基础组件之间的关系
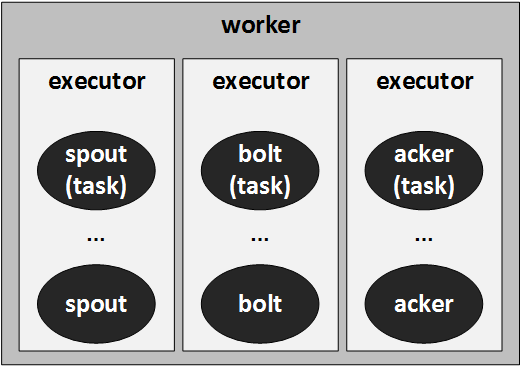
这里做一些补充:
1. worker是一个进程,由supervisor启动,并只负责处理一个topology,所以不会同时处理多个topology.
2. executor是一个线程,由worker启动,是运行task的物理容器,其和task是1 -> N关系.
3. component是对spout/bolt/acker的抽象.
4. task也是对spout/bolt/acker的抽象,不过是计算了并行度之后。component和task是1 -> N 的关系.
supervisor会定时从zookeeper获取topologies、已分配的任务分配信息assignments及各类心跳信息,以此为依据进行任务分配。
在supervisor周期性地进行同步时,会根据新的任务分配来启动新的worker或者关闭旧的worker,以响应任务分配和负载均衡。
worker通过定期的更新connections信息,来获知其应该通讯的其它worker。
worker启动时,会根据其分配到的任务启动一个或多个executor线程。这些线程仅会处理唯一的topology。
executor线程负责处理多个spouts或者多个bolts的逻辑,这些spouts或者bolts,也称为tasks。
并行度的计算
相关配置及参数的意义
具体有多少个worker,多少个executor,每个executor负责多少个task,是由配置和指定的parallelism-hint共同决定的,但指定的并行度并不一定等于实际运行中的数目。
1、TOPOLOGY-WORKERS参数指定了某个topology运行时需启动的worker数目
2、parallelism-hint指定某个component(组件,如spout)的初始executor的数目
3、TOPOLOGY-TASKS是component的tasks数,计算稍微复杂点:
(1) 如果未指定TOPOLOGY-TASKS,此值等于初始executors数.
(2) 如果已指定,和TOPOLOGY-MAX-TASK-PARALLELISM值进行比较,取小的那个作为实际的TOPOLOGY-TASKS.
用代码来表达就是:
(defn- component-parallelism [storm-conf component]
(let [storm-conf (merge storm-conf (component-conf component))
num-tasks (or (storm-conf TOPOLOGY-TASKS) (num-start-executors component))
max-parallelism (storm-conf TOPOLOGY-MAX-TASK-PARALLELISM)
]
(if max-parallelism
(min max-parallelism num-tasks)
num-tasks)))
4、对于acker这种特殊的bolt来说,其并行度计算如下:
(1) 如果指定了TOPOLOGY-ACKER-EXECUTORS,按这个值计算.
(2) 如果未指定,那么按TOPOLOGY-WORKERS的值来设置并行度,这种情况下,一个acker对应一个worker,显然,在计算任务繁重、数据量比较大的情况下,这是不合适的。
5、如果配置了NIMBUS-SLOTS-PER-TOPOLOGY,在提交topology到nimbus时,会验证topology所需的worker总数,如果超过了这个值,说明不能够满足需求,则抛出异常。
6、如果配置了NIMBUS-EXECUTORS-PER-TOPOLOGY,如第5点,会验证topology所需的executor总数,如果超出,也会抛出异常。
同时,需要注意,实际运行中,有可能出现并行的TASKS数小于指定的数量。
通过调用nimbus接口的rebalance或者do-rebalance操作,以上并行度可被动态改变。
并行度计算在任务分配中的体现
先回顾下任务分配中的几个主要角色:

