Kubernetes的数据处理,数据分析和机器学习工作负载提供支持。 Kubernetes中的新扩展功能(如自定义资源和自定义控制器)可用于创建与各个应用程序和框架的深度集成。
传统上,数据处理工作负载已经在像YARN / Hadoop堆栈这样的专用设置中运行。 但是,统一Kubernetes上所有工作负载的控制层可以简化群集管理并提高资源利用率。
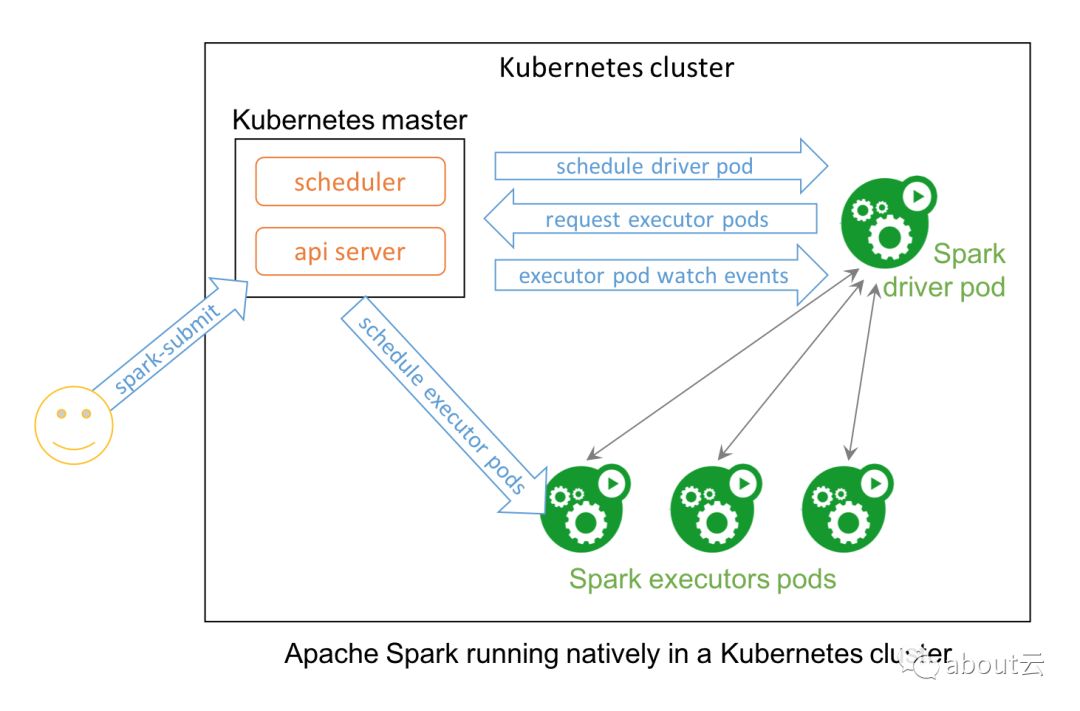
带有原生Kubernetes支持的Apache Spark 2.3结合了两个着名的开源项目中, large-scale 数据处理框架; 和Kubernetes。
Apache Spark是数据科学家必不可少的工具,为从大规模数据转换到分析到机器学习的各种应用提供强大的平台。 数据科学家们一致采用容器,通过实现诸如依赖性打包和创建可重现的构件等好处来改进其工作流程。 考虑到Kubernetes是管理集装箱环境的事实标准,在Spark中支持Kubernetes API是非常合适的。
具体而言,Kubernetes中的本地Spark应用程序充当自定义控制器,该应用程序创建Kubernetes资源以响应Spark调度程序发出的请求。 与在Kubernetes中以独立模式部署Apache Spark相反,本地方法提供了对Spark应用程序的精细管理,提高了弹性,并与日志记录和监视解决方案无缝集成。 该社区还在探索高级用例,如管理流式工作负载和利用Istio等服务网格。
要在Kubernetes集群上自己尝试,只需下载官方Apache Spark 2.3发行版的二进制文件即可。 例如,下面我们描述运行一个简单的Spark应用程序来计算三个Spark执行程序之间的数学常量Pi,每个执行程序在一个单独的窗格中运行。 请注意,这需要运行Kubernetes 1.7或更高版本的集群,配置为访问它的kubectl客户端,以及缺省命名空间和服务帐户所需的RBAC规则。
[Bash shell]
纯文本查看
复制代码
?
|
01
02
03
04
05
06
07
08
09
10
11
12
|
$ kubectl cluster-info
Kubernetes master is running at https:
//xx
.yy.zz.ww
$ bin
/spark-submit
\
--master k8s:
//https
:
//xx
.yy.zz.ww \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
|