接着看几段重要的并行度计算代码:
1、计算所有topology的topology-id到executors的映射关系:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; 计算所有tolopogy的topology-id到executors的映射
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn- compute-topology->executors [nimbus storm-ids]
"compute a topology-id -> executors map"
(into {} (for [tid storm-ids]
{tid (set (compute-executors nimbus tid))})))
2、计算topology-id到executors的映射信息:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; 计算topology-id到executors的映射
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn- compute-executors [nimbus storm-id]
(let [conf (:conf nimbus)
storm-base (.storm-base (:storm-cluster-state nimbus) storm-id nil)
component->executors (:component->executors storm-base)
storm-conf (read-storm-conf conf storm-id)
topology (read-storm-topology conf storm-id)
task->component (storm-task-info topology storm-conf)]
(->> (storm-task-info topology storm-conf)
reverse-map
(map-val sort)
(join-maps component->executors)
(map-val (partial apply partition-fixed))
(mapcat second)
(map to-executor-id)
)))
3、计算topology的任务信息 task-info,这里TOPOLOGY-TASKS就决定了每个组件component(spout、bolt)的并行度,或者说tasks数:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; 计算topology的task-info
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(defn storm-task-info
"Returns map from task -> component id"
[^StormTopology user-topology storm-conf]
(->> (system-topology! storm-conf user-topology)
all-components
;; 获取每个组件的并行数
(map-val (comp #(get % TOPOLOGY-TASKS) component-conf))
(sort-by first)
(mapcat (fn [[c num-tasks]] (repeat num-tasks c)))
(map (fn [id comp] [id comp]) (iterate (comp int inc) (int 1)))
(into {})
))
4、上述1、2、3段代码会在nimbus进行任务分配时调用,任务分配是通过mk-assignments函数来完成,调用过程用伪代码描述如下:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; nimbus进行任务分配
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
mk-assignments
;; 这一步计算topology的所有executor对应的node + port信息
->compute-new-topology->executor->node+port
->compute-topology->executors
-> ...
nimbus进行任务分配
这里回顾并补充下nimbus进行任务分配的主要流程:
任务分配的流程
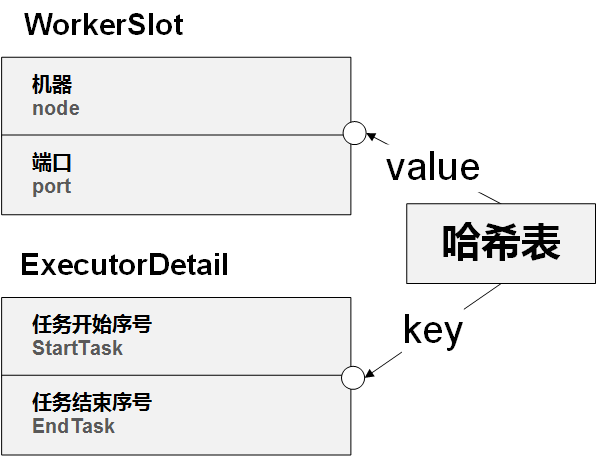
1、nimbus将一组node + port 称为worker-slot,由executor到worker-slot的映射信息,就决定executor将在哪台机器、哪个worker进程运行,随之spout、bolt、acker等位置也就确定了,如下图所示:
2、 nimbus是整个集群的控管核心,总体负责了topology的提交、运行状态监控、负载均衡及任务分配等工作。
3、nimbus分配的任务包含了topology代码所在的路径(在nimbus本地)、tasks、executors及workers信息。worker由node + port及配置的worker数量来唯一确定。
任务信息Assignment结构如下:

4、supervisor负责实际的同步worker的操作。一个supervisor称为一个node。所谓同步worker,是指响应nimbus的任务分配,进行worker的建立、调度与销毁。
在收到任务时,如果相关的topology代码不在本地,supervisor会从nimbus下载代码并写入本地文件。
5、
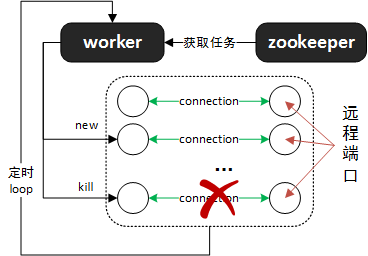
通过node、port、host信息的计算,worker就知道和哪些机器进行通讯,而当负载均衡发生、任务被重新分配时,这些机器可能发生了变化,worker会通过周期性的调用refresh-connections来获知变化,并进行新连接的建立、废弃连接的销毁等工作,如下图所示:
任务分配的依据
supervisor、worker、executor等组件的心跳信息会同步至zookeeper,nimbus会周期性地获取这些信息,结合已分配的任务信息assignments、集群现有的topologies(已运行+未运行)等等信息,来进行任务分配,如下图所示:

任务分配的时机
1、通过rebalance和do-reblalance(比如来自web调用)触发负载均衡,会触发mk-assignments即任务分配。
2、同时,nimbus进程启动后,会周期性地进行任务分配。
3、客户端通过 storm jar ... topology 方式提交topology,会通过thrift调用nimbus接口,提交topology,启动新storm实例,并触发任务分配。
负载均衡
负载均衡和任务分配是连在一起的,或者说任务分配中所用到的关键信息是由负载均衡来主导计算的,上文已经分析了任务分配的主要角色和流程,那么负载均衡理解起来就很容易了,流程和框架如下图所示:

其中,负载均衡部分的策略可采用平均分配、机器隔离或topology隔离后再分配、Round-Robin等等,因为主要讨论storm的基础框架,而具体的负载均衡策略各家都不一样,而且这个策略是完全可以自定义的,比如可以将机器的实际能力如CPU、磁盘、内存、网络等等资源抽象为一个一个的资源slot,以此slot为单位进行分配,等等。
这里就不深入展开了。
通过负载均衡得出了新的任务分配信息assignments,nimbus再进行一些转换计算,就会将信息同步到zookeeper上,supervisor就可以根据这些信息来同步worker了。
结语
本篇作为对上篇的补充和完善。
也完整地回答了这个问题:
在Topology中我们可以指定spout、bolt的并行度,在提交Topology时Storm如何将spout、bolt自动发布到每个服务器并且控制服务的CPU、磁盘等资源的?
终。
相关阅读
storm的基础框架分析:http://www.cnblogs.com/foreach-break/p/storm_worker_executor_spout_bolt_simbus_supervisor_mk-assignments.html
出处:http://www.cnblogs.com/foreach-break/p/how-does-storm-mk-assignments-and-do-rebanlance.html#_9
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文










